Imagine you are a developer building an agentic AI application or chatbot. You are probably not just coding a single call to an LLM model. These AI systems often involve complex, multi-step journeys that guide the user toward accomplishing a specific goal. As we build increasingly dynamic conversational AI Agents, these modern systems are able to adapt and explore different reasoning paths, responding to complex and open-ended tasks. While this gives AI a powerful problem-solving capability, it also means we cannot always predict the exact behavior the AI will take to solve a problem. When it comes to monitoring and debugging, simply verifying individual steps is not enough. To truly understand the quality of the AI’s output, we need to evaluate the full session end-to-end. We are looking to understand quotations like:
- Did the AI accomplish the goal the user entered the session with?
- Did the interaction flow logically and remain aligned with the user’s intent?
- Did the user become frustrated with the AI interactions
This is why traditional trace-level LLM evaluation falls short. We need to evaluate the session goal, not just the steps.
Understanding when the AI is not meeting users’ expectations is tricky when we’re not experts in the domain where the AI is deployed. As Engineers and Data Scientists, we are often highly skilled in AI, software development, or mathematics, but we are not always experts in the domains for which we are building AI applications. Yet, the most effective AI developers I have worked with throughout my career are those who deeply understand the business use case their system serves, not just the technology they are using to implement it.
But it is not scalable to try to master every domain where AI could be applied. AI is applicable everywhere and is disrupting almost every industry today. So, as developers, what can we do when working in a domain with which we are not familiar? How can we acquire that domain knowledge and translate it into more effective AI design?
In my experience as an AI engineer and data scientist, I have consistently sought to establish connections with other departments within the business, allowing me to learn from them and gain a deeper understanding of the broader problem space in which I was working. I tried to incorporate their expert insights into my software design.
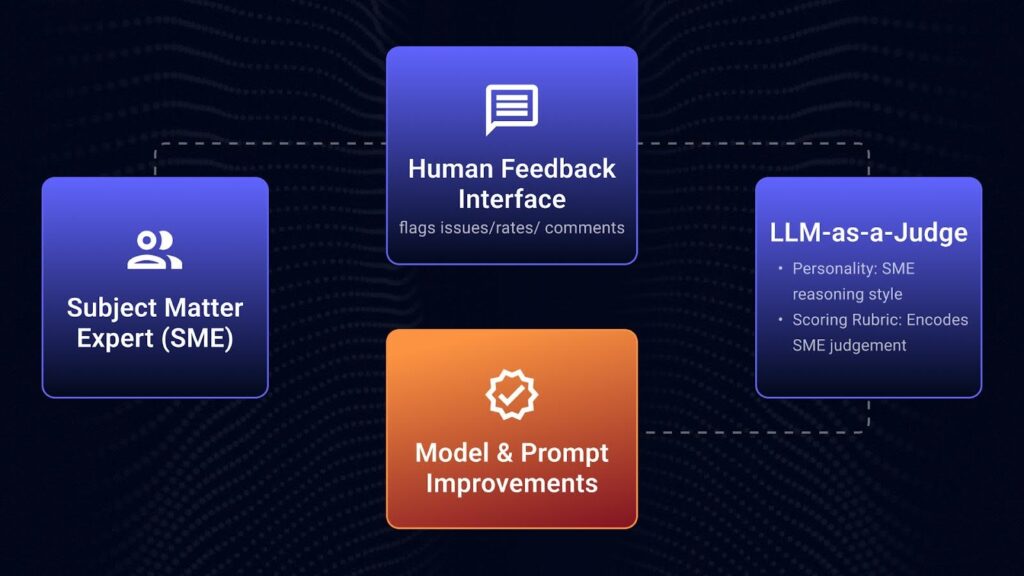
The key challenge today is capturing this kind of expertise and turning it into a reliable signal that AI systems can automatically learn from. This is where Human-in-the-Loop feedback becomes critical.
Automating Human-in-the-Loop Feedback for GenAI
It is impossible to ask an expert human to provide feedback on every output generated by our AI applications. Labeling data is not the best use of an expert’s time. So to make this work at scale, we need a low-friction way for domain experts to interact with AI systems, flag issues, rate conversations, and leave comments. From there, developers need a seamless way to feed that feedback back into the workflow to improve prompts, models, and overall system behavior.
