
Introduction
Web scraping automates the extraction of data from websites using programming or specialized tools. Required for tasks such as market research, data analysis, content aggregation, and competitive intelligence. This efficient method saves time, improves decision making, and allows businesses to study trends and patterns, making it a powerful tool for extracting valuable information from the Internet.
Since I received a lot of positive comments on my last article, I would like to delve into this topic that is of interest to many people. Besides BeautifulSoup, Scrapy, and Selenium, have you considered web scraping using LLM? It’s a technique worthy of your curiosity.
💡I write about Machine Learning on Medium || Github || Kaggle || Linkedin. 🔔 Follow “Nhi Yen” for future updates!
Let’s start!!!
If you know Python but not HTML, you should first understand the basics of HTML.
I. Understanding Basic HTML for Web Scraping
HTML is the basic component of web pages. A set of tags is used to structure content on the Internet. Tags are like containers that wrap various elements, defining their structure and appearance on a web page.

1. Structure of HTML
An HTML document consists of 2 main parts: header and body.
- The header contains metadata such as the page title and links to external resources.
- The body contains the content of the web page, including text, images, and other multimedia elements.
Here’s a simple HTML template:
<!DOCTYPE html>
<html>
<head>
<title>My First Web Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a simple webpage.</p>
</body>
</html>
2. HTML Tags
Tags are the heart of HTML. They define different elements on a webpage. Some common tags include:
<h1>to<h6>: Headings, with<h1>being the largest and<h6>the smallest.<p>: Paragraphs of text.<a>: Hyperlinks, allowing you to navigate to other pages.<img>: Images.<ul>,<ol>,<li>: Lists, both unordered and ordered.
3. Attributes:
Attributes provide additional information about an HTML element. These are always included in the opening tag and specified as name/value pairs. For example, the href attribute in an <a> tag defines the hyperlink’s destination.
<a href="https://www.example.com">Visit Example</a>
4. How to Inspect Elements in a Website
Most web browsers provide built-in tools for inspecting elements. To open this tool, right-click the web page and select Inspect. Here you can view the HTML code and identify the tags containing the data you want to extract.

Selectors help pinpoint specific elements on a webpage. Common selectors include:
- Element Selector:
elementselects all instances of the specified HTML element. - Class Selector:
.classselects all elements with the specified class. - ID Selector:
#idselects a unique element with the specified ID.
For example:

II. How to Scrape
❗Disclaimer
This article is not about web scraping for illegal purposes. Make sure you have permission before extracting content. Ways to check include:
- Review the website’s terms of use. Look for mentions of scraping permissions.
- Use APIs when available. APIs provide legal access to data.
- Please contact the website owner to clarify your permission directly.
OK, assume you are aware of your actions. Let’s start.
Here’s the URL for Action Movies of 2022: https://www.imdb.com/list/ls566941243/. I’ll use 05 different methods to scrape [‘Title’, ‘Genre’, ‘Stars’, ‘Runtime’, ‘Rating’] data from this website.
# Define the URL
url = "https://www.imdb.com/list/ls566941243/"
👉 You can find the entire code in this GitHub Repository. To begin, please install the required Python packages listed in requirements.txt.
Method 1: BeautifulSoup and Requests for Web Scraping
The first method uses the popular BeautifulSoup and Requests libraries. These tools make it easy to analyze HTML and navigate web page structure. Below is a sample Python code.
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Step 1: Send a GET request to the specified URL
response = requests.get(url)
# Step 2: Parse the HTML content of the response using BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Step 3: Save the HTML content to a text file for reference
with open("imdb.txt", "w", encoding="utf-8") as file:
file.write(str(soup))
print("Page content has been saved to imdb.txt")
# Step 4: Extract movie data from the parsed HTML and store it in a list
movies_data = []
for movie in soup.find_all('div', class_='lister-item-content'):
title = movie.find('a').text
genre = movie.find('span', class_='genre').text.strip()
stars = movie.find('div', class_='ipl-rating-star').find('span', class_='ipl-rating-star__rating').text
runtime = movie.find('span', class_='runtime').text
rating = movie.find('span', class_='ipl-rating-star__rating').text
movies_data.append([title, genre, stars, runtime, rating])
# Step 5: Create a Pandas DataFrame from the extracted movie data
df = pd.DataFrame(movies_data, columns=['Title', 'Genre', 'Stars', 'Runtime', 'Rating'])
# Display the resulting DataFrame
df
In each web scraping method, I save the HTML in an imdb.txt file for a clearer view of the targeted HTML elements.
