A Guide to Metrics and Stuffing Strategy Assessment

In this post, you will learn how to set up and evaluate Retrieval-Augmented Generation (RAG) pipelines using LangChain.
You will explore the impact of different chain types — Map Reduce, Stuff, Refine, and Re-rank — on the performance of your RAG pipeline. This guide is a practical introduction to using the ragas library for RAG pipeline evaluation. Starting with fundamental concepts, you’ll learn how different configurations affect your results.
This post is designed for those with a technical background in natural language processing and AI, offering detailed guidance on optimizing and evaluating RAG pipelines for improved performance.
It’s a bare-bones blog, and my thoughts are not yet fully fleshed out. But this is an excellent introduction to using the ragas library for evaluating your RAG pipelines. In the future, I would like to look at assessing the chunk_size for the RAG metrics. If you’re interested in working with me on a more extensive study of the concepts introduced in this blog, please reach out!
Start by getting some preliminaries out of the way:
%%capture
!pip install langchain openai tiktoken faiss-cpu ragas
import os
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter Your OpenAI API Key:")
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.document_loaders import WebBaseLoader
Now, download some text files that will be put into a vector database. I’ve written about this in other blogs. Feel free to check them out if you do not understand what’s happening below.
In a nutshell, the code loads some websites into document objects, splits them into chunks of 1000 characters each, and puts those chunks into a vector database.
# The websites for the text you want to load
websites = [
"https://www.gutenberg.org/files/56075/56075-h/56075-h.htm#SENECA_OF_A_HAPPY_LIFE",
"https://www.gutenberg.org/files/56075/56075-h/56075-h.htm#SENECA_OF_ANGER",
"https://www.gutenberg.org/files/10661/10661-h/10661-h.htm",
"https://www.gutenberg.org/cache/epub/17183/pg17183-images.html"
]
# Use the WebBaseLoader to create Document objects for each webside
web_loader = WebBaseLoader(websites)
web_docs = web_loader.load()
# Instantiate a text splitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=50
)
web_texts = text_splitter.split_documents(web_docs)
web_db = FAISS.from_documents(
web_texts,
embeddings,
)
Here’s an example of what one chunk of the split text looks like:
web_texts[42]
Document(page_content=’29\nCHAPTER II.\nSEVERAL SORTS OF BENEFITS.\nWe shall divide benefits into absolute and vulgar;\r\nthe one appertaining to good life, the other is only\r\nmatter of commerce. The former are the more excellent,\r\nbecause they can never be made void; whereas\r\nall material benefits are tossed back and forward,\r\nand change their master. There are some offices\r\nthat look like benefits, but are only desirable conveniences,\r\nas wealth, etc., and these a wicked man\r\nmay receive from a good, or a good man from an\r\nevil. Others, again, that bear the face of injuries,\r\nwhich are only benefits ill taken; as cutting, lancing,\r\nburning, under the hand of a surgeon. The greatest\r\nbenefits of all are those of good education, which\r\nwe receive from our parents, either in the state of\r\nignorance or perverseness; as, their care and tenderness\r\nin our infancy; their discipline in our childhood,\r\nto keep us to our duties by fear; and, if fair means\r\nwill not do, their proceeding afterwards to severity’, metadata={‘source’: ‘https://www.gutenberg.org/files/56075/56075-h/56075-h.htm#SENECA_OF_A_HAPPY_LIFE', ‘title’: “The Project Gutenberg eBook of Seneca’s Morals of a Happy Life, Benefits, Anger and Clemency, by Lucius Annaeus Seneca”, ‘language’: ‘No language found.’})
The code below sets up a RetrievalQA chain, which will be used to retrieve documents using one of four strategies:
- Map reduce
- Stuff
- Refine
- Re-rank
For this blog post, you’ll use the following question to retrieve relevant documents from the vector database.
question = "What does Seneca say are the qualities of a happy life and how can happiness be achieved?"
def get_chain_result(chain_type, llm, retriever, question):
"""
Initialize a chain of the specified type and invoke it with the given question.
Parameters:
- chain_type (str): The type of the chain (e.g., "map_reduce", "stuff", "refine", "map_rerank").
- llm: The language model.
- retriever: The retriever object.
- question (str): The question to be asked.
Returns:
- dict: The result of invoking the chain with the question.
"""
chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type=chain_type,
retriever=retriever,
verbose=True,
return_source_documents=True
)
result = chain.invoke(question)
return result
retriever = web_db.as_retriever()
Want to learn how to build modern software with LLMs using the newest tools and techniques in the field? Check out this free LLMOps course from industry expert Elvis Saravia of DAIR.AI!
