Welcome to Lesson 6 of 12 in our free course series, LLM Twin: Building Your Production-Ready AI Replica. You’ll learn how to use LLMs, vector DVs, and LLMOps best practices to design, train, and deploy a production ready “LLM twin” of yourself. This AI character will write like you, incorporating your style, personality, and voice into an LLM. For a full overview of course objectives and prerequisites, start with Lesson 1.
Lessons
- An End-to-End Framework for Production-Ready LLM Systems by Building Your LLM Twin
- Your Content is Gold: I Turned 3 Years of Blog Posts into an LLM Training
- I Replaced 1000 Lines of Polling Code with 50 Lines of CDC Magic
- SOTA Python Streaming Pipelines for Fine-tuning LLMs and RAG — in Real-Time!
- The 4 Advanced RAG Algorithms You Must Know to Implement
- Turning Raw Data Into Fine-Tuning Datasets
- 8B Parameters, 1 GPU, No Problems: The Ultimate LLM Fine-tuning Pipeline
- The Engineer’s Framework for LLM & RAG Evaluation
- Beyond Proof of Concept: Building RAG Systems That Scale
- The Ultimate Prompt Monitoring Pipeline
- [Bonus] Build a scalable RAG ingestion pipeline using 74.3% less code
- [Bonus] Build Multi-Index Advanced RAG Apps
Large language models (LLMs) have changed how we interact with machines. These powerful models have a remarkable understanding of human language, enabling them to translate text, write different kinds of creative content formats, and answer your questions in an informative way.
But how do we take these LLMs and make them even better?
The answer lies in fine-tuning.
Fine-tuning is the process of taking a pre-trained LLM and adapting it to a specific task or domain.
One important aspect of fine-tuning is dataset preparation.
Remember the quote from 2018: “garbage in, garbage out.”
The quality of your dataset directly impacts how well your fine-tuned model will perform.
Why does data matter?
Let’s explore why a well-prepared, high-quality dataset is essential for successful LLM fine-tuning:
- Specificity is Key: LLMs like Mistral are trained on massive amounts of general text data. This gives them a broad understanding of language, but it doesn’t always align with the specific task you want the model to perform. A carefully curated dataset helps the model understand the nuances of your domain, vocabulary, and the types of outputs you expect.
- Contextual Learning: High-quality datasets offer rich context that the LLM can use to learn patterns and relationships between words within your domain. This context enables the model to generate more relevant and accurate responses for your specific application.
- Avoiding Bias: Unbalanced or poorly curated datasets can introduce biases into the LLM, impacting its performance and leading to unfair or undesirable results. A well-prepared dataset helps to mitigate these risks.
Today, we will learn how to generate a custom dataset for our specific task, which is content generation.
Understanding the Data Types
Our data consists of two primary types: posts and articles. Each type serves a different purpose and is structured to accommodate specific needs:
- Posts: Typically shorter and more dynamic, posts are often user-generated content from social platforms or forums. They are characterized by varied formats and informal language, capturing real-time user interactions and opinions.
- Articles: These are more structured and content-rich, usually sourced from news outlets or blogs. Articles provide in-depth analysis or reporting and are formatted to include headings, subheadings, and multiple paragraphs, offering comprehensive information on specific topics.
- Code: Sourced from repositories like GitHub, this data type encompasses scripts and programming snippets crucial for LLMs to learn and understand technical language
Both data types require careful handling during insertion to preserve their integrity and ensure they are stored correctly for further processing and analysis in MongoDB. This includes managing formatting issues and ensuring data consistency across the database.
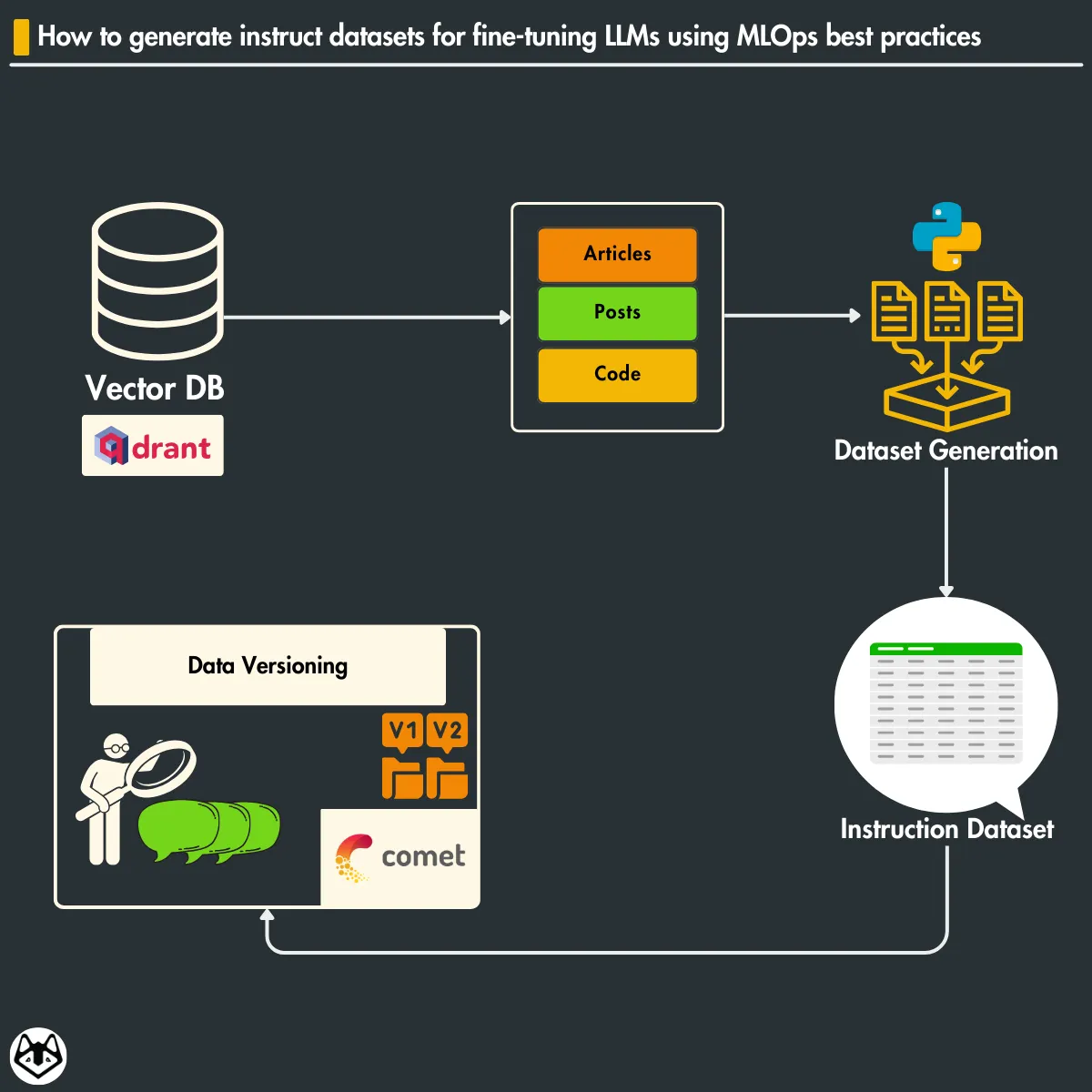
Table of Contents
🔗 Check out the code on GitHub [1] and support us with a ⭐️
1. Generating fine-tuning instruct datasets