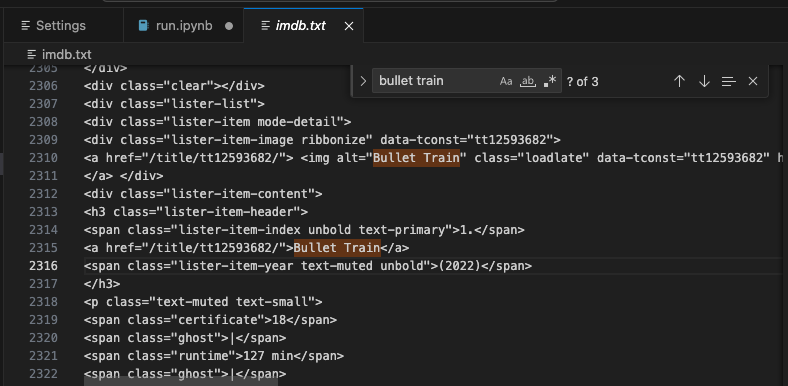
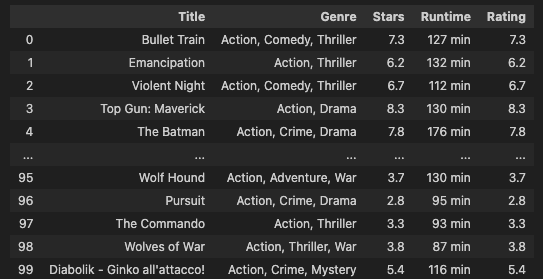
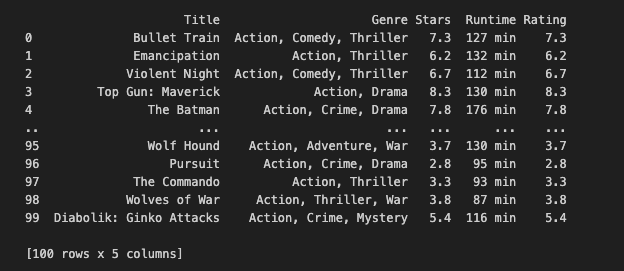
Final Output:
Method 2: ScraPy for Web Scraping
ScraPy is a powerful and flexible web scraping framework. Below is a code snippet showing how to use ScraPy, with explanations in the comments.:
# Import necessary libraries
import scrapy
from scrapy.crawler import CrawlerProcess
# Define the Spider class for IMDb data extraction
class IMDbSpider(scrapy.Spider):
# Name of the spider
name = "imdb_spider"
# Starting URL(s) for the spider to crawl
start_urls = ["https://www.imdb.com/list/ls566941243/"]
# start_urls = [url]
# Parse method to extract data from the webpage
def parse(self, response):
# Iterate over each movie item on the webpage
for movie in response.css('div.lister-item-content'):
yield {
'title': movie.css('h3.lister-item-header a::text').get(),
'genre': movie.css('p.text-muted span.genre::text').get(),
'runtime': movie.css('p.text-muted span.runtime::text').get(),
'rating': movie.css('div.ipl-rating-star span.ipl-rating-star__rating::text').get(),
}
# Initialize a CrawlerProcess instance with settings
process = CrawlerProcess(settings={
'FEED_FORMAT': 'json',
'FEED_URI': 'output.json', # This will overwrite the file every time you run the spider
})
# Add the IMDbSpider to the crawling process
process.crawl(IMDbSpider)
# Start the crawling process
process.start()
import pandas as pd
# Read the output.json file into a DataFrame (jsonlines format)
df = pd.read_json('output.json')
# Display the DataFrame
df.head()
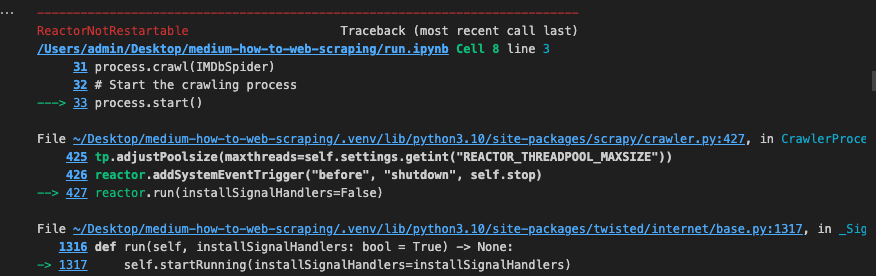
In this demo, I’m using Jupyter Notebook. If you encounter a ReactorNotRestartable error, just restart the kernel and run the code again.