Map Reduce
Consists of a map step, where each document is individually summarized, and a reduce step where these mini-summaries are combined. An optional compression step can be added.
This method runs an initial prompt on each chunk of data and then uses a different prompt to combine all the initial outputs.
map_reduce separates texts into batches, where you can define the batch size (i.e. llm=OpenAI(batch_size=5)).
It feeds each batch with the question to LLM separately and comes up with the final answer based on the answers from each batch.
Pros: It can scale to more documents and documents of larger length. Since the calls to the LLM are on independent, individual documents they can be parallelized.
Cons: This requires more calls to the LLM. You can also get some information during the final combined call.
The code below will run a
map_reduce_result = get_chain_result("map_reduce", llm, retriever, question)
map_reduce_result['result']
According to the provided text, Seneca views wisdom and virtue as the qualities of a happy life. Happiness can be achieved by first understanding what one ought to do (wisdom) and then living in accordance with that knowledge (virtue).
Stuff
Takes multiple small documents and combines them into a single prompt for the LLM. It is cost-efficient because it involves only one request to the LLM.

The chain_type “stuff” is the simplest method. It uses all related text from the documents as the context in the prompt to the LLM.
Pros: You only make a single call to the LLM. And when it generates text, it has access to all the data simultaneously. It’s cost-efficient since you only make one call to the LLM
Cons: This can sometimes exceed the token limit for a LLM.
Use this when you have a bunch of small documents and not too many of them.
stuff_result = get_chain_result("stuff", llm, retriever, question)
stuff_result['result']
Seneca states that happiness is founded upon wisdom and virtue. To achieve happiness, one must first know what they ought to do and then live according to that knowledge. He emphasizes the importance of philosophy and precept as aids toward a happy life, as well as the blessing of a good conscience. According to Seneca, a good man can never be miserable, nor a wicked man happy, and no man is unfortunate if he cheerfully submits to Providence.
Refine
Looks at each document individually and updates its answer with each new document.

It is useful when there are too many documents, but it can be slow and confusing if they reference each other.
“refine” also separates texts into batches, but it feeds the first batch to LLM, the answer, and the second to LLM.
It refines the answer by going through all the batches.
refine_results = get_chain_result("refine", llm, retriever, question)
refine_results['result']
With the additional context from Seneca’s Chapter IX, “Of Levity of Mind, and Other Impediments of a Happy Life,” we gain a clearer understanding of Seneca’s perspective on the qualities of a happy life and how happiness can be achieved. The refined answer, incorporating the new information, would be as follows:
Seneca, the Stoic philosopher, posits that the foundation of a happy life is built upon wisdom and virtue. To achieve happiness, one must first comprehend what is right and proper (wisdom), and then live in accordance with that understanding (virtue). Happiness, in Seneca’s view, is not a matter of external circumstances but is intrinsically linked to one’s inner moral state and the quality of one’s character.
The guidance of philosophy and the instruction of precepts are instrumental in leading one towards a life of happiness. These help individuals to cultivate the wisdom and virtue necessary to live in harmony with nature and their own rational nature.
A critical quality of a happy life, according to Seneca, is the possession of a good conscience. A person who acts rightly will maintain inner peace and contentment, knowing that their actions align with their values and understanding of what is good.
Another quality is the cheerful submission to Providence. Seneca emphasizes that a person who accepts their fate and understands the role of Providence in their life will not be disturbed by misfortunes. In Stoic thought, Providence refers to the rational order of the universe, and aligning oneself with this order is key to tranquility.
Seneca also warns against a life lived without purpose or design — likening it to straws carried aimlessly by the current of a river. Instead, he advocates for a life lived with intention and reflection, considering not just the parts of life but its entirety.
In summary, Seneca’s conception of a happy life arises from a deep engagement with philosophy, the cultivation of virtue, living with intention, and maintaining a good conscience. Moreover, he stresses the importance of accepting one’s role in the greater scheme of things (Providence) and understanding that a virtuous person cannot truly be unhappy, just as a wicked person cannot be truly happy. Living with wisdom and virtue ensures that one is not carried haphazardly through life but instead navigates it with purpose and moral clarity.
Map Re-rank
Tries to get an answer for each document and assigns it a confidence score, picking the highest confidence answer in the end.

“map-rerank” separates texts into batches, feeds each batch to LLM, returns a score of how fully it answers the question, and comes up with the final answer based on the high-scored answers from each batch.
rerank_results = get_chain_result("map_rerank", llm, retriever, question)
rerank_results['result']
Happiness is founded upon wisdom and virtue. One must first know what to do and then live according to that knowledge. Philosophy and precept are helpful toward a happy life, as is the blessing of a good conscience. A good man can never be miserable, nor a wicked man happy. Happiness is also achieved by cheerfully submitting to Providence.
