Model Training is Expensive
The cost to train a model is directly proportional to the time it takes to train a model. Have to add more data to your dataset? Your cost will go up. Use a bigger model with more parameters? Your cost will go up. Need more GPUs? That’s another added cost. Coupling all that with the fact model training is rarely a deterministic process, it’s very easy for teams to rack-up their monthly cloud training bills.
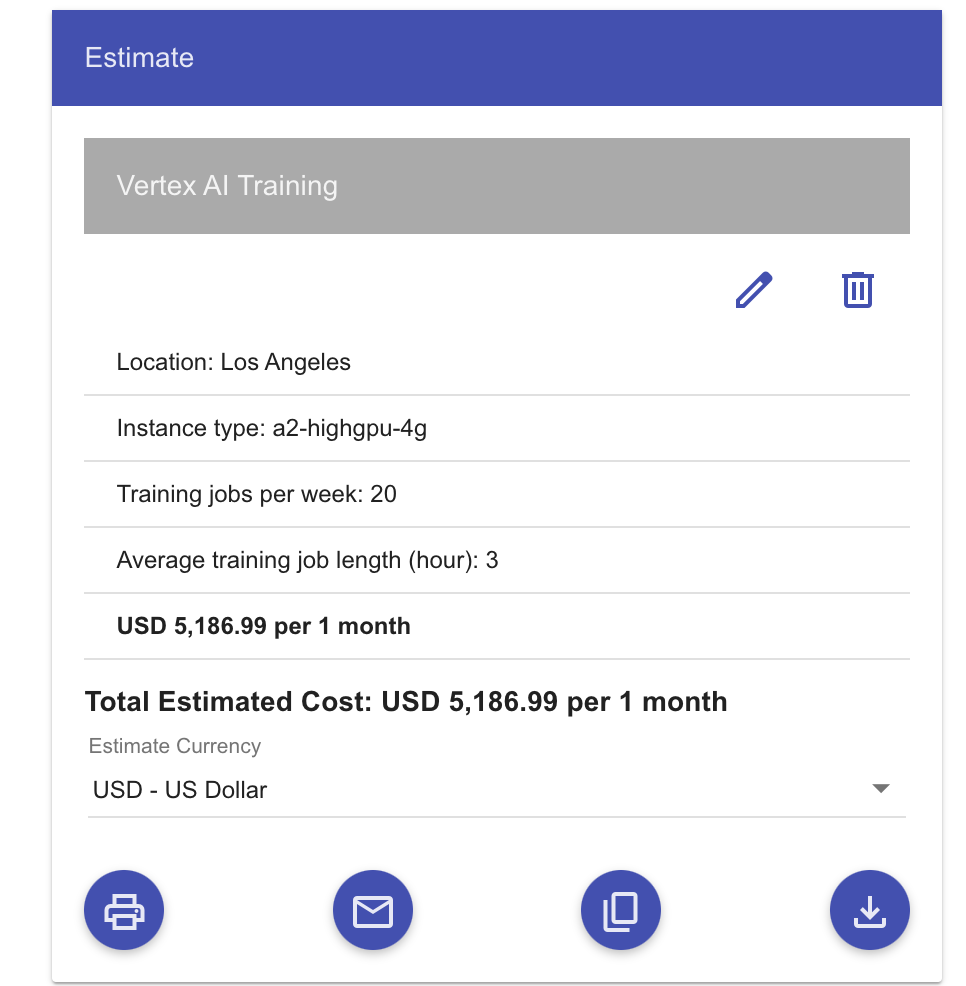
One solution is to just train less. While attractive, this can inhibit the productivity and deliverability of a project. Teams don’t need to stop training as a whole, they need to stop spending money on model training that isn’t adding value.
How to Leverage Comet to Avoid Overspending
Comet’s Experiment Management tool tracks everything and anything related to a Machine Learning Training. Comet can track the all the relevant inputs of a training run:
- Code
- Hyper-parameters
- Dataset Version
- Package Dependencies
As well as outputs of a training run:
- ML Metrics (Loss, Accuracy, & mAP)
- Model Predictions (images and .csv files)
- Training Time
- System Metrics (CPU and GPU usage)
Monitor Progress
Machine Learning Engineers always want to improve model performance. An accuracy of 98.6% is undoubtedly better than 98.5%. But is such a marginal performance improvement worth spending money on if you’re already nearing your monthly budget? What about instances where it’s very clear in the first 10 epochs that this model run isn’t going to perform that well?
