
When it comes to machine learning projects, the hard truth is that training just one model on one version of a dataset won’t result in a production-ready model. The entire ML lifecycle is, by its nature, deeply iterative and interdependent. For a given project, dataset creation and model development will undoubtedly require numerous cycles.
And what’s more, making changes to one part of your ML workflow changes every part of your ML workflow.
New training data? You will need to run a few more model training experiments to understand how this new data will affect model performance. Your model isn’t performing well? You might have to return and collect ground truth data samples, adjust your labels, or make other dataset changes. This feedback loop between dataset collection/management and model training/experimentation is one of the most important — and potentially costly — parts of the ML lifecycle.
To help you build better models faster, you and your team will need tools and capabilities that allow you to make intelligent adjustments each step of the way — all while having high visibility into your workflows, as well as the ability to collaborate and reproduce your work at every step.
This is the power that tools like Superb AI and Comet offer when put to work in unison. In this article, we’re going to take a look at how these two tools can work together to help you speed up and improve two different but deeply connected stages of the ML lifecycle: (1) dataset collection and preparation + (2) model training and experimentation.
Additionally, we’ll show how you and your team can use Superb AI and Comet to create a feedback loop between model predictions, dataset iterations, and model retraining processes.
Superb AI Dataset Preparation Platform
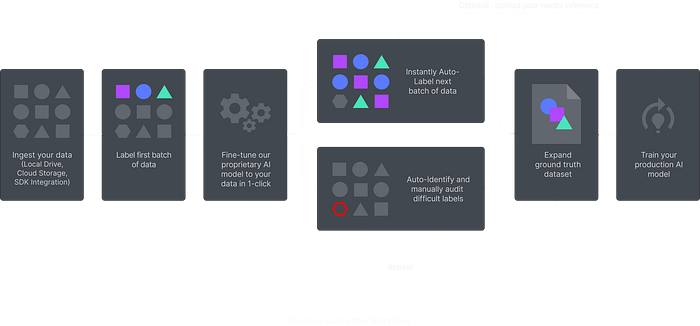
Superb AI has introduced a revolutionary way for ML teams to drastically decrease the time it takes to deliver high-quality training datasets for computer vision use csases. Instead of relying on human labelers for a majority of the data preparation workflow, teams can now implement a much more time- and cost-efficient pipeline with the Superb AI Suite.
A typical data preparation pipeline might contain the following steps:
- Data ingestion: Input data (images and videos) are often extracted from various sources. Users can upload input data into Superb Suite as raw files, via the cloud (AWS S3 or GCP), or via Superb Suite’s SDK/API.
- Ground-truth data creation: Having a small amount of initial ground-truth data (data with correct labels) is crucial to kickstart the labeling process. Users can create these ground-truth samples using Superb’s built-in simple annotation tool with filtering capability. Superb Suite supports classification, detection, and segmentation tasks for bounding boxes, polylines, polygons, and key points for both images and videos.
- Automatic labeling: Superb AI’s customizable auto-label technology uses a unique mixture of transfer learning, few-shot learning, and self-supervised learning — allowing the model to quickly achieve high levels of efficiency with small customer-proprietary datasets. And because the custom auto-label has broad applications, it can be used to swiftly jump-start any project, whether that be labeling your initial dataset for training or labeling your edge cases for retraining. This will drastically reduce the time it takes to prepare and deliver datasets.
- Labeled data delivery: The review and audit process of data labels is vital for the overall quality of the dataset. In reality, it is almost impossible to review every label manually. Superb AI Suite streamlines the review process by taking advantage of the label accuracy measures estimated by multiple machine learning models. After passing through this rigorous quality control process, the final labeled data is delivered to the MLOps pipeline.
Comet’s Experiment Management Platform
Machine learning addresses problems that cannot be well specified programmatically. Traditional software engineering allows strong abstraction boundaries between different components of a system in order to isolate the effects of changes.
Machine learning systems, on the other hand, are entangled with a host of upstream dependencies, such as the size of the dataset, the distribution of features within the dataset, data scaling and splitting techniques, the type of optimizer being used, etc.
Because ML systems lack a clear specification, data collection is an imperfect science, and effective machine learning models can be incredibly complex, experimentation is necessary.