- The Challenge: Manually creating a dataset for fine-tuning a language model like Mistral-7B can be time-consuming and prone to errors.
- The Solution: Instruction Datasets Instruction datasets offer an efficient way to guide a language model toward a specific task like news classification.
- Methods: While instruction datasets can be built manually or derived from existing sources, we’ll leverage a powerful LLM like OpenAI’s GPT 3.5-turbo due to our time and budget constraints.
Using the cleaned data from Qdrant
Let’s analyze the sample data point from Qdrant to demonstrate how we can derive instructions for generating our instruction dataset (which we cleaned within our feature pipeline in Lesson 4):
{
"author_id": "2",
"cleaned_content": "Do you want to learn to build hands-on LLM systems using good LLMOps practices? A new Medium series is coming up for the Hands-on LLMs course\n.\nBy finishing the Hands-On LLMs free course, you will learn how to use the 3-pipeline architecture & LLMOps good practices to design, build, and deploy a real-time financial advisor powered by LLMs & vector DBs.\nWe will primarily focus on the engineering & MLOps aspects.\nThus, by the end of this series, you will know how to build & deploy a real ML system, not some isolated code in Notebooks.\nThere are 3 components you will learn to build during the course:\n- a real-time streaming pipeline\n- a fine-tuning pipeline\n- an inference pipeline\n.\nWe have already released the code and video lessons of the Hands-on LLM course.\nBut we are excited to announce an 8-lesson Medium series that will dive deep into the code and explain everything step-by-step.\nWe have already released the first lesson of the series \nThe LLMs kit: Build a production-ready real-time financial advisor system using streaming pipelines, RAG, and LLMOps: \n[URL]\n In Lesson 1, you will learn how to design a financial assistant using the 3-pipeline architecture (also known as the FTI architecture), powered by:\n- LLMs\n- vector DBs\n- a streaming engine\n- LLMOps\n.\n The rest of the articles will be released by the end of January 2024.\nFollow us on Medium's Decoding ML publication to get notified when we publish the other lessons: \n[URL]\nhashtag\n#\nmachinelearning\nhashtag\n#\nmlops\nhashtag\n#\ndatascience",
"platform": "linkedin",
"type": "posts"
},
{
"author_id": "2",
"cleaned_content": "RAG systems are far from perfect This free course teaches you how to improve your RAG system.\nI recently finished the Advanced Retrieval for AI with Chroma free course from\nDeepLearning.AI\nIf you are into RAG, I find it among the most valuable learning sources.\nThe course already assumes you know what RAG is.\nIts primary focus is to show you all the current issues of RAG and why it is far from perfect.\nAfterward, it shows you the latest SoTA techniques to improve your RAG system, such as:\n- query expansion\n- cross-encoder re-ranking\n- embedding adaptors\nI am not affiliated with\nDeepLearning.AI\n(I wouldn't mind though).\nThis is a great course you should take if you are into RAG systems.\nThe good news is that it is free and takes only 1 hour.\nCheck it out \n Advanced Retrieval for AI with Chroma:\n[URL]\nhashtag\n#\nmachinelearning\nhashtag\n#\nmlops\nhashtag\n#\ndatascience\n.\n Follow me for daily lessons about ML engineering and MLOps.[URL]",
"image": null,
"platform": "linkedin",
"type": "posts"
} Process:
Generating instructions: We can leverage the “cleaned_content” to automatically generate instructions (using GPT-4o or other LLM) for each piece of content, such as:
- Instruction 1: “Write a LinkedIn post promoting a new educational course on building LLM systems focusing on LLMOps. Use relevant hashtags and a tone that is both informative and engaging.”
- Instruction 2: “Write a LinkedIn post explaining the benefits of using LLMs and vector databases in real-time financial advising applications. Highlight the importance of LLMOps for successful deployment.”
Generating the dataset with GPT-4o
The process can be split into 3 main stages:
- Query the Qdrant vector DB for cleaned content.
- Split it into smaller, more granular paragraphs.
- Feed each paragraph to GPT-4o to generate an instruction.