Introduction to ragas
The ragas library evaluates Retrieval-Augmented Generation (RAG) pipelines, particularly within the LangChain framework.
It utilizes Large Language Models (LLMs) to conduct evaluations across various metrics, each addressing a specific aspect of the RAG pipeline’s performance:
1. Faithfulness: Assesses the factual accuracy of the generated answer about the provided context.
2. Answer Relevancy: Measures the relevance of the generated answer to the posed question.
3. Context Relevancy: Evaluate the signal-to-noise ratio in retrieved contexts.
Ragas uses different methods to leverage LLMs, effectively measuring these aspects while overcoming inherent biases. The library stands out for its ability to provide nuanced insights into the effectiveness of RAG pipelines. It is a valuable tool for developers and researchers working on enhancing the accuracy and relevance of AI-generated content.
In the code snippet below, the Ragas library evaluates different strategies in a RAG pipeline.
The code imports metrics such as faithfulness, answer relevancy, and context relevancy and then sets up evaluator chains for each metric using RagasEvaluatorChain. These chains are stored in a dictionary named eval_chains. The function evaluate_strategy takes a strategy, and the evaluator chains as inputs and computes scores for each metric. It iterates over each evaluation chain, applies it to the given strategy, and stores the resulting scores in a dictionary, which it returns.
This allows for a comprehensive evaluation of a strategy across multiple relevant metrics.
from ragas.metrics import faithfulness, answer_relevancy, context_relevancy
from ragas.langchain import RagasEvaluatorChain
eval_chains = {
m.name: RagasEvaluatorChain(metric=m)
for m in [faithfulness, answer_relevancy, context_relevancy]
}
def evaluate_strategy(strategy, eval_chains):
"""
Evaluate a given strategy using the provided evaluation chains.
Parameters:
- strategy (dict): The strategy to be evaluated.
- eval_chains (dict): A dictionary of evaluation chains.
Returns:
- dict: A dictionary containing scores for the given strategy.
"""
scores = {}
for name, eval_chain in eval_chains.items():
score_name = f"{name}_score"
#Evaluate the strategy using the eval_chain
evaluation_result = eval_chain(strategy)
#Retrieve the specific score from the evaluation result
specific_score = evaluation_result[score_name]
#Store this score in the scores dictionary
scores[score_name] = specific_score
return scores
# List of strategies
strategies = [stuff_result, refine_results, rerank_results, map_reduce_result]
strategy_names = ['stuff_result', 'refine_results', 'rerank_results', 'map_reduce_result']
# Collect scores for each strategy
results = []
for strategy, strategy_name in zip(strategies, strategy_names):
scores = evaluate_strategy(strategy, eval_chains)
scores['result_type'] = strategy_name # Add the strategy name as 'result_type'
results.append(scores)
The following code is a helper function to plot the resulting metrics:
def plot_evaluation_score(results, metric):
"""
Plot evaluation scores for a specific metric from a list of dictionaries.
Parameters:
- results (list): A list of dictionaries containing evaluation scores.
- metric (str): The specific metric to plot.
"""
# Extract scores for the given metric
scores = [result[metric] for result in results]
# Plotting
plt.figure(figsize=(10, 6))
plt.bar(range(len(results)), scores, tick_label=[r['result_type'] for r in results])
# Customizing the chart
plt.title(f'Evaluation Scores for {metric}')
plt.ylabel('Score')
plt.xlabel('Strategy')
plt.xticks(rotation=45)
plt.tight_layout()
# Display the chart
plt.show()
Now, it’s time to assess the performance of each strategy.
Faithfulness Metric
The faithfulness metric is integral to evaluating the reliability and accuracy of language model outputs in question-answering scenarios.
It ensures that the information provided by AI systems is contextually relevant and factually accurate, which is paramount in applications where decision-making relies on the model’s outputs.
Definition and Purpose
Faithfulness in the context of language models, especially in question-answering systems, measures how accurately and reliably the model’s generated answer adheres to the given context or source material. Ensuring the model’s outputs are relevant, factually correct and consistent with the provided information is crucial.
Calculation Process
- Statement Generation and Identification: The process begins using a Large Language Model (LLM) to analyze the generated answer. This step involves identifying or extracting key statements or assertions in the response. These statements are the crux of the answer and are what the model claims to be true in response to the given question.
- Statement Verification: Another critical step involves verifying these extracted statements against the provided context or source material. This verification is usually done using another LLM or advanced NLP technique. The purpose is to check each statement for accuracy and alignment with the context. This step can involve cross-referencing the statements with facts or data in the context, ensuring that the model’s responses are plausible and factually grounded.
