Here are the most relevant improvements we’ve made since the last release:
📊 More Metrics!
We have shipped 37 new built-in metrics, faster & more reliable LLM judging, plus robustness fixes.
New Metrics Added - We’ve expanded the evaluation metrics library with a comprehensive set of out-of-the-box metrics including:
- Classic NLP Heuristics - BERTScore, Sentiment analysis, Bias detection, Conversation drift, and more
- Lightweight Heuristics - Fast, non-LLM based metrics perfect for CI/CD pipelines and large-scale evaluations
- LLM-as-a-Judge Presets - More out-of-the-box presets you can use without custom configuration
LLM-as-a-Judge & G-Eval Improvements:
- Compatible with newer models - Now works seamlessly with the latest model versions
- Faster default judge - Default judge is now
gpt-5-nanofor faster, more accurate evals - LLM Jury support - Aggregate scores across multiple models/judges into a single ensemble score for more reliable evaluations
Enhanced Preprocessing:
- Improved English text handling - Better processing of English text to reduce false negatives
- Better emoji handling - Enhanced emoji processing for more accurate evaluations
Robustness Improvements:
- Automatic retries - LLM judge will retry on transient failures to avoid flaky test results
- More reliable evaluation runs - Faster, more consistent evaluation runs for CI and experiments
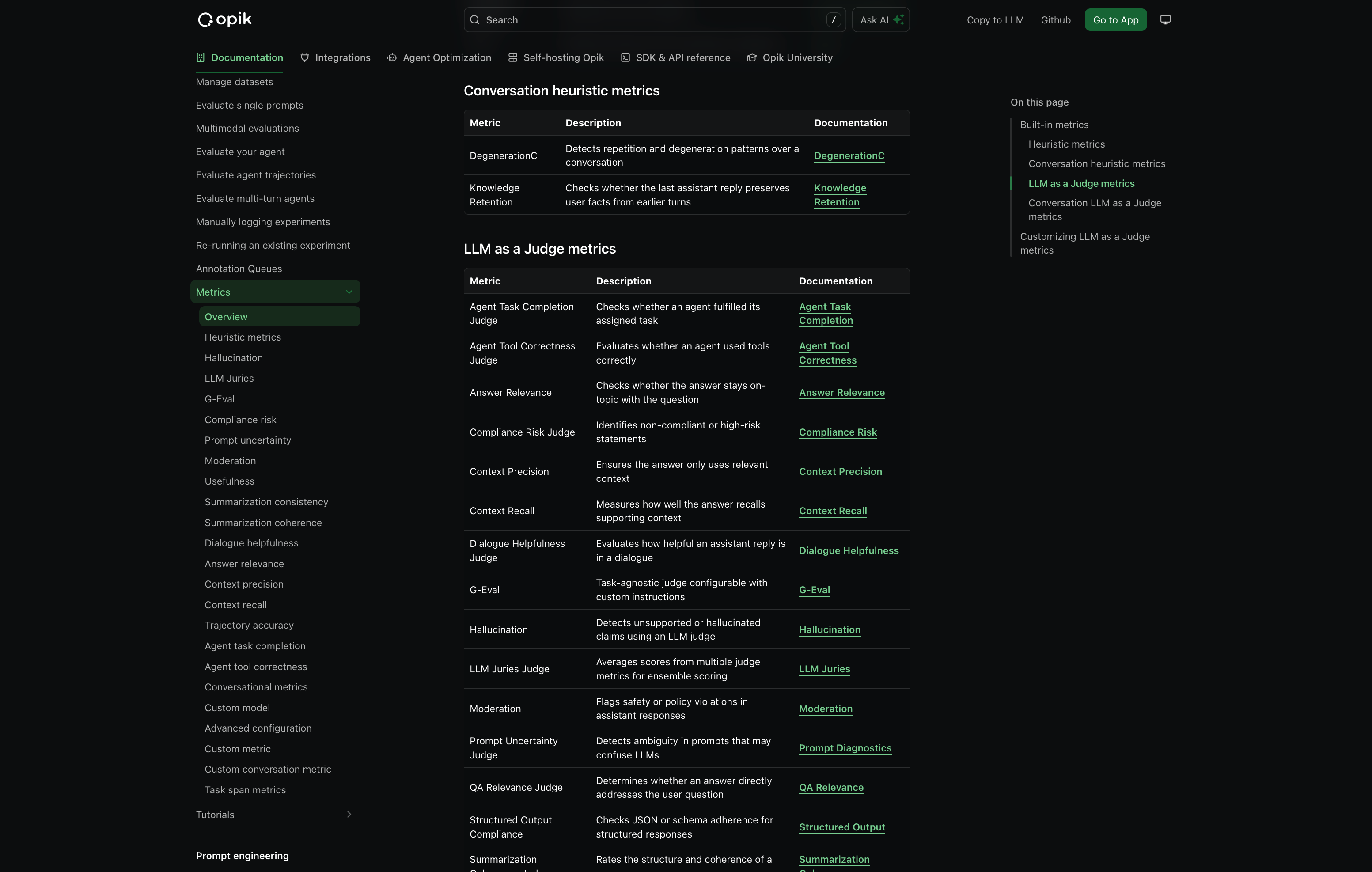
👉 Access the metrics docs here: Evaluation Metrics Overview
🔒 Anonymizers - PII Information Redaction
We’ve added support for PII (Personally Identifiable Information) redaction before sending data to Opik. This helps you protect sensitive information while still getting the observability insights you need.
With anonymizers, you can:
