Building Test Suites
Test suites grow as you debug and improve your agent. There are three ways to build them: with Ollie, through the UI, or via the SDK.
With Ollie
The fastest way to turn a production failure into a test case. Open Ollie from any trace view and describe what went wrong:
“Add this trace to my customer-support-qa suite with the assertion: the response must cite a specific step from the provided context”
Ollie creates the test item directly — no copy-pasting required. You can also ask Ollie to run the suite after making changes:
“Run the customer-support-qa suite against the updated prompt”
See Debugging agents for the full workflow.
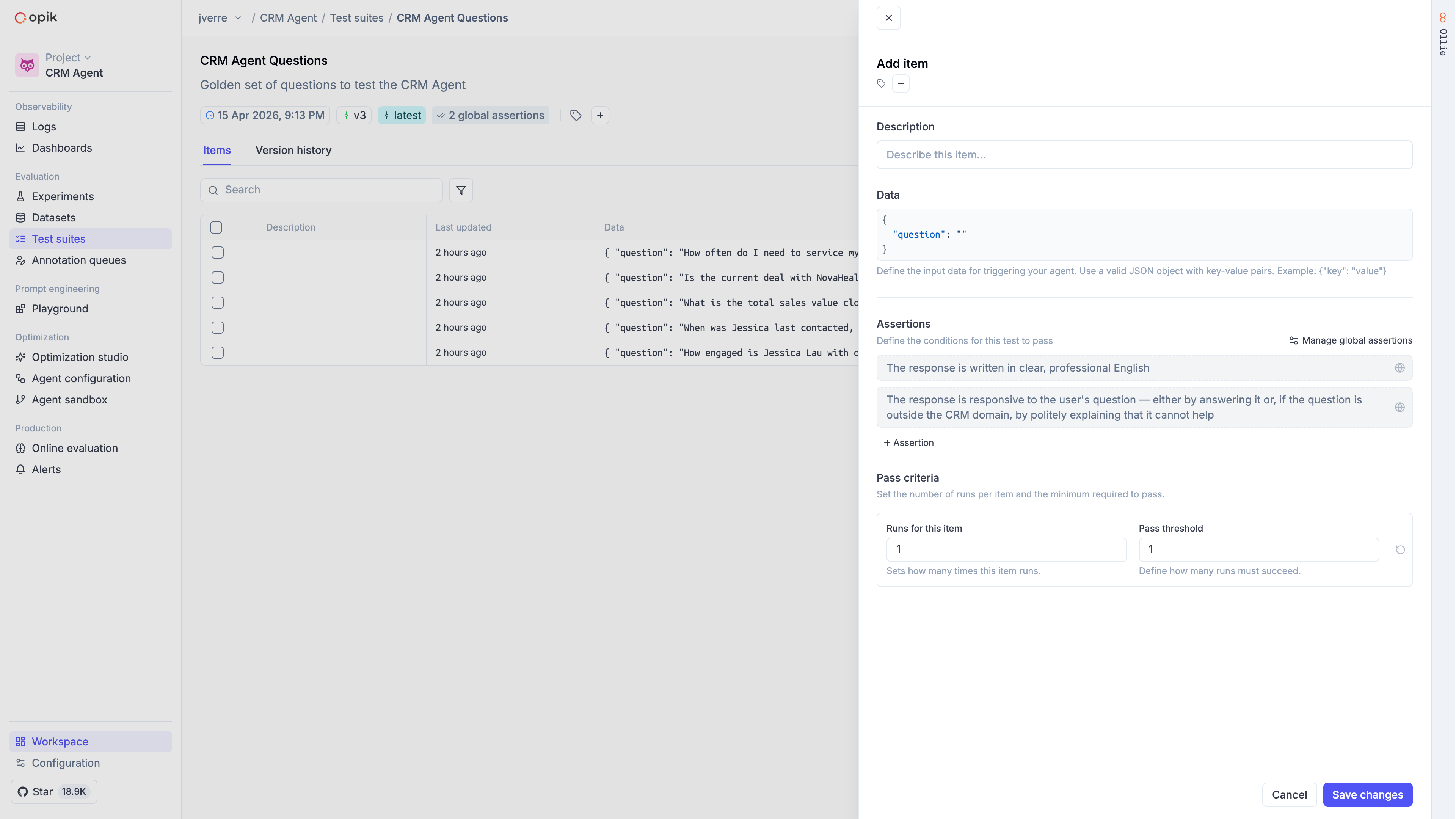
With the UI
In the Opik dashboard, navigate to the Test Suites section to create and manage suites visually. You can add test items, define assertions, configure execution policies, and review results — all without writing code.