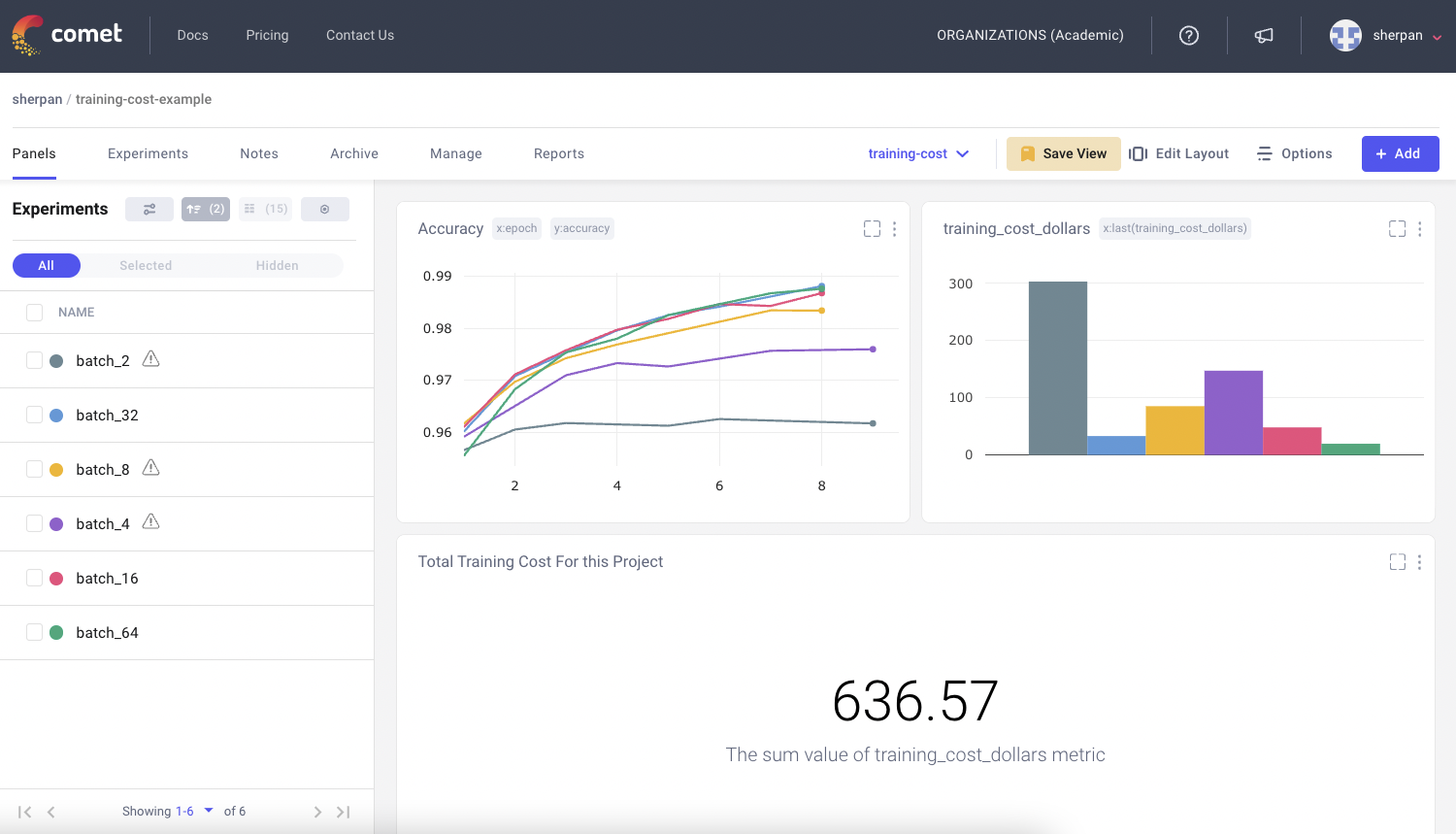
Comet’s SDK allows users to log any metrics related to the experiment and view it in our UI. Metrics such as loss and accuracy can be monitored live during a training run. If a model is clearly underperforming to a previous run early on, ML engineers can simply “early stop” a run and save cost. Users can use the Panel Dashboard to visualize both training performance metrics and cost side-by-side. ML Teams can now make data-informed decisions on whether to continue model training.
Avoid Duplication
Model training is an iterative process. Data Scientists are constantly trying to find the best combination of hyper-parameters, dataset versions, and model architectures that maximizes the model performance. It also can be a long process that spans weeks if not months. Given the increasing cost of an individual training run, teams need to make sure they are not duplicating experiments. A model trained with the same combination of inputs in early March is going to perform the same as if it was trained in late June. Since Comet acts as a system of record for all your model training runs, avoiding experiment duplication is easy.
In the tabular view of experiments, users can use our “Group By” functionality to group experiments based on hyper-parameters. This makes it easier to see all the combinations that have been done before.