Result: This process would yield a dataset of instruction-output pairs designed to fine-tune a Llama 3.1 8B (or other LLM) for tweaking the writing style of the LLM.
Let’s dig into the code!
The example will simulate creating a training dataset for an LLM using the strategy we’ve explained above.
Imagine that we want to go from this ↓
{
"author_id": "2",
"cleaned_content": "Do you want to learn to build hands-on LLM systems using good LLMOps practices? A new Medium series is coming up for the Hands-on LLMs course\n.\nBy finishing the Hands-On LLMs free course, you will learn how to use the 3-pipeline architecture & LLMOps good practices to design, build, and deploy a real-time financial advisor powered by LLMs & vector DBs.\nWe will primarily focus on the engineering & MLOps aspects.\nThus, by the end of this series, you will know how to build & deploy a real ML system, not some isolated code in Notebooks.\nThere are 3 components you will learn to build during the course:\n- a real-time streaming pipeline\n- a fine-tuning pipeline\n- an inference pipeline\n.\nWe have already released the code and video lessons of the Hands-on LLM course.\nBut we are excited to announce an 8-lesson Medium series that will dive deep into the code and explain everything step-by-step.\nWe have already released the first lesson of the series \nThe LLMs kit: Build a production-ready real-time financial advisor system using streaming pipelines, RAG, and LLMOps: \n[URL]\n In Lesson 1, you will learn how to design a financial assistant using the 3-pipeline architecture (also known as the FTI architecture), powered by:\n- LLMs\n- vector DBs\n- a streaming engine\n- LLMOps\n.\n The rest of the articles will be released by the end of January 2024.\nFollow us on Medium's Decoding ML publication to get notified when we publish the other lessons: \n[URL]\nhashtag\n#\nmachinelearning\nhashtag\n#\nmlops\nhashtag\n#\ndatascience",
},
{
"author_id": "2",
"cleaned_content": "RAG systems are far from perfect This free course teaches you how to improve your RAG system.\nI recently finished the Advanced Retrieval for AI with Chroma free course from\nDeepLearning.AI\nIf you are into RAG, I find it among the most valuable learning sources.\nThe course already assumes you know what RAG is.\nIts primary focus is to show you all the current issues of RAG and why it is far from perfect.\nAfterward, it shows you the latest SoTA techniques to improve your RAG system, such as:\n- query expansion\n- cross-encoder re-ranking\n- embedding adaptors\nI am not affiliated with\nDeepLearning.AI\n(I wouldn't mind though).\nThis is a great course you should take if you are into RAG systems.\nThe good news is that it is free and takes only 1 hour.\nCheck it out \n Advanced Retrieval for AI with Chroma:\n[URL]\nhashtag\n#\nmachinelearning\nhashtag\n#\nmlops\nhashtag\n#\ndatascience\n.\n Follow me for daily lessons about ML engineering and MLOps.[URL]",
} to this ↓
[
{
"instruction": "Share the announcement of the upcoming Medium series on building hands-on LLM systems using good LLMOps practices, focusing on the 3-pipeline architecture and real-time financial advisor development. Follow the Decoding ML publication on Medium for notifications on future lessons.",
"content": "Do you want to learn to build hands-on LLM systems using good LLMOps practices? A new Medium series is coming up for the Hands-on LLMs course\n.\nBy finishing the Hands-On LLMs free course, you will learn how to use the 3-pipeline architecture & LLMOps good practices to design, build, and deploy a real-time financial advisor powered by LLMs & vector DBs.\nWe will primarily focus on the engineering & MLOps aspects.\nThus, by the end of this series, you will know how to build & deploy a real ML system, not some isolated code in Notebooks.\nThere are 3 components you will learn to build during the course:\n- a real-time streaming pipeline\n- a fine-tuning pipeline\n- an inference pipeline\n.\nWe have already released the code and video lessons of the Hands-on LLM course.\nBut we are excited to announce an 8-lesson Medium series that will dive deep into the code and explain everything step-by-step.\nWe have already released the first lesson of the series \nThe LLMs kit: Build a production-ready real-time financial advisor system using streaming pipelines, RAG, and LLMOps: \n[URL]\n In Lesson 1, you will learn how to design a financial assistant using the 3-pipeline architecture (also known as the FTI architecture), powered by:\n- LLMs\n- vector DBs\n- a streaming engine\n- LLMOps\n.\n The rest of the articles will be released by the end of January 2024.\nFollow us on Medium's Decoding ML publication to get notified when we publish the other lessons: \n[URL]\nhashtag\n#\nmachinelearning\nhashtag\n#\nmlops\nhashtag\n#\ndatascience"
},
{
"instruction": "Promote the free course 'Advanced Retrieval for AI with Chroma' from DeepLearning.AI that aims to improve RAG systems and takes only 1 hour to complete. Share the course link and encourage followers to check it out for the latest techniques in query expansion, cross-encoder re-ranking, and embedding adaptors.",
"content": "RAG systems are far from perfect This free course teaches you how to improve your RAG system.\nI recently finished the Advanced Retrieval for AI with Chroma free course from\nDeepLearning.AI\nIf you are into RAG, I find it among the most valuable learning sources.\nThe course already assumes you know what RAG is.\nIts primary focus is to show you all the current issues of RAG and why it is far from perfect.\nAfterward, it shows you the latest SoTA techniques to improve your RAG system, such as:\n- query expansion\n- cross-encoder re-ranking\n- embedding adaptors\nI am not affiliated with\nDeepLearning.AI\n(I wouldn't mind though).\nThis is a great course you should take if you are into RAG systems.\nThe good news is that it is free and takes only 1 hour.\nCheck it out \n Advanced Retrieval for AI with Chroma:\n[URL]\nhashtag\n#\nmachinelearning\nhashtag\n#\nmlops\nhashtag\n#\ndatascience\n.\n Follow me for daily lessons about ML engineering and MLOps.[URL]"