This is where Opik, Comet’s open-source LLM evaluation framework, comes in. Opik enables visibility into full conversation threads and Agentic decision trees. We can collect feedback and design LLM evaluation metrics that test whether the AI system is producing output aligned with the user’s goals. These metrics reflect holistic quality, not just local correctness.
Opik provides a purpose-built annotation workflow at the thread level. It is designed specifically to support Human-in-the-Loop labeling, capturing feedback at scale, so we can design, debug, and improve our systems with real-world complexity in mind. This workflow combines human insight, scalable evaluation, and deep observability into a single, powerful developer workflow. Whether we are debugging a trace, tuning a prompt, or scaling a new model deployment, everything is traceable, measurable, and improvable.
Implementing a Human-in-the-Loop Annotation Workflow in Opik
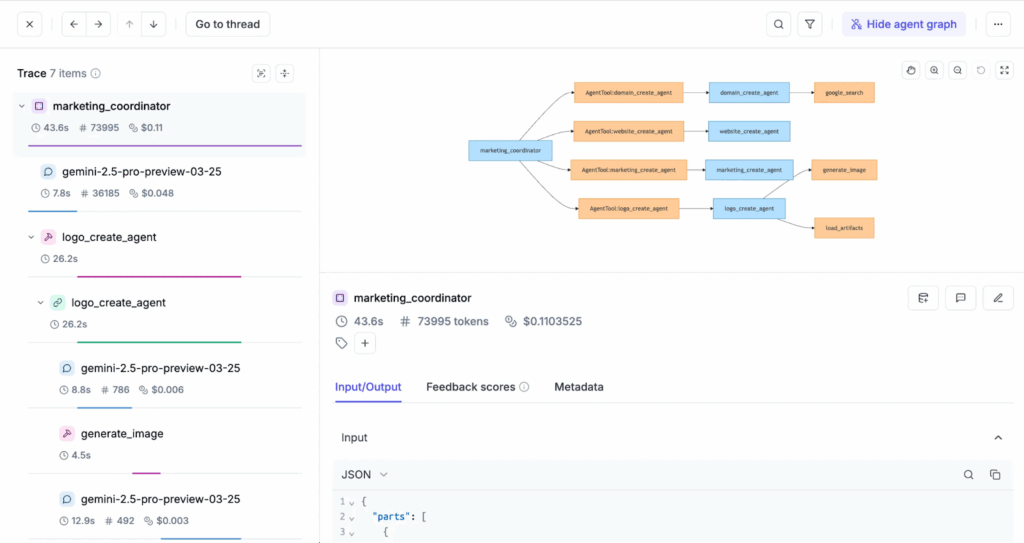
Let’s walk through how Opik supports high-quality Agent tracing, data labeling, and evaluation. I will use an example project I created using the Google ADK to build a multi-agent Financial Analyst chatbot.
Step 1. Log traces
First, Opik automatically groups all traces from a session into a single view. This allows us to follow and analyze the entire interaction between the Agent and her from start to finish. We can also see which sessions are active or inactive, helping us manage ongoing conversations versus those ready for review and annotation.