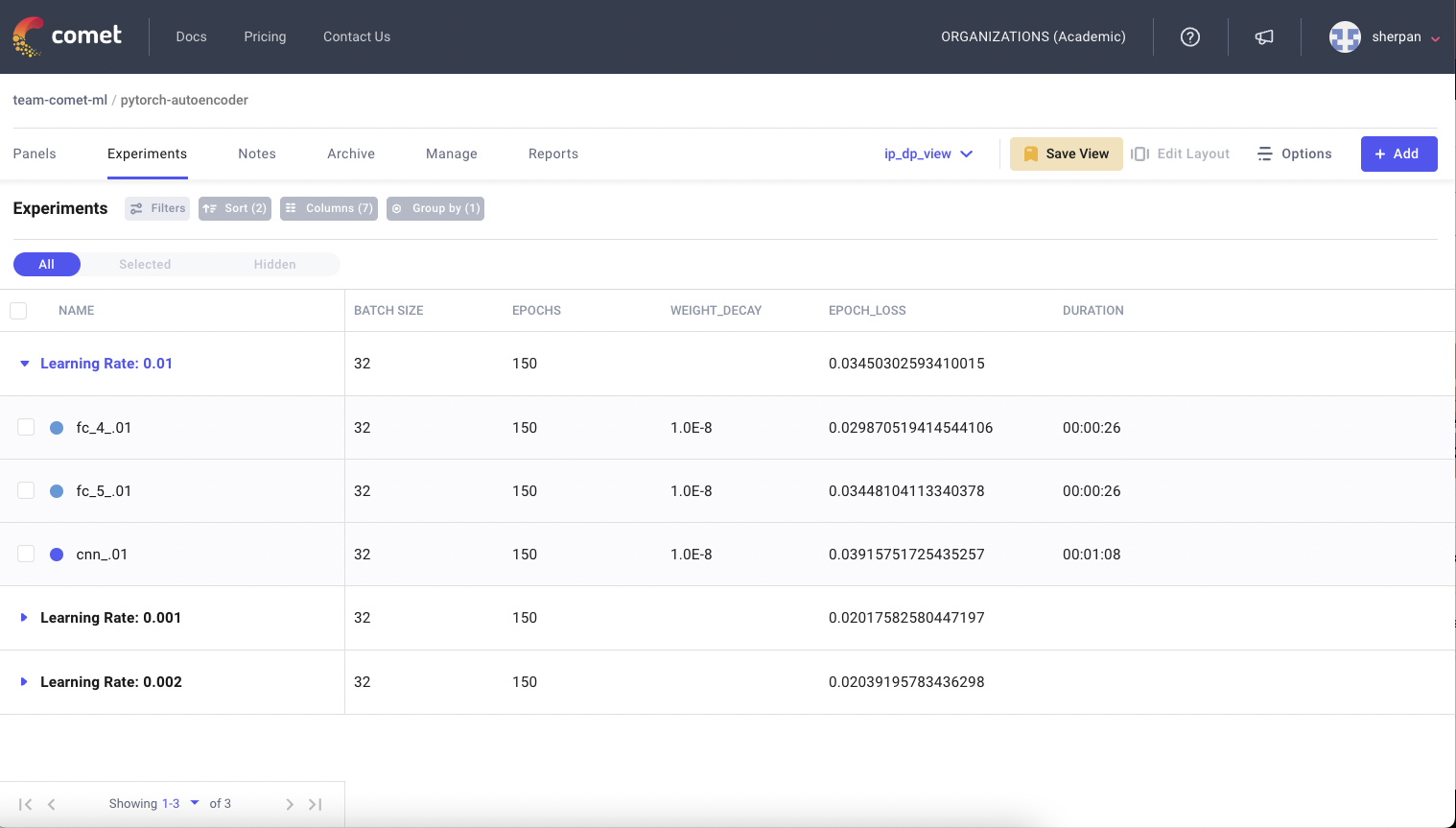
If a current training run is behaving eerily similar to a previous training run, Comet’s diff mode can be used to further investigate if it is a duplicated run by comparing the associated code and hyper-parameters. If so, a user can then prematurely stop the run and not waste more money.