- Automatically redact PII from traces and spans before they’re sent to Opik
- Configure custom anonymization rules to match your specific privacy requirements
- Maintain compliance with data protection regulations
- Protect sensitive data without losing observability
👉 Read the full docs: Anonymizers
🚨 New Alert Types
We’ve expanded our alerting capabilities with new alert types and improved functionality:
- Experiment Finished Alert - Get notified when an experiment completes, so you can review results immediately or trigger your CI/CD pipelines.
- Cost Alerts - Set thresholds for cost metrics and receive alerts when spending exceeds your limits
- Latency Alerts - Monitor response times and get notified when latency exceeds configured thresholds
These new alert types help you stay on top of your LLM application’s performance and costs, enabling proactive monitoring and faster response to issues.
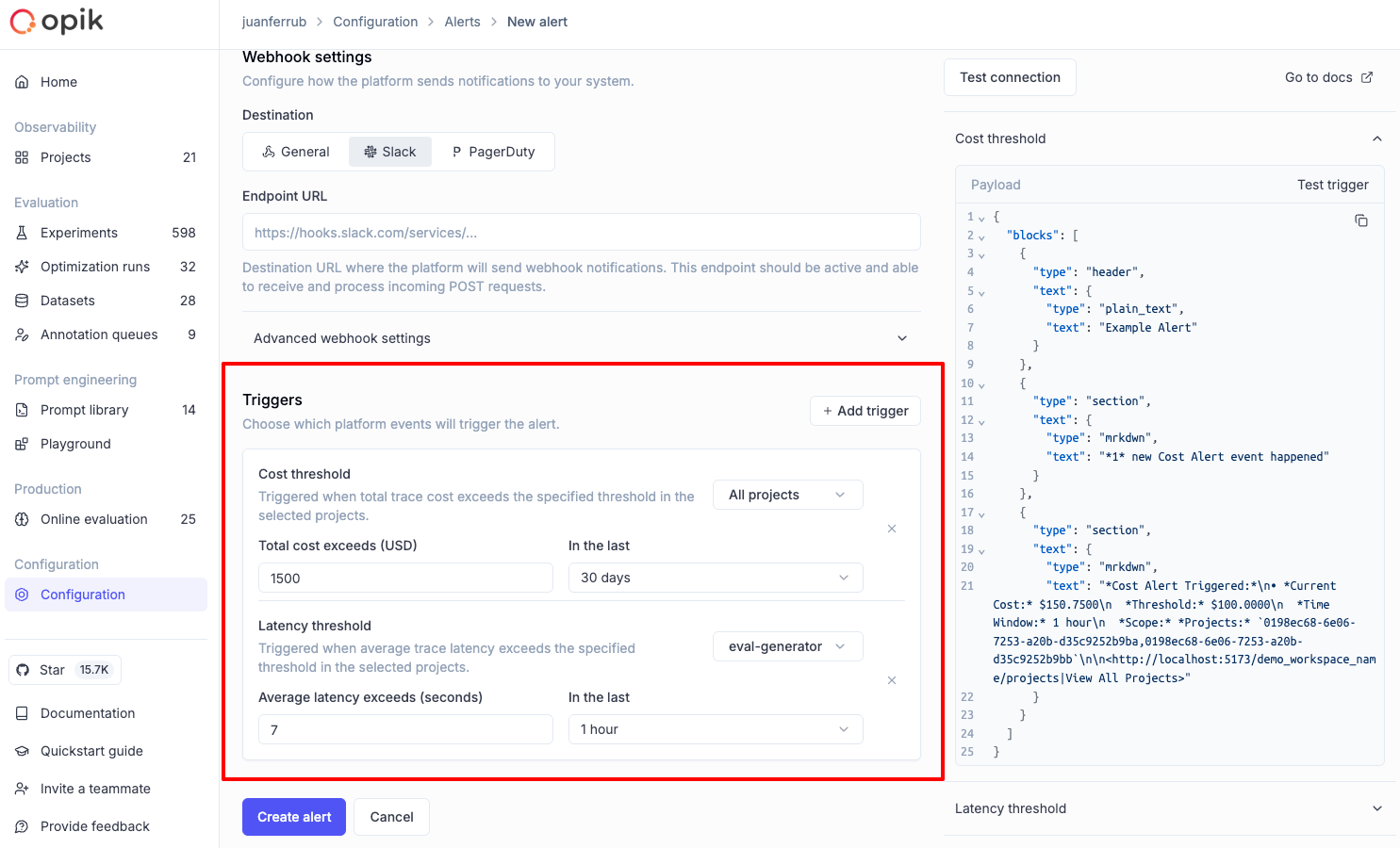
👉 Read more: Alerts Guide
🎥 Multimodal Support
We’ve significantly enhanced multimodal capabilities across the platform:
-
Video LLM-as-a-Judge - Added support for Video LLM-as-a-Judge, enabling evaluation of video content in your traces
-
Video Cost Tracking - Added cost tracking for video models, so you can monitor spending on video processing operations
-
Image support in LLM-as-a-Judge - Both Python and TypeScript SDKs now support image processing in LLM-as-a-Judge evaluations, allowing you to evaluate traces containing images
These enhancements make it easier to build and evaluate multimodal applications that work with images and video content.
🔌 Custom AI Providers
We’ve improved support for custom AI providers with enhanced configuration options:
- Multiple Custom Providers - Set up multiple custom AI providers for use in the Playground and online scoring
- Custom Headers Support - Configure custom headers for your custom providers, giving you more flexibility in how you connect to enterprise AI services
🧪 Enhanced Evals & Observability
We’ve added several improvements to make evaluation and observability more powerful:
- Trace and Span Metadata in Datasets - Ability to add trace and span metadata to datasets for advanced agent evaluation, enabling more sophisticated evaluation workflows
- Tokens Breakdown Display - Display tokens breakdown (input/output) in the trace view, giving you detailed visibility into token usage for each span and trace
- Binary (Boolean) Feedback Scores - New support for binary (Boolean) feedback scores, allowing you to capture simple yes/no or pass/fail evaluations
🎨 UX Improvements
We’ve made several user experience enhancements across the platform:
- Improved Pretty Mode - Enhanced pretty mode for traces, threads, and annotation queues, making it easier to read and understand your data
- Date Filtering for Traces, Threads, and Spans - Added date filtering capabilities, allowing you to focus on specific time ranges when analyzing your data
- New Optimization Runs Section - Added a new optimization runs section to the home page, giving you quick access to your optimization results
- Comet Debugger Mode - Added Comet Debugger Mode with app version and connectivity status, helping you troubleshoot issues and understand your application’s connection status. Read more about it here

And much more! 👉 See full commit log on GitHub
Releases: 1.8.98, 1.8.99, 1.8.100, 1.8.101, 1.8.102, 1.9.0, 1.9.1, 1.9.2, 1.9.3, 1.9.4, 1.9.5, 1.9.6, 1.9.7, 1.9.8, 1.9.9, 1.9.10, 1.9.11, 1.9.12, 1.9.13, 1.9.14, 1.9.15, 1.9.16, 1.9.17