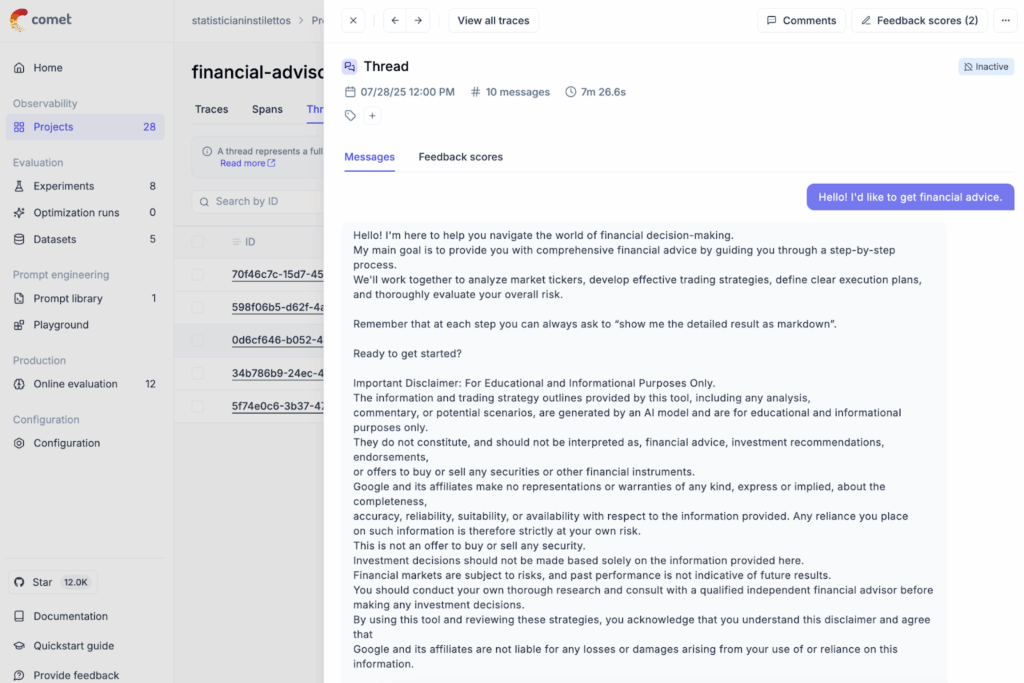
Step 2. Annotate Traces
Humans can review conversation sessions in Opik, score them, leave comments, and tag specific issues. This Human-in-the-Loop live feedback mechanism is critical to tackling alignment issues and to adapting to new, unseen patterns in production. Humans have an outstanding ability to detect edge cases in real time and define metrics that catch similar issues in the future.
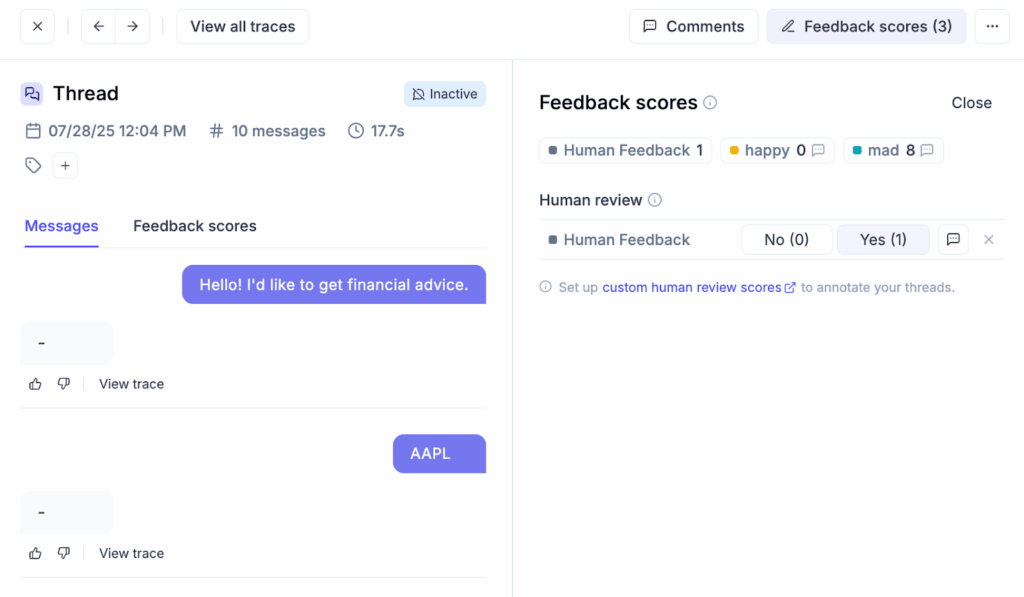
Step 3. Create Thread-level LLM-as-a-Judge metrics
Collecting human feedback is invaluable, but it is unreasonable to ask our subject matter expert friends to label every output from an AI system. We need a way to automate this so the AI can be self-improving.
The next step for us, as developers, is to review the human feedback collected in the UI. Patterns can be discovered by filtering feedback scores or tags, drilling into problematic sessions, and using the span table to identify recurring issues across agents, tools, or subagents. We can then use this information to enhance our AI system by creating metrics that closely mimic human feedback.