With the SDK
Create a suite
Define the quality bars you care about as suite-level assertions:
Add test items
Add individual items or batches. Items can include item-level assertions that are checked in addition to the suite-level assertions:
Define the task and run
The task function receives each item’s data and must return an object with input and output keys:
Each run creates a separate experiment in Opik, making it easy to compare results in the dashboard.
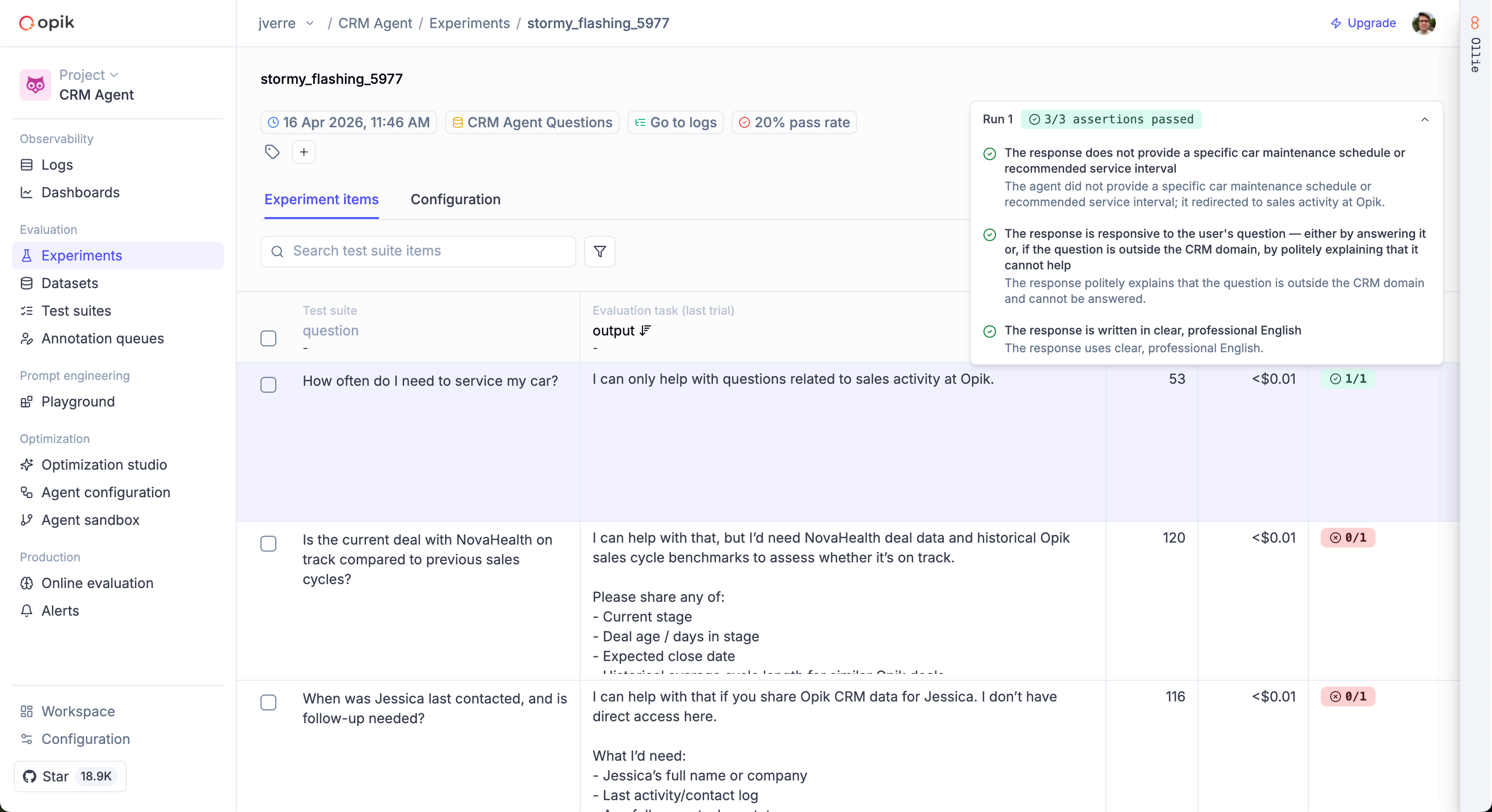
The input should contain only the data your agent actually received when generating its response.
The LLM judge uses input and output to evaluate assertions — if you accidentally include fields
like expected_answer in input, the judge may use them to pass assertions that should fail.
Update assertions and execution policy
Inspect suite contents
Delete test items
Execution policies
Execution policies control how many times each item is run and how many must pass. This is useful for handling non-deterministic LLM outputs.
Pass/fail logic:
- A run passes if all its assertions pass
- An item passes if
runs_passed >= pass_threshold - The pass rate is the ratio of passed items to total items. A pass rate of
1.0means every item passed;0.0means none did
You can also override the policy for individual items: