Ensuring Long-Term Performance and Adaptability of Deployed Models
Introduction
When working on any machine learning problem, data scientists and machine learning engineers usually spend a lot of time on data gathering, efficient data preprocessing, and modeling to build the best model for the use case. Once the best model is identified, it is usually deployed in production to make accurate predictions on real-world data (similar to the one on which the model was trained initially). Ideally, the responsibilities of the ML engineering team should be completed once the model is deployed. But this is only sometimes the case.
In the real world, once the model is deployed, you cannot expect it to perform with the same accuracy, as the data distribution sometimes varies. Factors like changes in user behavior, changing trends, an unseen crisis like COVID-19, etc., can affect the data distribution. This is why you can’t expect model deployment to be a one-time process and move on to another project once the deployment is done.
After the model deployment, you must monitor the model’s performance over a certain period to identify potential issues causing model performance to degrade. Model Drift and Data Drift are two of the main reasons why the ML model’s performance degrades over time. To solve these issues, you must continuously train your model on the new data distribution to keep it up-to-date and accurate. Repeatedly training the model on the new data distribution is called Model Retraining.
In this article, you will learn about the common causes of ML model performance degradation, model monitoring, and model retraining as possible solutions.
Next, let’s check out the most common reasons (Model Drift and Data Drift) for model performance degradation in detail.
Model Drift
Model drift, sometimes called concept drift, refers to the phenomenon where the statistical properties of the target variable or the relationship between input variables and target variable change over time. One of the most common times this issue occurs is Fraud Detection, where the model is trained on historical data from one year, but the fraud patterns change in the following year due to new methods fraudsters adopt. The model may continue to make predictions based on the patterns from the previous year, leading to a decrease in its performance.
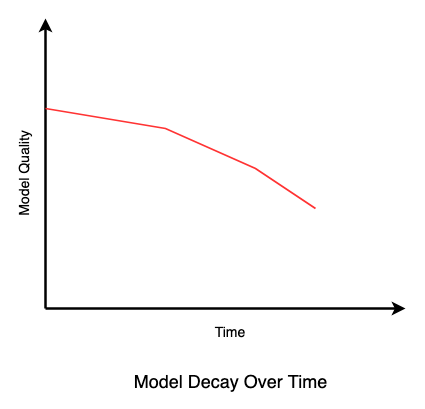
It can happen for various reasons, such as changes in user behavior, environment, or the underlying data generation process. There are different types of model drift in machine learning, including:
- Sudden Drift: This type of drift occurs abruptly and results in a sudden shift in the data distribution.
- Gradual Drift: In this type of drift, the changes in the data distribution occur gradually over time, making it difficult to detect.
- Incremental Drift: This drift occurs when new classes or data instances are introduced over time.
- Recurrent Drift: This type of drift occurs when patterns in the data repeat over time but with subtle changes.
- Seasonal Drift: Seasonal drift occurs when the data distribution changes based on a cyclical pattern or a specific time of year.
When trained on a static dataset, the model assumes that the relationship between input and target variables will remain constant in production. However, due to changes in the target distribution, the model does not keep up with the data and fails to generate the correct predictions. This is because the model’s assumptions are no longer valid and cannot adapt to the changing data distribution.
Data Drift
Data drift occurs when the distribution of input data changes over time. One good example of data drift is behavior analysis in online retail applications. An ML model is trained on historical data to predict purchasing behavior, such as the likelihood of a customer making a purchase or the products they are likely interested in. Over time, there can be changes in customer behavior data due to evolving trends, shifts in demographics, or external factors such as economic conditions or cultural influences. This results in a shift in data distribution and leads to data drift.
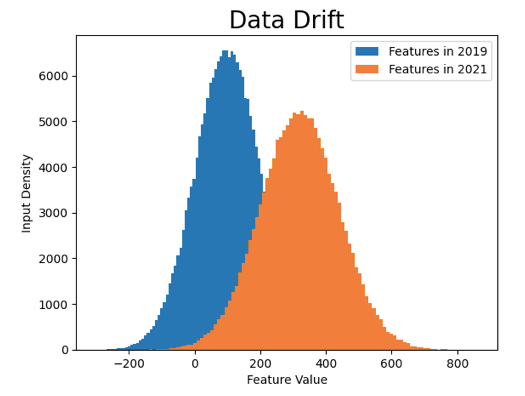
The main reasons that cause data drift to occur are:
- When the characteristics of the population being sampled or observed change over time.
- Presence of outliers in the dataset.
- Changes in the data collection process, measurement techniques, or instrumentation.
- Unforeseen events, interventions, or policy changes can impact the data distribution.
Like concept drift, data drift also causes the model’s performance to degrade over time as the relationships and patterns learned from historical data by models may no longer hold, causing a decrease in prediction accuracy and reliability.