},. First, let’s inspect a couple of cleaned documents from which we want to generate instruction-answer data points for SFT fine-tuning:
{
"author_id": "2",
"cleaned_content": "Do you want to learn to build hands-on LLM systems using good LLMOps practices? A new Medium series is coming up for the Hands-on LLMs course\n.\nBy finishing the Hands-On LLMs free course, you will learn how to use the 3-pipeline architecture & LLMOps good practices to design, build, and deploy a real-time financial advisor powered by LLMs & vector DBs.\nWe will primarily focus on the engineering & MLOps aspects.\nThus, by the end of this series, you will know how to build & deploy a real ML system, not some isolated code in Notebooks.\nThere are 3 components you will learn to build during the course:\n- a real-time streaming pipeline\n- a fine-tuning pipeline\n- an inference pipeline\n.\nWe have already released the code and video lessons of the Hands-on LLM course.\nBut we are excited to announce an 8-lesson Medium series that will dive deep into the code and explain everything step-by-step.\nWe have already released the first lesson of the series \nThe LLMs kit: Build a production-ready real-time financial advisor system using streaming pipelines, RAG, and LLMOps: \n[URL]\n In Lesson 1, you will learn how to design a financial assistant using the 3-pipeline architecture (also known as the FTI architecture), powered by:\n- LLMs\n- vector DBs\n- a streaming engine\n- LLMOps\n.\n The rest of the articles will be released by the end of January 2024.\nFollow us on Medium's Decoding ML publication to get notified when we publish the other lessons: \n[URL]\nhashtag\n#\nmachinelearning\nhashtag\n#\nmlops\nhashtag\n#\ndatascience",
"platform": "linkedin",
"type": "posts"
},
{
"author_id": "2",
"cleaned_content": "RAG systems are far from perfect This free course teaches you how to improve your RAG system.\nI recently finished the Advanced Retrieval for AI with Chroma free course from\nDeepLearning.AI\nIf you are into RAG, I find it among the most valuable learning sources.\nThe course already assumes you know what RAG is.\nIts primary focus is to show you all the current issues of RAG and why it is far from perfect.\nAfterward, it shows you the latest SoTA techniques to improve your RAG system, such as:\n- query expansion\n- cross-encoder re-ranking\n- embedding adaptors\nI am not affiliated with\nDeepLearning.AI\n(I wouldn't mind though).\nThis is a great course you should take if you are into RAG systems.\nThe good news is that it is free and takes only 1 hour.\nCheck it out \n Advanced Retrieval for AI with Chroma:\n[URL]\nhashtag\n#\nmachinelearning\nhashtag\n#\nmlops\nhashtag\n#\ndatascience\n.\n Follow me for daily lessons about ML engineering and MLOps.[URL]",
"image": null,
"platform": "linkedin",
"type": "posts"
} We’ll use the DataFormatter class to format these data points into a structured prompt for the LLM.
Here’s how you would use the class to prepare the content:
class DataFormatter:
@classmethod
def get_system_prompt(cls, data_type: str) -> str:
return (
f"I will give you batches of contents of {data_type}. Please generate me exactly 1 instruction for each of them. The {data_type} text "
f"for which you have to generate the instructions is under Content number x lines. Please structure the answer in json format,"
f"ready to be loaded by json.loads(), a list of objects only with fields called instruction and content. For the content field, copy the number of the content only!."
f"Please do not add any extra characters and make sure it is a list with objects in valid json format!\n"
)
@classmethod
def format_data(cls, data_points: list, is_example: bool, start_index: int) -> str:
text = ""
for index, data_point in enumerate(data_points):
if not is_example:
text += f"Content number {start_index + index }\n"
text += str(data_point) + "\n"
return text
@classmethod
def format_batch(cls, context_msg: str, data_points: list, start_index: int) -> str:
delimiter_msg = context_msg
delimiter_msg += cls.format_data(data_points, False, start_index)
return delimiter_msg
@classmethod
def format_prompt(
cls, inference_posts: list, data_type: str, start_index: int
) -> str:
initial_prompt = cls.get_system_prompt(data_type)
initial_prompt += f"You must generate exactly a list of {len(inference_posts)} json objects, using the contents provided under CONTENTS FOR GENERATION\n"
initial_prompt += cls.format_batch(
"\nCONTENTS FOR GENERATION: \n", inference_posts, start_index
)
return initial_prompt Output of the format_prompt function:
prompt = """
I will give you batches of contents of articles.
Please generate me exactly 1 instruction for each of them.
The articles text for which you have to generate the instructions is under Content number x lines.
Please structure the answer in json format,ready to be loaded by json.loads(), a list of objects only with fields called instruction and content.
For the content field, copy the number of the content only!
Please do not add any extra characters and make sure it is a list with objects in valid json format!\n
You must generate exactly a list of 3 json objects, using the contents provided under CONTENTS FOR GENERATION\n
CONTENTS FOR GENERATION:
Content number 0
...
Content number 1
...
Content number 2
...
Content number MAX_BATCH
... We batch the data into multiple prompts to avoid hitting the maximum number of tokens. Thus, we will send multiple prompts to the LLM.