The goal of the experimentation process is to understand how incremental changes affect the system. Rapid experimentation over different model types, data transformations, feature engineering choices, and optimization methods allows us to discern what is and isn’t working.
Because Machine learning is an experimental and iterative science, diligent tracking of these multiple sources of variability is necessary. Manually tracking these processes can be quite tedious and is further exacerbated when the size of an ML team grows and collaboration between members becomes a factor. It is well known that reproducibility is an issue in many machine learning papers, and while steps are being taken to address these issues, as humans, we are often prone to oversight.
This is where a platform like Comet comes into the picture. Comet is an Experiment Management Platform that helps practitioners automatically track, compare, visualize and share their experiments, source code, datasets, and models.
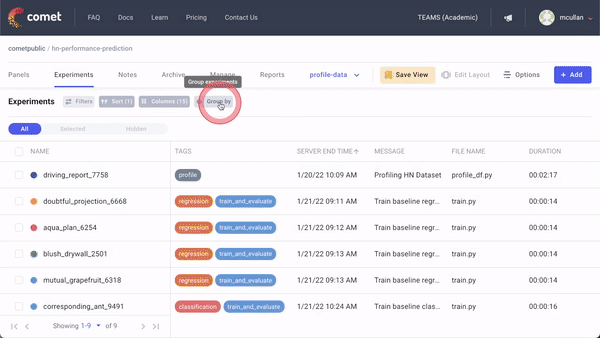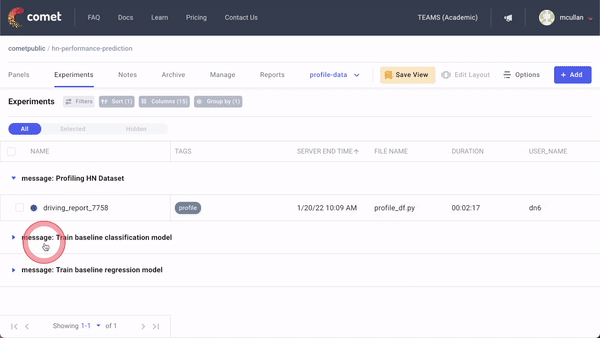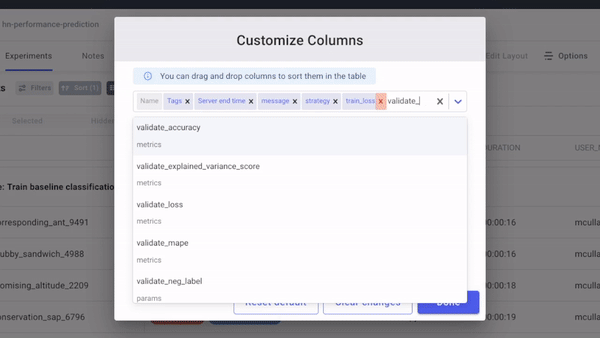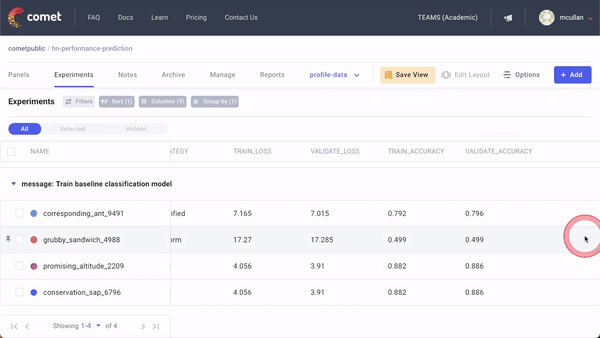
A typical workflow for experimentation with Comet contains the following steps:
- Define the project scope and relevant metrics: This is usually the most challenging part of the model development process. It involves talking to various stakeholders and clearly establishing the outcomes expected from the model and how these will be measured.
- Log the relevant dataset to Comet as an Artifact: Comet Artifacts is a tool used to track the lineage of datasets, as well as other data assets produced during the course of experimentation (model checkpoints, intermediate datasets, etc.).