Importance of Retraining Models in Production
Now you know the major issues for the model’s performance degradation in production over time. But, as a data scientist or an ML engineer, you focus on the solutions rather than problems, right? This problem also has a solution: you must retrain your models after a certain period (e.g., weekly, monthly, quarterly, etc.) to keep them updated on new trends and shifts. Training these models on the new data distribution is called model retraining. This helps the model to learn the new patterns in the data that come up as the data distribution changes.
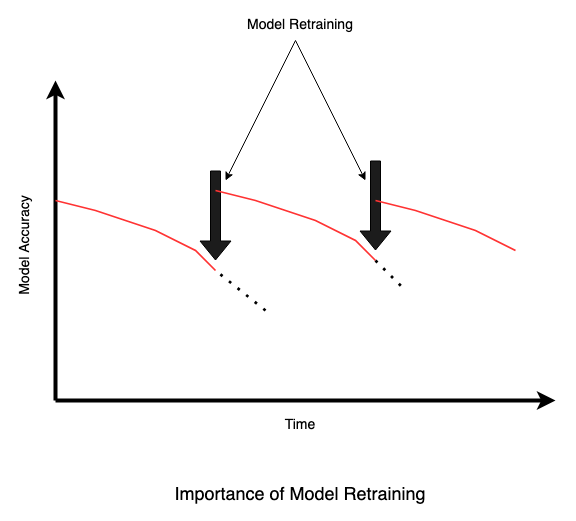
Usually, model retraining can be performed in two ways: Manual and Automated. The support team monitors the model’s performance and predictions in manual model retraining. Suppose there is some degradation in the model’s performance (compared to a predefined threshold). In that case, they inform the teams responsible for retraining the models on the newly collected data (with different distributions). Automated model retraining is more advanced but easy in terms of identifying performance degradation and retraining. This approach integrates various MLOps tools and services into the production environment to monitor the model’s performance. If performance falls below a predefined threshold, these tools automatically start the retraining of the model on the new data distribution. Some popular tools are Comet ML, Neptune, Weights & Biases, etc.
Model retraining can create confusion as we think of two different sides. One is training the same model on the new data distribution, and the other is using a different set of features or a new ML algorithm for the same features. Usually, when an ML solution is deployed to production, feature engineering, model selection, and error calculation are done rigorously, which gives the best model for the use case. This is why, when retraining the model, you don’t need to perform all these stages again. Instead, use the new data distribution and train the existing model on that. Changing the model or features will result in an entirely new solution, which is out of the scope of retraining.
Let’s check out why model retraining is widely adopted across various organizations.
- Improved model accuracy and performance: When the data’s statistical property changes, the ML model’s performance also declines in production. Retraining is now necessary as it incorporates the new and diverse training data. This enables the model to learn from recent examples and better capture the complexities of the problem domain. As the model aligns with the current data distribution, adapts to changing patterns, and leverages new insights, the model’s performance improves.
- Reduced risk of errors and misclassifications: Using an old model with outdated knowledge and assumptions can produce errors and misclassifications and cause mistrust among clients and users. As model retraining brings ML models up to date, the chances of models making errors and misclassified results are much lower.
- Enhanced scalability and efficiency: Retraining enables the model to handle increasing data volumes, make accurate predictions, and process information in a more streamlined and optimized manner. Ultimately, this enhances the overall scalability and efficiency of the machine learning system.
Best Practices for Retraining Models in Production
Now that you know how important it is to retrain models after a specific period, let’s discuss some of the best practices you must follow to make your ML solution more reliable and trusted.
Monitoring Model Performance and Data Quality
You cannot consider model training and deployment a one-time process. After deployment, your work is not done. You must monitor the ML system continuously to check for defects, issues, or errors. If the model fails to perform efficiently, it can be easily identified during monitoring. You also need to monitor the data to check if it is consistent and does not contain any errors. Watching these two things can easily indicate when to retrain the model. You must also decide the performance metric/metrics that will best suit your use case.
Establishing a Retraining Schedule
The first question that comes to the mind of developers is when should I retrain the ML model? and is there a specific trigger? There are different approaches to selecting the proper training schedule:
- Using Performance Trigger: An ML model is only deployed to production when it meets the expected performance. This is where a threshold is decided to assess the model performance. For example, F1-Score > 70indicates an excellent model, while <70 indicates the model needs some tuning. So, in production, when the performance of the model falls below the decided threshold, the model retraining pipeline triggers. As you might have guessed, this approach requires a dedicated monitoring system to be implemented to indicate model performance degradation. Also, you need to collect the data’s ground truth (original label) to calculate the production performance, which can sometimes be challenging.
- When the Data Changes: Data drift is the primary indication for retraining your ML models in production, as part of this schedule, a monitoring system continuously monitors the data distribution, and if any changes are detected, the retraining pipeline is triggered.
- Retrain on Demand: This is a manual approach to retraining the model where the support team manually checks the production model for any performance issues, and if detected, they retrain and redeploy the model.
- Retrain Based on Interval: The production data changes after a specific period for some use cases. For example, in loan repayment prediction, the data may change after every financial year as the policies vary. Due to this periodic change in the data, training the models after a certain period becomes necessary. This training schedule is only needed when you know your data changes periodically.
Choosing the Right Training Data
The relevance of the data is of utmost importance, as it should reflect the problem domain and encompass a diverse range of examples. Additionally, ensuring data quality is essential to avoid noise, errors, or biases that can adversely affect the model’s performance. When retraining the model, you must ensure that you have enough data with almost equal samples belonging to different classes. Also, you need to know how often your data will change. Most importantly, use the data from the same population on which the model was trained initially.
Utilizing Automated Retraining Techniques
Automated retraining techniques automate the retraining models, reducing manual effort, and streamlining the workflow. This approach uses tools like Comet, Neptune, MLFlow, etc., to monitor the entire ML system and retrain the models. This enables the seamless integration of new data and automatically triggers retraining based on predefined schedules or triggers. This ensures that models are regularly updated with fresh data, allowing them to adapt to changing patterns and trends in the data. Using tools can make the process more efficient, reduce time complexity, and reduce the chances of human error.
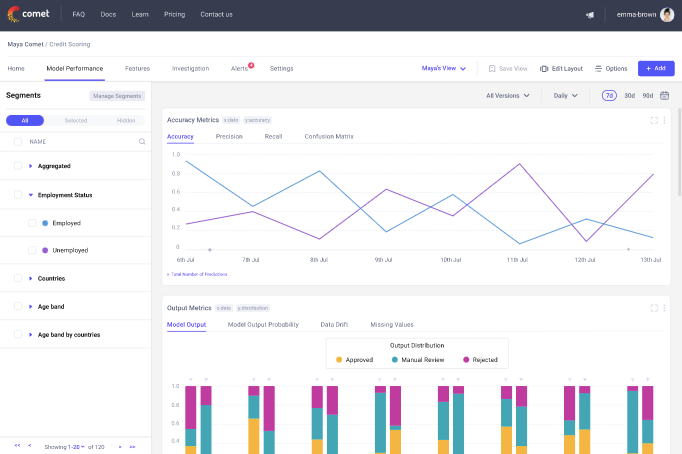
How Comet Can Help?
Model monitoring is the most prominent component of the entire ML lifecycle as it informs you of how your model performs in production and when it will need retraining. Comet is one of the most popular model monitoring tools with ML experimentation, version control, and collaboration capabilities. Comet provides real-time monitoring by capturing and logging predictions, performance metrics, and other relevant information during the model’s runtime. This enables continuous tracking of the model’s behavior and performance on live data.
One of the critical advantages of Comet is its ability to set up alerts and anomaly detection mechanisms. By defining thresholds or using anomaly detection algorithms, you can receive notifications when the model’s predictions deviate from the expected range. Comet’s centralized dashboard provides comprehensive visualizations of performance metrics, allowing you to monitor critical indicators such as accuracy, precision, recall, or custom-defined metrics specific to your use case. It can also track data drift, allowing you to take proactive measures, such as triggering retraining or fine-tuning, to ensure the model remains accurate and effective.

With Comet, you can also set up different alerts that notify you when something goes wrong. For example, when working on a classification use case, you can define a condition based on accuracy or an F1 score. You will receive a notification when the model falls below the specified values.
Comet also promotes collaboration and knowledge sharing among the team, facilitating a collective effort to monitor and maintain the deployed models. Most prominently, Comet can integrate seamlessly with existing infrastructure and monitoring systems, ensuring compatibility and ease of integration within your production environment.
It’s easy to monitor models in production using Comet’s features, and model retraining becomes easy. You can read more about Comet for model monitoring here.
Conclusion
After reading this article, you know that regularly retraining models is crucial for maintaining accuracy, adapting to changing data patterns, and addressing the risk of model decay over time. By retraining models, organizations can harness the power of new data and improve model performance, leading to better predictions and decision-making in real-world scenarios. Also, you are now aware that model monitoring in production is the key to retraining the models.
While multiple MLOps solutions are available in the market, Comet is one of the best, with features like tracking and monitoring model performance, comparing different experiments, detecting anomalies, alerting and incident response, and responding quickly to issues. By embracing the importance of model retraining in production, combined with the power of Comet, organizations can stay at the forefront of machine learning advancements and deliver robust and dependable models for real-world applications.
If you have any questions, you can connect with me on LinkedIn or Twitter; thanks.