To automate the generation of fine tuning data, we designed the DatasetGenerator class. This class is designed to streamline the process from fetching data to logging the training data into Comet:
class DatasetGenerator:
def __init__(
self,
file_handler: FileHandler,
api_communicator: GptCommunicator,
data_formatter: DataFormatter,
) -> None:
self.file_handler = file_handler
self.api_communicator = api_communicator
self.data_formatter = data_formatter The generate_training_data() method from the DatasetGenerator class handles the entire lifecycle of data generation and calls the LLM for each batch:
def generate_training_data(
self, collection_name: str, data_type: str, batch_size: int = 3
) -> None:
assert (
settings.COMET_API_KEY
), "COMET_API_KEY must be set in settings, fill it in your .env file."
assert (
settings.COMET_WORKSPACE
), "COMET_PROJECT must be set in settings, fill it in your .env file."
assert (
settings.COMET_WORKSPACE
), "COMET_PROJECT must be set in settings, fill it in your .env file."
assert (
settings.OPENAI_API_KEY
), "OPENAI_API_KEY must be set in settings, fill it in your .env file."
cleaned_documents = self.fetch_all_cleaned_content(collection_name)
cleaned_documents = chunk_documents(cleaned_documents)
num_cleaned_documents = len(cleaned_documents)
generated_instruct_dataset = []
for i in range(0, num_cleaned_documents, batch_size):
batch = cleaned_documents[i : i + batch_size]
prompt = data_formatter.format_prompt(batch, data_type, i)
batch_instructions = self.api_communicator.send_prompt(prompt)
if len(batch_instructions) != len(batch):
logger.error(
f"Received {len(batch_instructions)} instructions for {len(batch)} documents. \
Skipping this batch..."
)
continue
for instruction, content in zip(batch_instructions, batch):
instruction["content"] = content
generated_instruct_dataset.append(instruction)
train_test_split = self._split_dataset(generated_instruct_dataset)
self.push_to_comet(train_test_split, data_type, collection_name) We could further optimize this by parallelizing the calls on different threads using the ThreadPoolExecutor class from Python. For our small example, doing everything sequentially is fine.
The fetch_all_cleaned_content() method retrieves the cleaned documents from a Qdrant collection:
def fetch_all_cleaned_content(self, collection_name: str) -> list:
all_cleaned_contents = []
scroll_response = client.scroll(collection_name=collection_name, limit=10000)
points = scroll_response[0]
for point in points:
cleaned_content = point.payload["cleaned_content"]
if cleaned_content:
all_cleaned_contents.append(cleaned_content)
return all_cleaned_contents 2. Storing the dataset in a data registry
In this section, we focus on a critical aspect of MLOps: data versioning.
We’ll specifically look at how to implement this using Comet, a platform that facilitates experiment management and reproducibility in machine learning projects.
Comet is a cloud-based platform that provides tools for tracking, comparing, explaining, and optimizing experiments and models in machine learning. CometML helps data scientists and teams to better manage and collaborate on machine learning experiments.
Why Use Comet?
- Artifacts: Leverages artifact management to capture, version, and manage data snapshots and models, which helps maintain data integrity and trace experiment lineage effectively.
- Experiment Tracking: Comet automatically tracks your code, experiments, and results, allowing you to compare between different runs and configurations visually.
- Model Optimization: It offers tools to compare different models side by side, analyze hyperparameters, and track model performance across various metrics.
- Collaboration and Sharing: Share findings and models with colleagues or the ML community, enhancing team collaboration and knowledge transfer.
- Reproducibility: By logging every detail of the experiment setup, Comet ensures experiments are reproducible, making it easier to debug and iterate.
Maybe you’re asking why not to choose MLFlow for example [2]:
- Comet excels in user interface design, providing a clean, intuitive experience for tracking experiments and models.
- It offers robust collaboration tools, making it easier for teams to work together on machine learning projects.
- Comet provides comprehensive security features that help protect data and models, an important consideration for enterprises.
- It has superior scalability, supporting larger datasets and more complex model training scenarios.
- The platform allows for more detailed tracking and analysis of experiments compared to MLflow.
Comet Variables
When integrating Comet into your projects, you’ll need to set up several environment variables to manage the authentication and configuration:
COMET_API_KEY: Your unique API key that authenticates your interactions with the Comet API.COMET_PROJECT: The project name under which your experiments will be logged.COMET_WORKSPACE: The workspace name that organizes various projects and experiments.
The Importance of Data Versioning in MLOps
Data versioning is the practice of keeping a record of multiple versions of datasets used in training machine learning models. This practice is essential for several reasons:
- Reproducibility: It ensures that experiments can be reproduced using the exact same data, which is crucial for validating and comparing machine learning models.
- Model lineage and auditing: If a model’s performance changes unexpectedly, data versioning allows teams to revert to previous data states to identify issues.
- Collaboration and Experimentation: Teams can experiment with different data versions to see how changes affect model performance without losing the original data setups.
- Regulatory Compliance: In many industries, keeping track of data modifications and training environments is required for compliance with regulations.
Comet’s Artifacts
- Version Control: Artifacts in Comet are versioned, allowing you to track changes and iterate on datasets and models efficiently.
- Immutability: Once created, artifacts are immutable, ensuring that data integrity is maintained throughout the lifecycle of your projects.
- Metadata and Tagging: You can enhance artifacts with metadata and tags, making them easier to search and organize within Comet.
- Alias Management: Artifacts can be assigned aliases to simplify references to versions, streamlining workflow and reference.
- External Storage: Supports integration with external storage solutions like Amazon S3, enabling scalable and secure data management.
The provided push_to_comet function is a key part of this process.
def push_to_comet(
self,
train_test_split: tuple[list[dict], list[dict]],
data_type: str,
collection_name: str,
output_dir: Path = Path("generated_dataset"),
) -> None:
output_dir.mkdir(exist_ok=True)
try:
logger.info(f"Starting to push data to Comet: {collection_name}")
experiment = start()
training_data, testing_data = train_test_split
file_name_training_data = output_dir / f"{collection_name}_training.json"
file_name_testing_data = output_dir / f"{collection_name}_testing.json"
logging.info(f"Writing training data to file: {file_name_training_data}")
with file_name_training_data.open("w") as f:
json.dump(training_data, f)
logging.info(f"Writing testing data to file: {file_name_testing_data}")
with file_name_testing_data.open("w") as f:
json.dump(testing_data, f)
logger.info("Data written to file successfully")
artifact = Artifact(f"{data_type}-instruct-dataset")
artifact.add(file_name_training_data)
artifact.add(file_name_testing_data)
logger.info(f"Artifact created.")
experiment.log_artifact(artifact)
experiment.end()
logger.info("Artifact pushed to Comet successfully.")
except Exception:
logger.exception(
f"Failed to create Comet artifact and push it to Comet.",
) - Experiment Initialization: An experiment is created using the project settings. This ties all actions, like logging artifacts, to a specific experimental run.
- Data Saving: Data is saved locally as a JSON file. This file format is versatile and widely used, making it a good choice for data interchange.
- Artifact Creation and Logging: An artifact is a versioned object in Comet that can be associated with an experiment. By logging artifacts, you keep a record of all data versions used throughout the project lifecycle.
After running the script that invokes the push_to_comet function, Comet will update with new data artifacts, each representing a different dataset version. This is a crucial step in ensuring that all your data versions are logged and traceable within your MLOps environment.
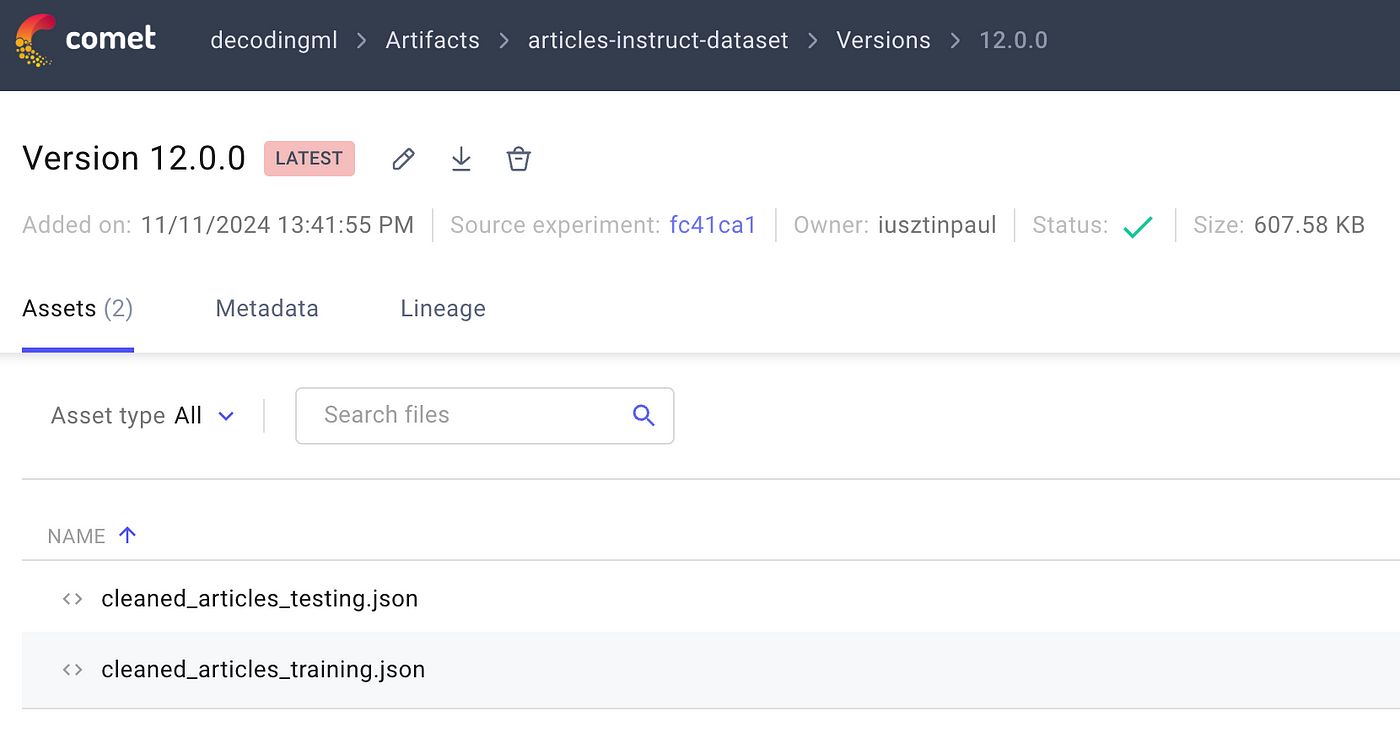
What to Expect in Comet
Here is what you should see in Comet after successfully executing the script:
- Artifacts Section: Navigate to the “Artifacts” tab in your Comet dashboard.
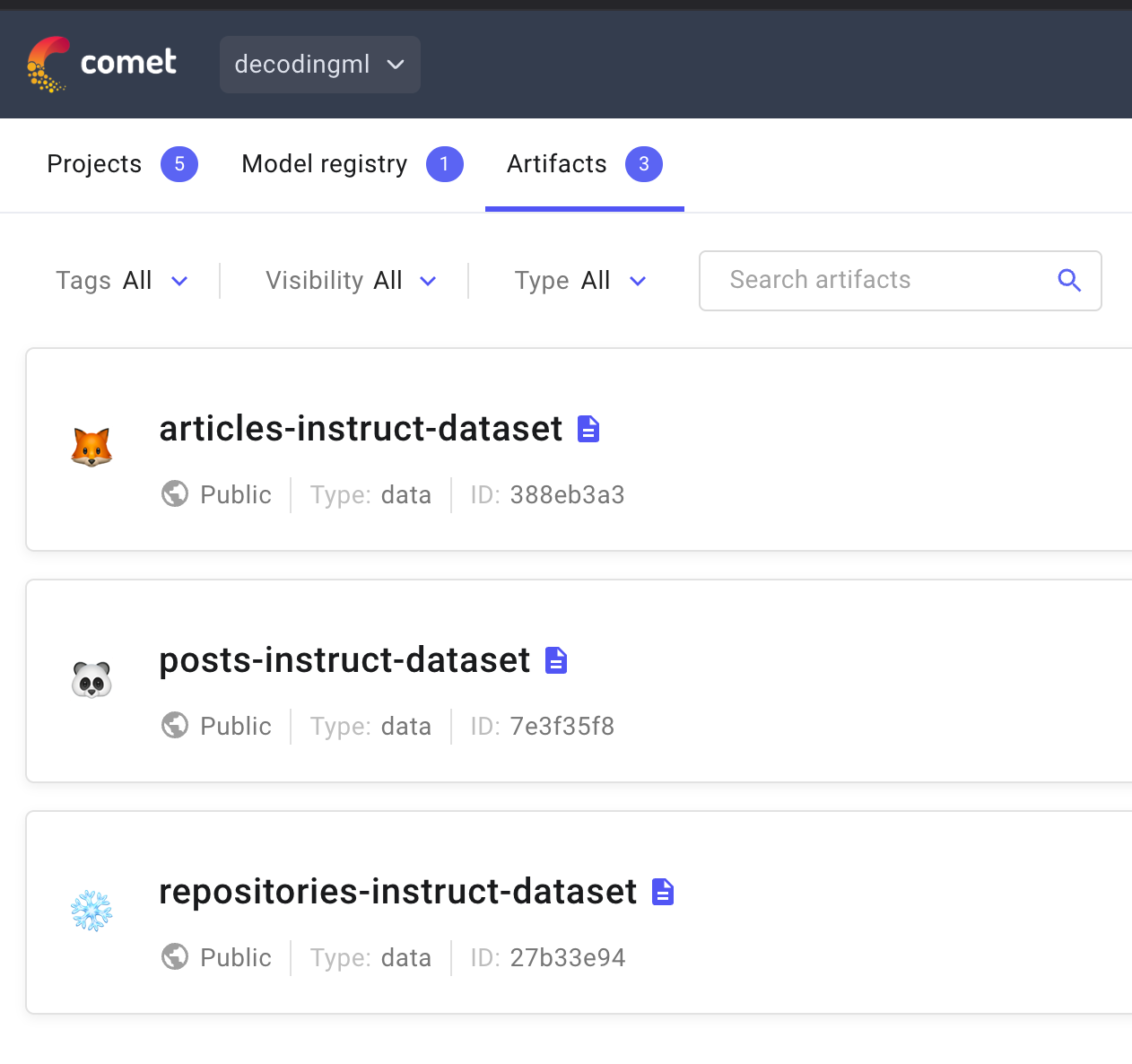
List of Artifacts: You will see entries for each type of data you’ve processed and saved. For example, if you have cleaned and versioned articles and posts, they will appear as separate artifacts.
Artifact Versions: Each artifact can have multiple versions. Each time you run the script with a new or updated dataset, a new version of the respective artifact is created.
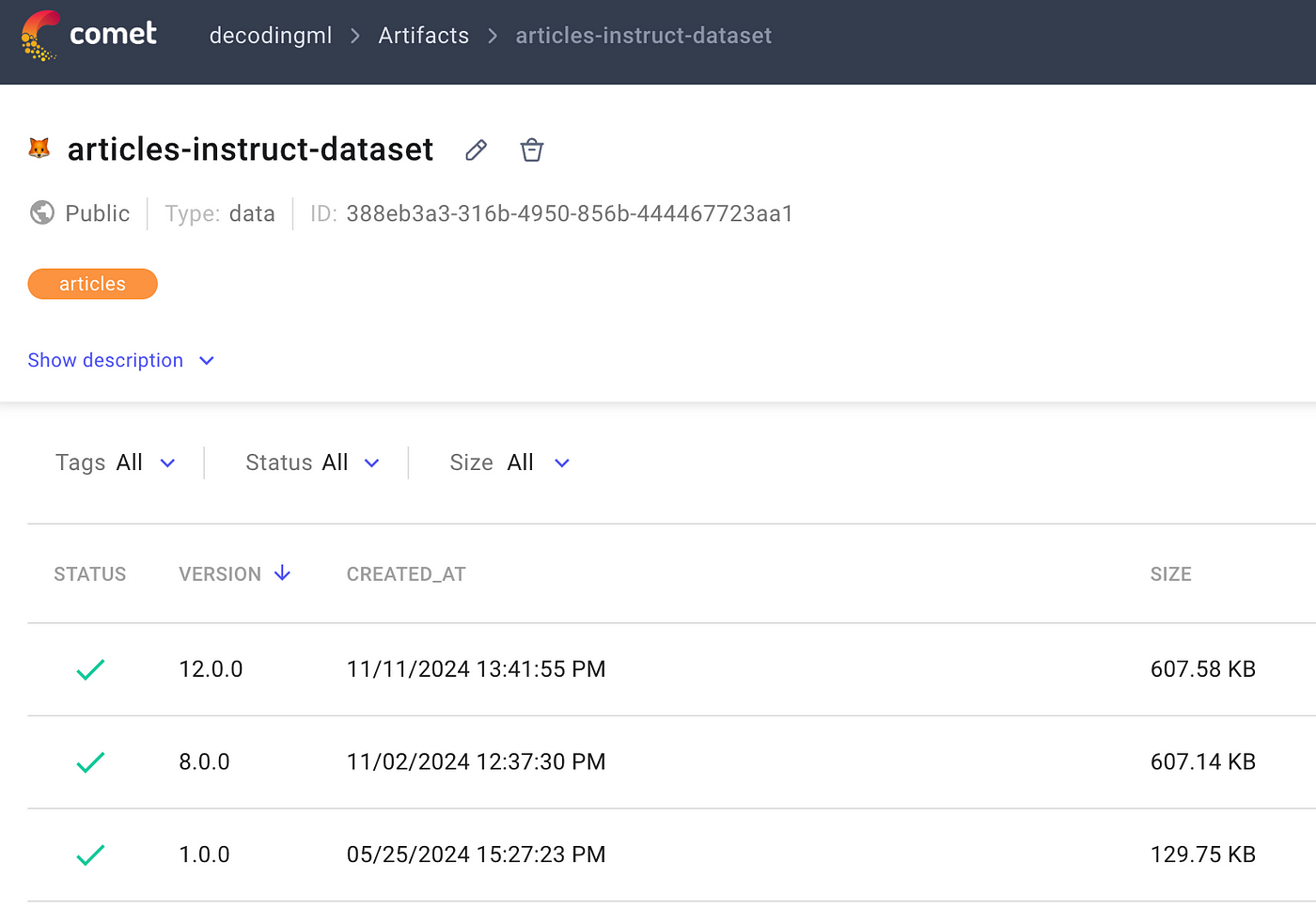
Each version is timestamped and stored with a unique ID, allowing you to track changes over time or revert to previous versions if necessary.
We will have a training and testing JSON file:
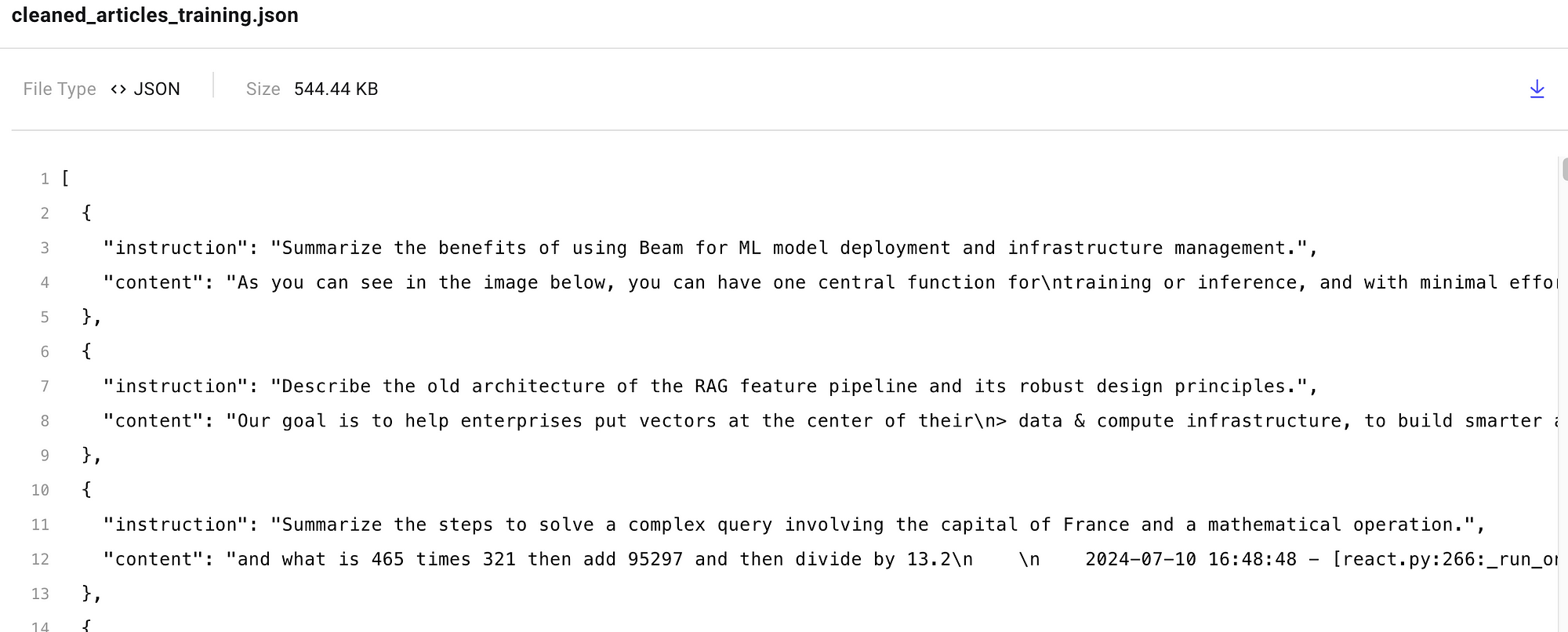
Here’s an example of what the final version of cleaned_articles_training.json might look like, ready for the fine-tuning task:
Also, we made our artifacts publicly available, so you can take a look, play around with them, and even use them to fine-tune the LLM in case you don’t want to compute them yourself:
Conclusion
This lesson taught you how to generate custom instruct datasets from your raw data using other LLMs.
Also, we’ve shown you how to load the dataset to a data registry, such as Comet ML’s artifacts, to version, track, and share it within your system.
In Lesson 7, you will learn to use the generated dataset to finetune a Llama 3.1 8B LLM as your LLM Twin using Unsloth, TRL and AWS SageMaker.
🔗 Consider checking out the GitHub repository [1] and support us with a ⭐️
References
Literature
[1] Your LLM Twin Course — GitHub Repository (2024), Decoding ML GitHub Organization
[2] MLFlow Alternatives, Neptune.ai
Images
If not otherwise stated, all images are created by the author.