We can create an LLM-as-a-Judge metric to distill human feedback into a scoring rubric that becomes an AI output itself, effectively creating an automated evaluator that reflects the domain expert’s reasoning. This evaluation metric can even be given a “personality” that mirrors how the expert thinks.
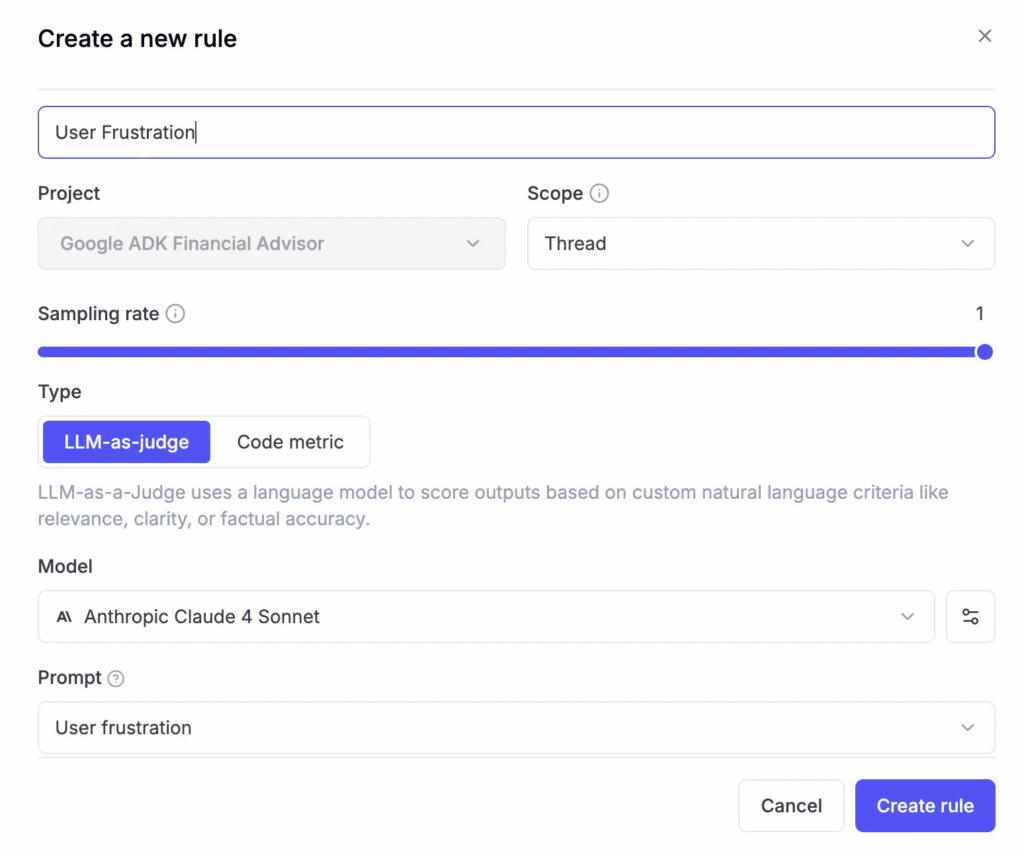
Step 4. Automatically scale up!
This workflow of collecting human feedback and then designing an LLM-as-a-Judge metric allows us to scale annotation across all past sessions and evaluate improvements before deploying a new version of our LLM app. The human-labeled scores can be compared with LLM-as-a-Judge scores in Opik to validate model behavior and tune evaluations further.
The Opik dashboard provides a high-level view of the system, showing feedback trends, performance shifts, and how the model evolves over time. Evaluation metrics monitored at the session level give developers a comprehensive view of the AI system. By combining expert feedback with automatic labeling, we can now confidently determine whether our users are satisfied with the AI results. We make data-driven improvements and track session-level performance to understand whether the AI system meets user goals.
I’m excited to see what you build!
Additional Resources
Interested in reproducing this project on your own? Here are the free code resources and documentation you need to follow along. The best way to learn is to start building:
- Financial Advisor example with the Google ADK Financial Advisor example with the Google ADK
- Learn how to use Opik to log traces to the Google ADK
- Log Opik traces for conversation threads and complex multi-agent systems
- Create online thread-level eval metrics online thread eval metrics