- Experiment and iterate over different model types, data transformations, feature engineering choices, and optimization methods: We’ve already mentioned that in order to discern the type of model that would work best for your dataset, experimentation is necessary. Automated tracking of these variables allows teams to iterate on their models rapidly.
- Evaluate the model in production: Once a candidate model is chosen for deployment, it should be deployed to a production environment and monitored in order to assess its performance on real-world data and identify gaps in the model’s performance.
- Update the data: The performance of a model will inevitably degrade over time as the input data changes. In order to address these performance gaps, it’s necessary to update training datasets for this model with new data.
- Retrain the model: Once the training datasets are updated, repeat steps 1–4 to update the model.
Building a Data-to-Model Pipeline and Feedback Loop with Superb AI and Comet ML
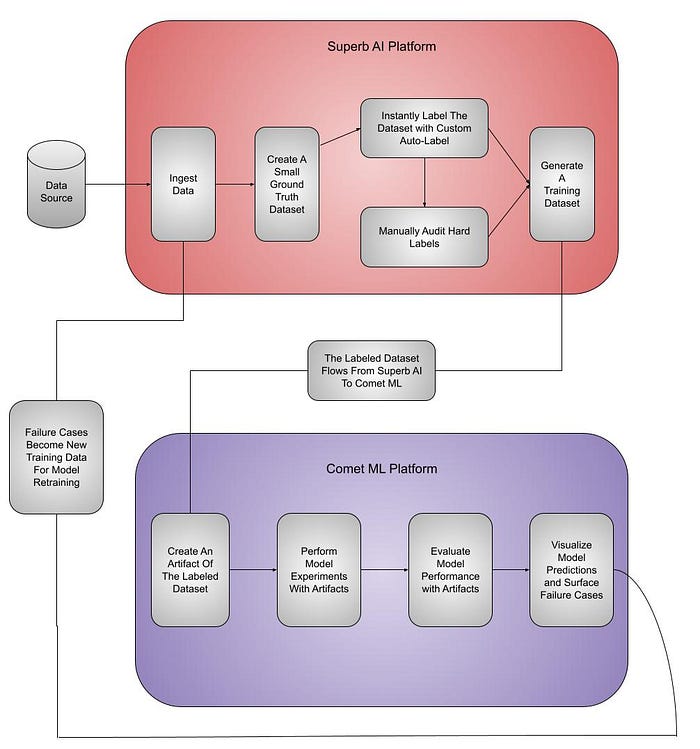
Coupled together, Superb AI and Comet cover data preparation and model experimentation workflows, respectively. As observed in the workflow diagram above:
- Given the raw data from your data sources, you can use the Superb AI platform to ingest the data, create a small ground-truth dataset, label that dataset with the auto-label technology, manually audit the hard labels, and generate a labeled training dataset.
- Then, the labeled dataset flows from the Superb AI platform to the Comet platform.
- You now can use the Comet platform to create Artifacts of the labeled dataset, run model experiments and evaluate model performance with the Artifacts, visualize model predictions, and surface failure prediction cases.
- Next, you can feed the failure prediction cases from Comet to Superb AI for ground-truth labeling and kickstart the model retraining procedure.
You can keep workflows between DataOps and MLOps teams separate — while enabling cross-team collaboration by preserving the visibility and auditability of the entire data-to-model pipeline across teams. With this pipeline in place, teams can increase the velocity and opportunity for seamless collaboration between scientists and engineers for machine learning workflows.
Conclusion
Intelligent platform choices make machine learning development much more feasible — especially as you’re scaling your ML strategy. With Superb AI’s data preparation capabilities and Comet’s model development capabilities, your ML teams can:
- Build, label, and audit training datasets as quickly as possible.
- Learn how changes to those datasets affect the performance of a trained model.
- Have visibility into your model training experiments in order to better understand how specific dataset choices affect model performance.
- Learn where gaps exist in your training datasets, iterate on them, and compare performance across model training runs.
Stay tuned! Our teams are at working on a technical walkthrough, and a few more fun things.
If you’re interested in learning more about the Comet platform, you can check out a demo, or try out the platform for free
If you’re interested in learning more about the Superb AI platform, sign up for the product for free and read the blog.

