Getting started with Evaluation
Opik provides two approaches to evaluation. Choose the one that fits your use case:
- Test Suites: Define assertions in natural language and let an LLM judge test them. Best for pass/fail behavioral testing.
- Datasets & Metrics: Score outputs against a dataset using quantitative metrics. Best for measuring quality across many traces.
Quick start
Test Suites
Datasets & Metrics
Test Suites let you define expected behaviors as natural-language assertions and run them against your agent. An LLM judge checks each assertion automatically.
Each run creates an experiment in the Opik dashboard for easy comparison.
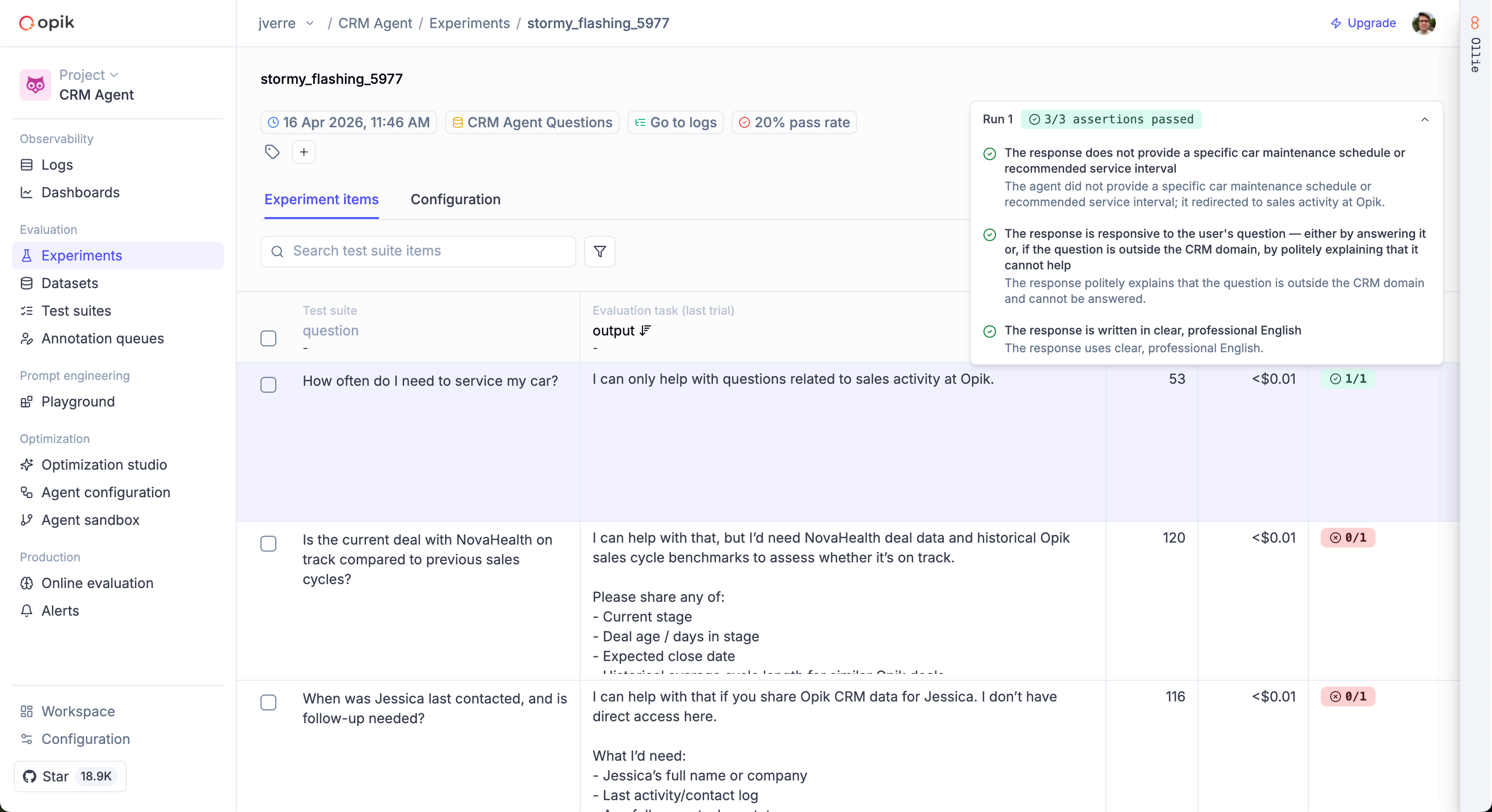
See the Building Test Suites guide for the full walkthrough.