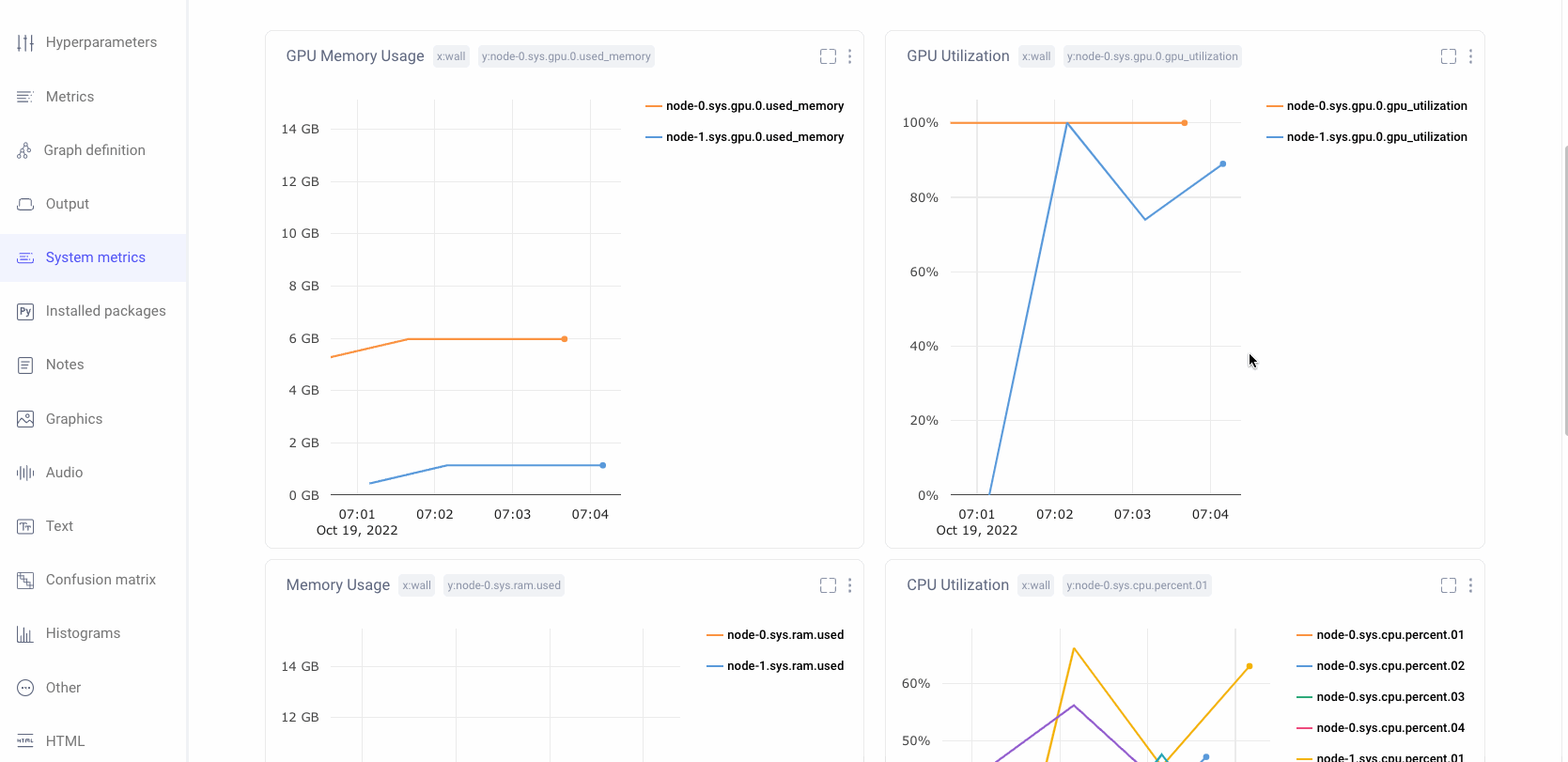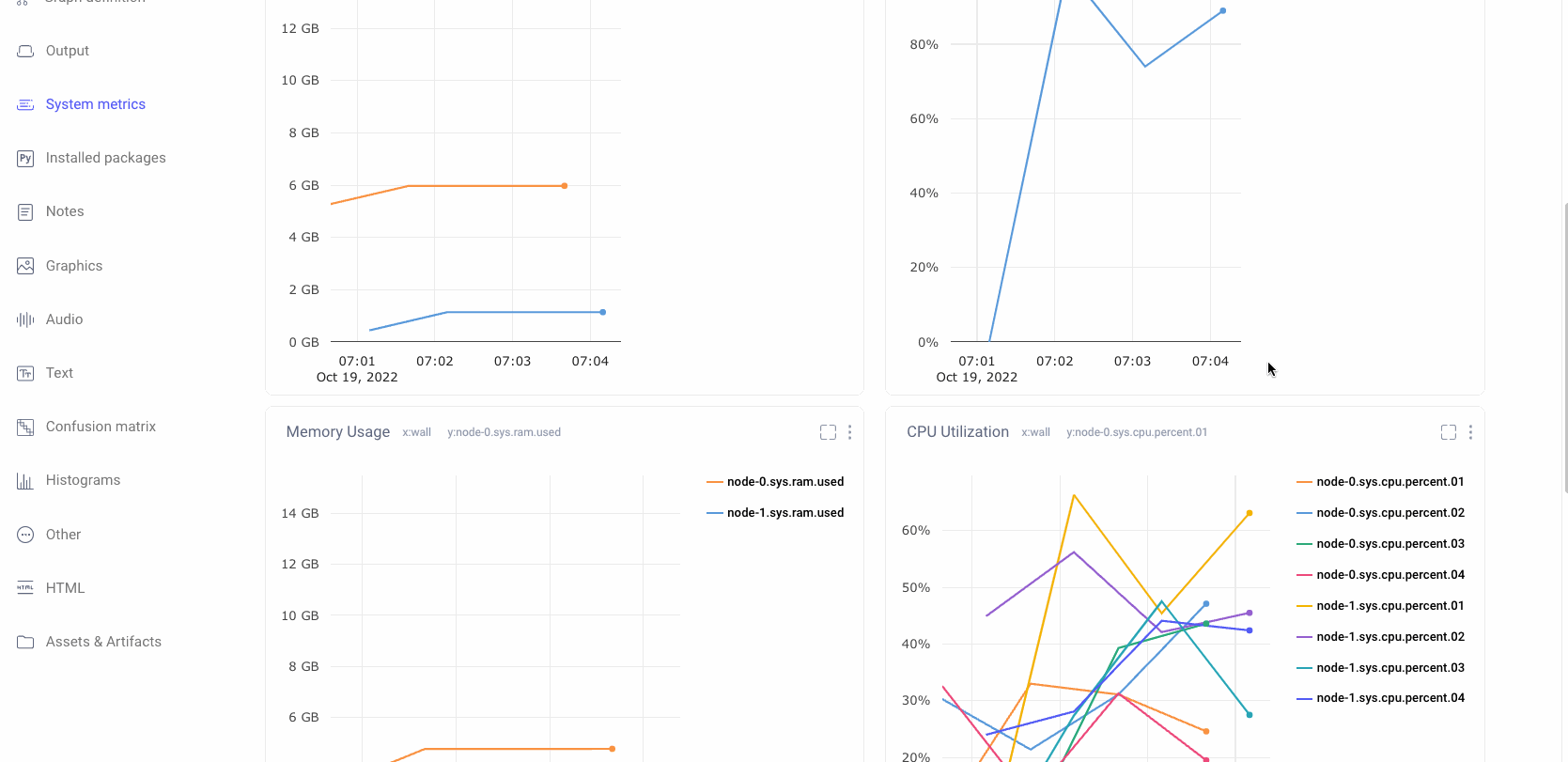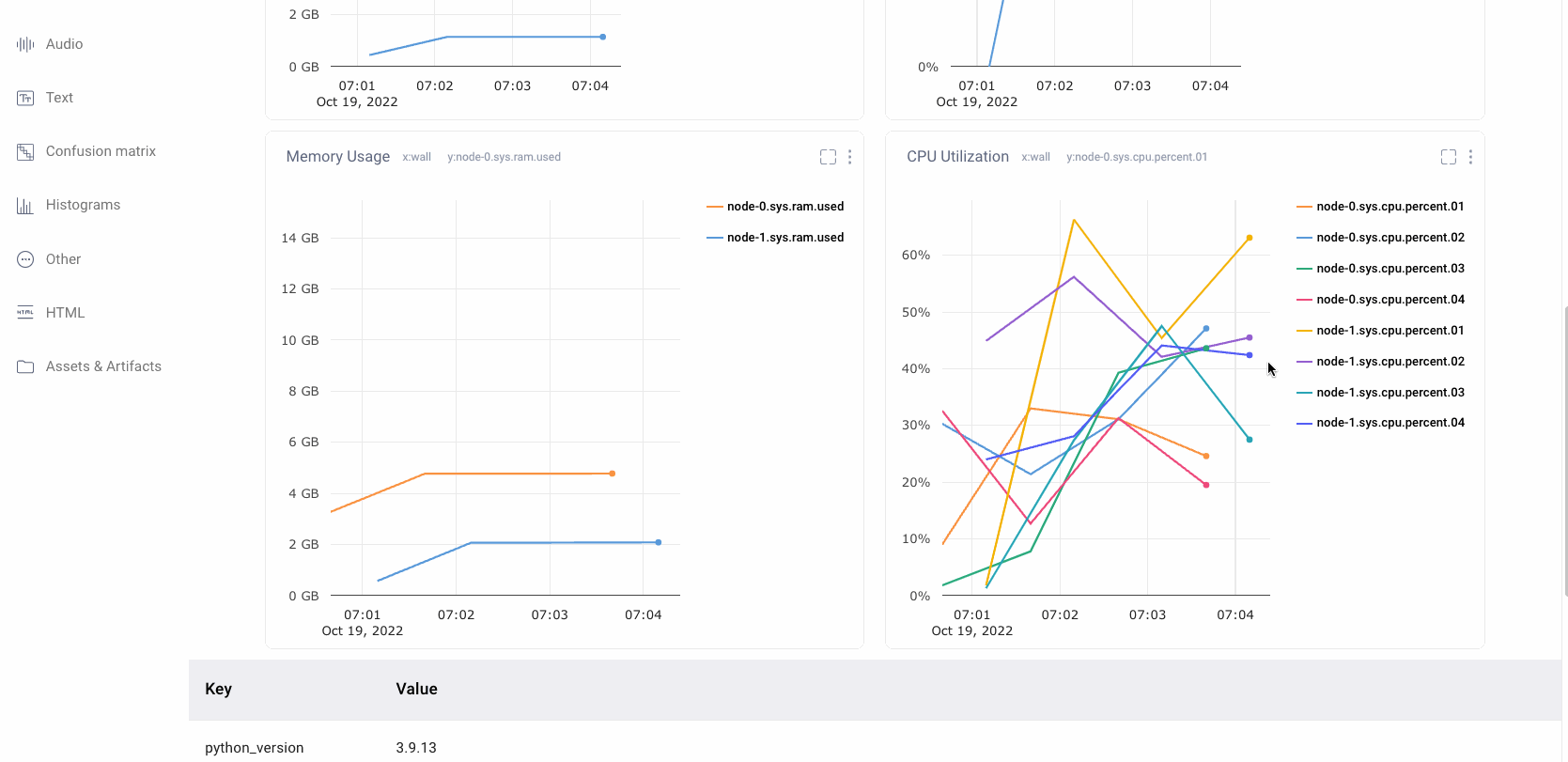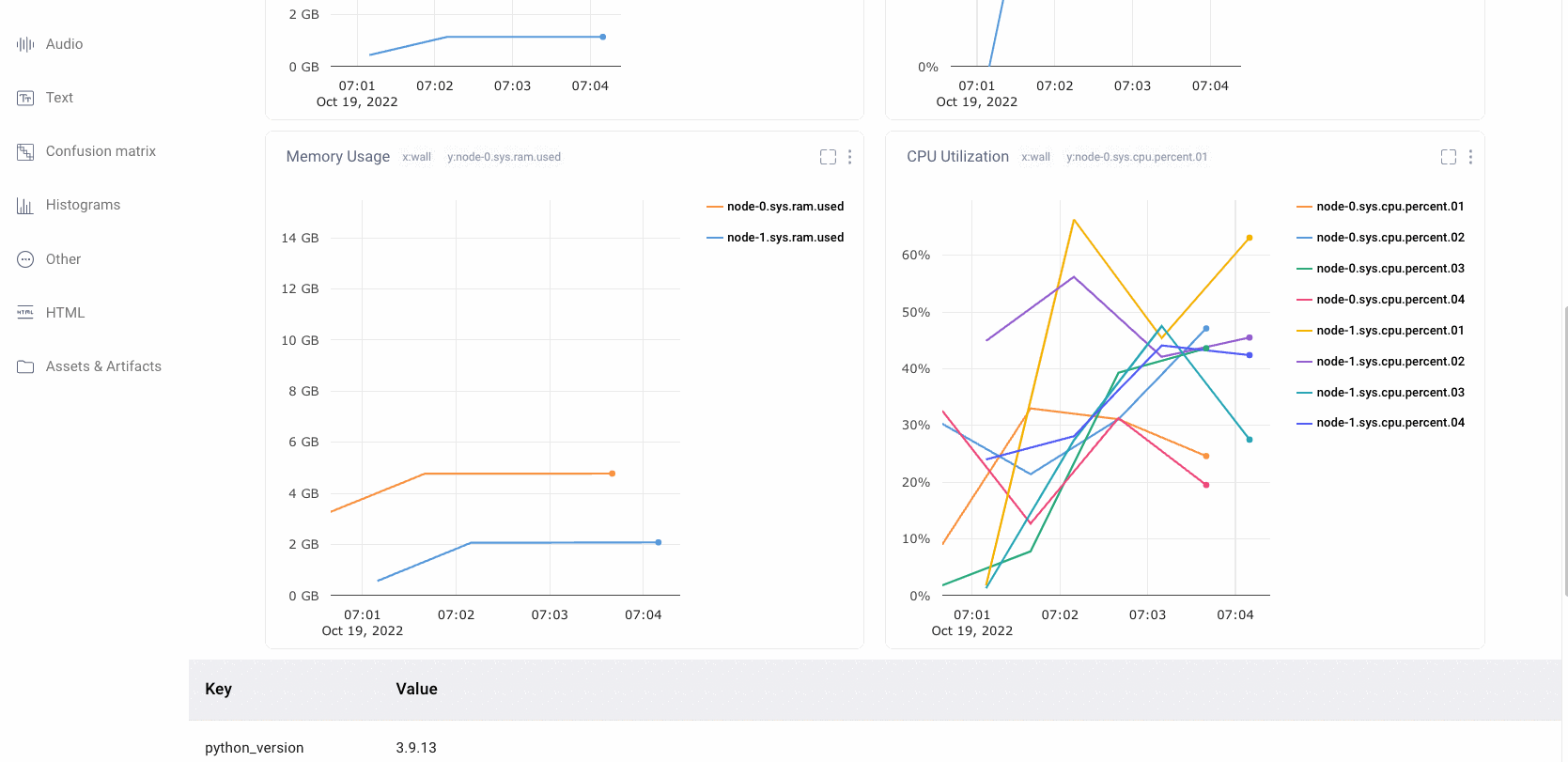
Verify Maximum GPU Utilization
GPUs are a powerful resource for Machine Learning Teams who are looking to efficiently train models. One of the most common mistakes for ML teams is having low gpu utilization. This leads to much longer model training times than necessary and drives up costs.
Comet automatically logs the system metrics of your hardware during a training run. Users can quickly navigate to this pane in the UI to check if an experiment’s gpu utilization is high. If not, Comet also stores the associated code and hyper-parameters and therefore is a great place to start debugging the bottleneck for high gpu utilization and make sure that future training runs are gpu and cost efficient.
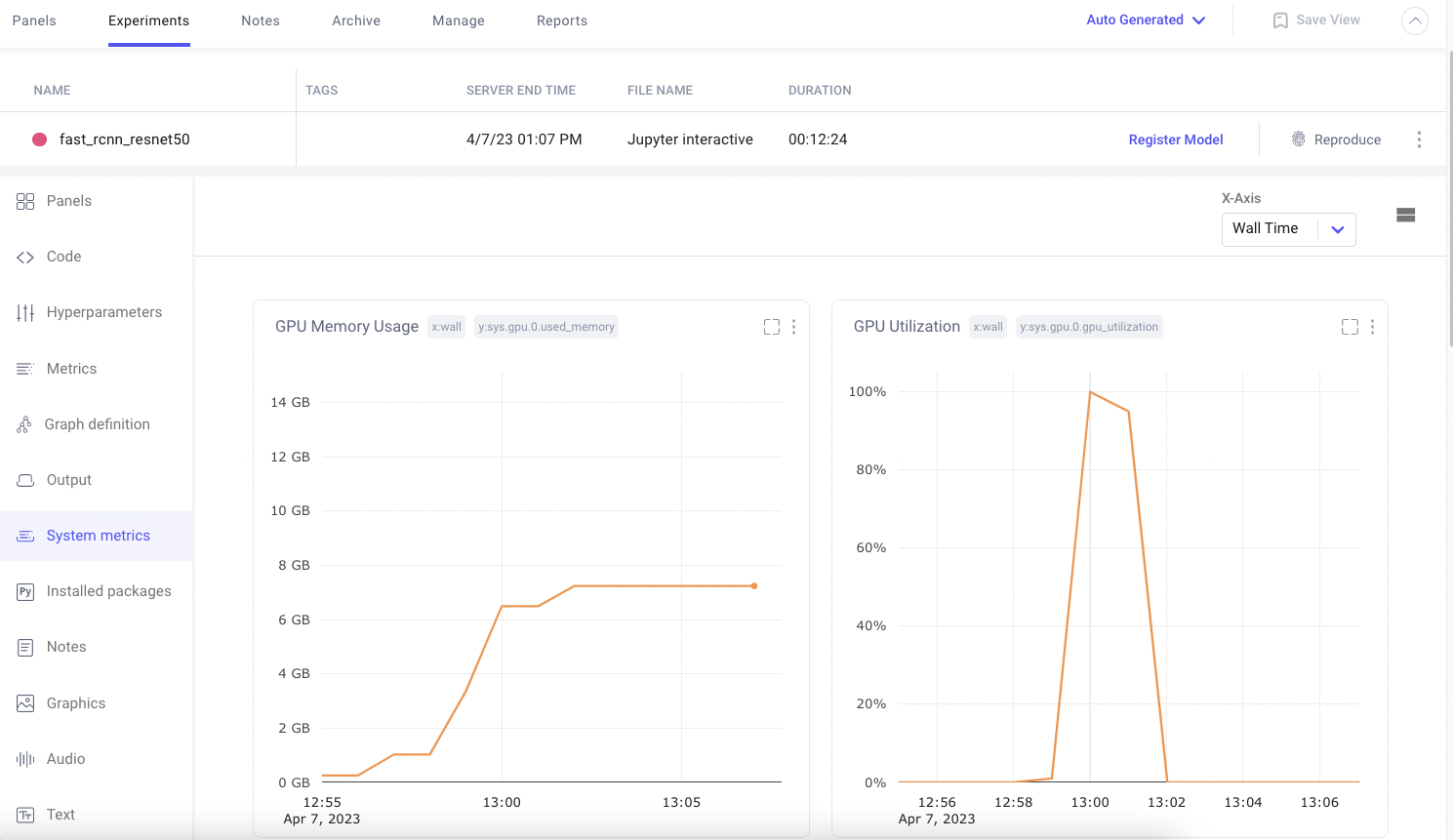
Comet also supports Distributed Training across multiple Nodes. Teams can leverage this functionality to ensure that training is running efficiently across all compute nodes.
Reduce Hyperparameter Search Space
Hyperparameter Optimization (HPO) tools help Data Scientists organize and schedule experiment runs to answer the age-old question of “What is the best combination of hyper-parameters”. Comet provides its own built-in Optimizer Tool and is also easy to integrate with open-source tools such as HyperOpt. By using an EM tool to record all your sweeps, it’s easy to see which hyper-parameters values are affecting the model.
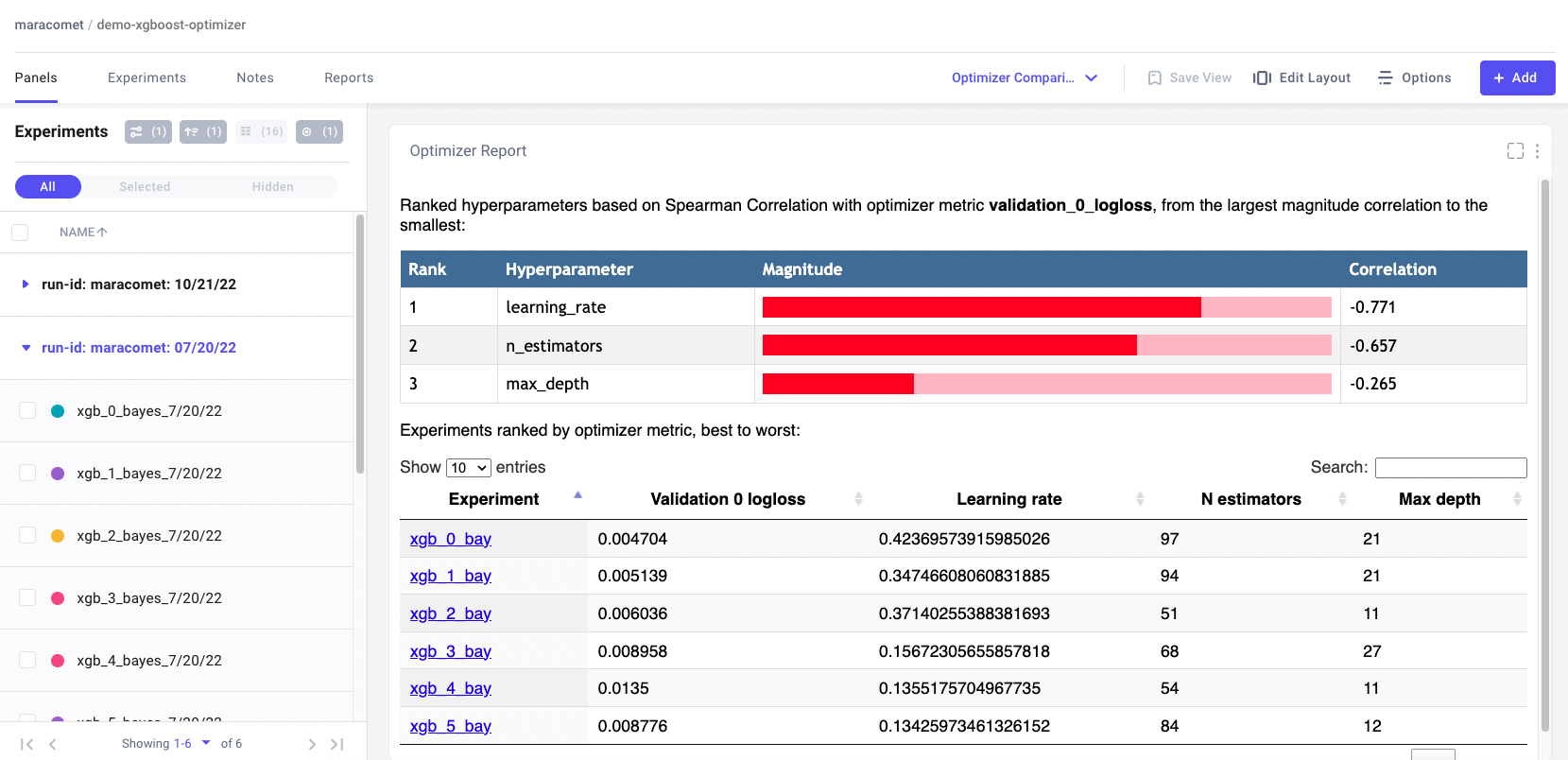
Teams often start with a wide search space and in doing so quickly learn that some values aren’t worth searching over for the next go-around. By reducing the search space for their HPO, ML teams can exponentially decrease the number of experiment runs and thus save huge amounts of costs.
Save Money with Comet
Comet is an extremely easy tool to add to your current training code and workflow. Sign-up for a free account today and see how quickly you can use it to optimize your team’s cost spending.