Display the data in a dataframe:
import pandas as pd
# Read the output.json file into a DataFrame (jsonlines format)
df = pd.read_json('output.json')
# Display the DataFrame
df.head()
Method 3: Selenium for Web Scraping
Selenium is often used for dynamic web scraping. Here’s a basic example:
from selenium import webdriver
from bs4 import BeautifulSoup
import pandas as pd
# URL of the IMDb list
url = "https://www.imdb.com/list/ls566941243/"
# Set up Chrome options to run the browser in incognito mode
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--incognito")
# Initialize the Chrome driver with the specified options
driver = webdriver.Chrome(options=chrome_options)
# Navigate to the IMDb list URL
driver.get(url)
# Wait for the page to load (adjust the wait time according to your webpage)
driver.implicitly_wait(10)
# Get the HTML content of the page after it has fully loaded
html_content = driver.page_source
# Parse the HTML content with BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Save the HTML content to a text file for reference
with open("imdb_selenium.txt", "w", encoding="utf-8") as file:
file.write(str(soup))
print("Page content has been saved to imdb_selenium.txt")
# Extract movie data from the parsed HTML
movies_data = []
for movie in soup.find_all('div', class_='lister-item-content'):
title = movie.find('a').text
genre = movie.find('span', class_='genre').text.strip()
stars = movie.select_one('div.ipl-rating-star span.ipl-rating-star__rating').text
runtime = movie.find('span', class_='runtime').text
rating = movie.select_one('div.ipl-rating-star span.ipl-rating-star__rating').text
movies_data.append([title, genre, stars, runtime, rating])
# Create a Pandas DataFrame from the collected movie data
df = pd.DataFrame(movies_data, columns=['Title', 'Genre', 'Stars', 'Runtime', 'Rating'])
# Display the resulting DataFrame
print(df)
# Close the Chrome driver
driver.quit()
Final Output:
The key to Selenium is in its Chrome options, which are settings for customizing the behavior of the Chrome browser controlled by Selenium WebDriver. These options enable control over aspects like incognito mode, window size, notifications, and more.
Here are some important Chrome options that you might find useful:
# Runs the browser in incognito (private browsing) mode.
chrome_options.add_argument("--incognito")
# Runs the browser in headless mode, i.e., without a graphical user interface.
# Useful for running Selenium tests in the background without opening a visible browser window.
chrome_options.add_argument("--headless")
# Sets the initial window size of the browser.
chrome_options.add_argument("--window-size=1200x600")
# Disables browser notifications.
chrome_options.add_argument("--disable-notifications")
# Disables the infobar that appears at the top of the browser.
chrome_options.add_argument("--disable-infobars")
# Disables browser extensions.
chrome_options.add_argument("--disable-extensions")
# Disables the GPU hardware acceleration.
chrome_options.add_argument("--disable-gpu")
# Disables web security features, which can be useful for testing on localhost without CORS issues.
chrome_options.add_argument("--disable-web-security")
These options can be combined or used individually based on your requirements. When you create a webdriver.Chrome instance, you can pass these options using the options parameter:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--incognito")
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
These options provide flexibility and control over the browser’s behavior when using Selenium for web automation or testing. Choose options based on your specific use case and requirements.
Method 4: Requests and lxml for Web Scraping
lxml is a Python library linking with C libraries libxml2 and libxslt, combining speed and XML features with a simple native Python API, similar to ElementTree but with added benefits.
import requests
from lxml import html
import pandas as pd
# Define the URL
url = "https://www.imdb.com/list/ls566941243/"
# Send an HTTP request to the URL and get the response
response = requests.get(url)
# Parse the HTML content using lxml
tree = html.fromstring(response.content)
# Extract movie data from the parsed HTML
titles = tree.xpath('//h3[@class="lister-item-header"]/a/text()')
genres = [', '.join(genre.strip() for genre in genre_list.xpath(".//text()")) for genre_list in tree.xpath('//p[@class="text-muted text-small"]/span[@class="genre"]')]
ratings = tree.xpath('//div[@class="ipl-rating-star small"]/span[@class="ipl-rating-star__rating"]/text()')
runtimes = tree.xpath('//p[@class="text-muted text-small"]/span[@class="runtime"]/text()')
# Create a dictionary with extracted data
data = {
'Title': titles,
'Genre': genres,
'Rating': ratings,
'Runtime': runtimes
}
# Create a DataFrame from the dictionary
df = pd.DataFrame(data)
# Display the resulting DataFrame
df.head()
Method 5: How to Use LangChain for Web Scraping
I bet all the readers who are interested this article know about ChatGPT, BARD. LLM makes life simpler. You can use it for various tasks, like asking ‘Who is Donald Trump?’ or ‘Translate sentences from German to English,’ and get quick answers. The good news is you can also use them for Web Scraping. Here’s how.
