Here are the most relevant improvements we’ve made in the last couple of weeks:
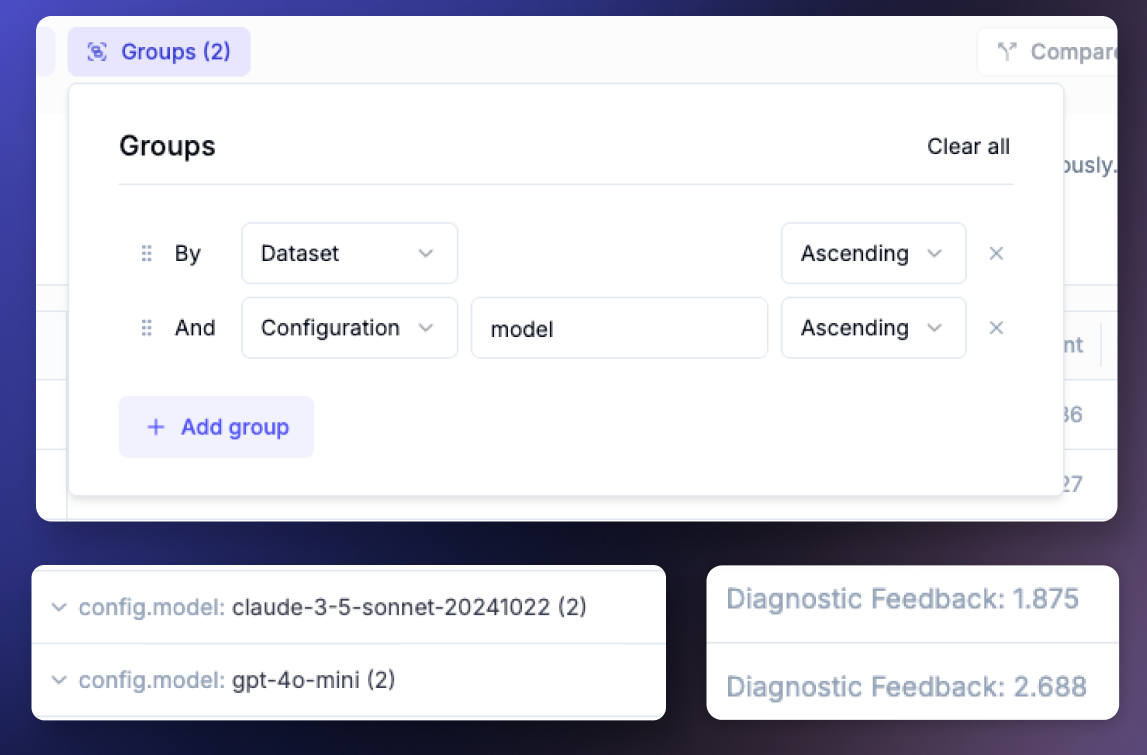
🧪 Experiment Grouping
Instantly organize and compare experiments by model, provider, or custom metadata to surface top performers, identify slow configurations, and discover winning parameter combinations. The new Group by feature provides aggregated statistics for each group, making it easier to analyze patterns across hundreds of experiments.
🤖 Expanded Model Support
Added support for 144+ new models, including:
- OpenAI’s GPT-5 and GPT-4.1-mini
- Anthropic Claude Opus 4.1
- Grok 4
- DeepSeek v3
- Qwen 3
🛫 Streamlined Onboarding
New quick start experience with AI-assisted installation, interactive setup guides, and instant access to team collaboration features and support.

🔌 Integrations
Enhanced support for leading AI frameworks including:
- LangChain: Improved token usage tracking functionality
- Bedrock: Comprehensive cost tracking for Bedrock models
🔍 Custom Trace Filters
Advanced filtering capabilities with support for list-like keys in trace and span filters, enabling precise data segmentation and analysis across your LLM operations.
⚡ Performance Optimizations
- Python scoring performance improvements with pre-warming
- Optimized ClickHouse async insert parameters
- Improved deduplication for spans and traces in batches
🛠️ SDK Improvements
- Python SDK configuration error handling improvements
- Added dataset & dataset item ID to evaluate task inputs
- Updated OpenTelemetry integration
And much more! 👉 See full commit log on GitHub
Releases: 1.8.16, 1.8.17, 1.8.18, 1.8.19, 1.8.20, 1.8.21, 1.8.22, 1.8.23, 1.8.24, 1.8.25, 1.8.26, 1.8.27, 1.8.28, 1.8.29, 1.8.30, 1.8.31, 1.8.32, 1.8.33