👉 Helpful LangChain resources for this demo:

Brief explanations for each code line are provided in the comments.
import os
import dotenv
import time
# Load environment variables from a .env file
dotenv.load_dotenv()
# Retrieve OpenAI and Comet key from environment variables
MY_OPENAI_KEY = os.getenv("MY_OPENAI_KEY")
MY_COMET_KEY = os.getenv("MY_COMET_KEY")
In my LLM Project, I usually record outputs in a Comet Project. In this demo, I’m using just 01 URL. However, if you need to loop through multiple URLs, Comet LLM’s experiment tracking is very useful.
👉 Read more about Comet LLM.
👉 How to obtain the API keys: OpenAI Help Center — Where can I find my API key?; CometLLM — Obtaining your API key
import comet_llm
# Initialize a Comet project
comet_llm.init(project="langchain-web-scraping",
api_key=MY_COMET_KEY,
)
# Resolve async issues by applying nest_asyncio
import nest_asyncio
nest_asyncio.apply()
# Import required modules from langchain
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import create_extraction_chain
# Define the URL
url = "https://www.imdb.com/list/ls566941243/"
# Initialize ChatOpenAI instance with OpenAI API key
llm = ChatOpenAI(openai_api_key=MY_OPENAI_KEY)
# Load HTML content using AsyncChromiumLoader
loader = AsyncChromiumLoader([url])
docs = loader.load()
# Save the HTML content to a text file for reference
with open("imdb_langchain_html.txt", "w", encoding="utf-8") as file:
file.write(str(docs[0].page_content))
print("Page content has been saved to imdb_langchain_html.txt")
# Transform the loaded HTML using BeautifulSoupTransformer
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
docs, tags_to_extract=["h3", "p"]
)
# Split the transformed documents using RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=1000, chunk_overlap=0)
splits = splitter.split_documents(docs_transformed)
Please note that depending on your needs, you might want to explore the HTML layout to select the right tags_to_extract. In this demo, I am extracting movie title, genre, rating, and runtime, so I’ll go with the <h3> and <p> tags.
Basically after obtaining the required HTML, we will ask LLM: “Hey LLM, with this HTML, please fill in the information according to the schema below.”
# Define a JSON schema for movie data validation
schema = {
"properties": {
"movie_title": {"type": "string"},
"stars": {"type": "integer"},
"genre": {"type": "array", "items": {"type": "string"}},
"runtime": {"type": "string"},
"rating": {"type": "string"},
},
"required": ["movie_title", "stars", "genre", "runtime", "rating"],
}
def extract_movie_data(content: str, schema: dict):
"""
Extract movie data from content using a specified JSON schema.
Parameters:
- content (str): Text content containing movie data.
- schema (dict): JSON schema for validating the movie data.
Returns:
- dict: Extracted movie data.
"""
# Run the extraction chain with the provided schema and content
start_time = time.time()
extracted_content = create_extraction_chain(schema=schema, llm=llm).run(content)
end_time = time.time()
# Log metadata and output in the Comet project for tracking purposes
comet_llm.log_prompt(
prompt=str(content),
metadata= {
"schema": schema
},
output= extracted_content,
duration= end_time - start_time,
)
return extracted_content
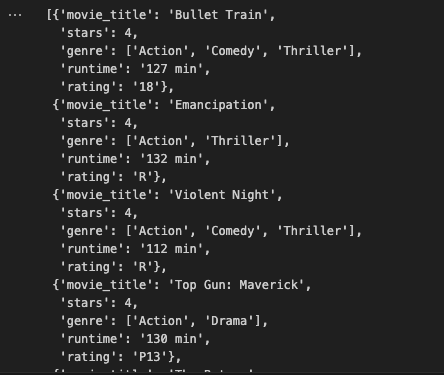
And finally, we’ve got the result:
# Extract movie data using the defined schema and the first split page content
extracted_content = extract_movie_data(schema=schema, content=splits[0].page_content)
# Display the extracted movie data
extracted_content
Final Output:
There’s a lot to discover about LLMs. Want more topics on LLM? Share your thoughts in the comments!
❗A Heads-up
Web scraping is not as simple as you might think. You may face challenges along the way.
- Dynamic website structures: Modern websites use dynamic JavaScript structures and require tools like Selenium for accurate data extraction.
- Anti-scraping: IP blocks and CAPTCHAs are common deterrents. Strategies such as IP address rotation can help overcome these obstacles.
- Legal and Ethical Considerations: To avoid legal repercussions, it is important to follow the website’s terms of use. Prioritize ethical practices and ask for permission.
- Data quality and consistency: Maintaining data quality while updating a website is an ongoing challenge. Update your scraping script regularly to ensure accurate and reliable extraction.
Conclusion
Web scraping is worth a try. It may not seem like a formal job, but it’s actually a lot of fun using Python, JavaScript, and HTML. There are many ways to collect information from websites. I hope you will try more than just web scraping by implementing LLM techniques.