Scoring Mechanism
The faithfulness score is quantified on a scale from 0 to 1, where 0 indicates complete unfaithfulness (none of the statements align with the context), and 1 indicates total faithfulness (the context supports all statements).
The calculation involves counting the number of statements from the generated answer verified as accurate and consistent with the context and dividing this count by the total number of statements made. This ratio gives a precise, quantifiable measure of how faithful the answer is.
Application in ragas
In the ragas framework, as seen from the _faithfulness.py source code, the Faithfulness class incorporates these steps as part of its evaluation chain.
# Plots the 'faithfulness_score' metric
plot_evaluation_score(results, 'faithfulness_score')
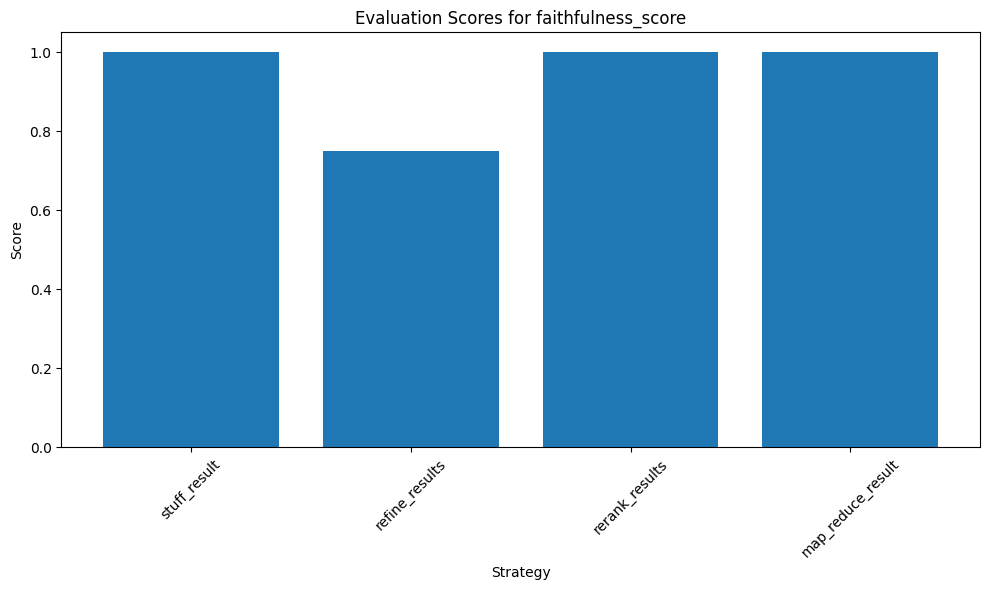
The ‘stuff_result’ and ‘rerank_results’ strategies achieved perfect scores (1.00), indicating a high level of factual accuracy in the context provided.
However, the ‘refine_results’ strategy scored slightly lower, suggesting room for improvement in maintaining factual consistency.
Answer Relevancy
The Answer Relevancy metric is critical in evaluating language models, particularly in question-answering systems.
Focusing on the semantic alignment between the question and the answer ensures that the generated responses are contextually relevant and specifically address the query. This metric is crucial for applications where the accuracy and relevance of LLM-generated responses are paramount.
Definition and Purpose
Answer Relevancy is a metric to evaluate how well a generated answer corresponds to a given question or prompt. It assesses the relevance of the content of the answer in the context of the question, ensuring that the response is accurate and directly addresses the query.
Key Attributes
- Scoring Range: The metric provides a score ranging from 0 to 1, with 1 indicating the highest relevance. A higher score signifies that the answer is more directly relevant to the question posed.
- Completeness and Redundancy: The metric evaluates whether the answer is complete and lacks redundant or unnecessary information. This assessment ensures that the answer is concise and focused on the question.
Calculation Process
- Semantic Analysis via Embeddings: The metric uses embeddings for semantic analysis, which compares the semantic content of the answer to the question.
- Direct Comparison of Question and Answer: The calculation directly compares the actual question and the generated answer. This comparison assesses how well the answer’s content aligns with the question’s subject matter.
Application in ragas
In the ragas framework, the AnswerRelevancy metric forms an integral part of evaluating the performance of AI-generated answers.
The metric ensures that the answers the system provides are contextually appropriate and specifically tailored to the queries they are responding to. Embeddings are a sophisticated approach to understanding the nuances of language and ensuring that the relevancy of answers is accurately captured.
As suggested by the source code, the ragas implementation indicates an advanced use of semantic analysis and NLP techniques to automate and scale this evaluation process.
plot_evaluation_score(results, 'answer_relevancy_score')
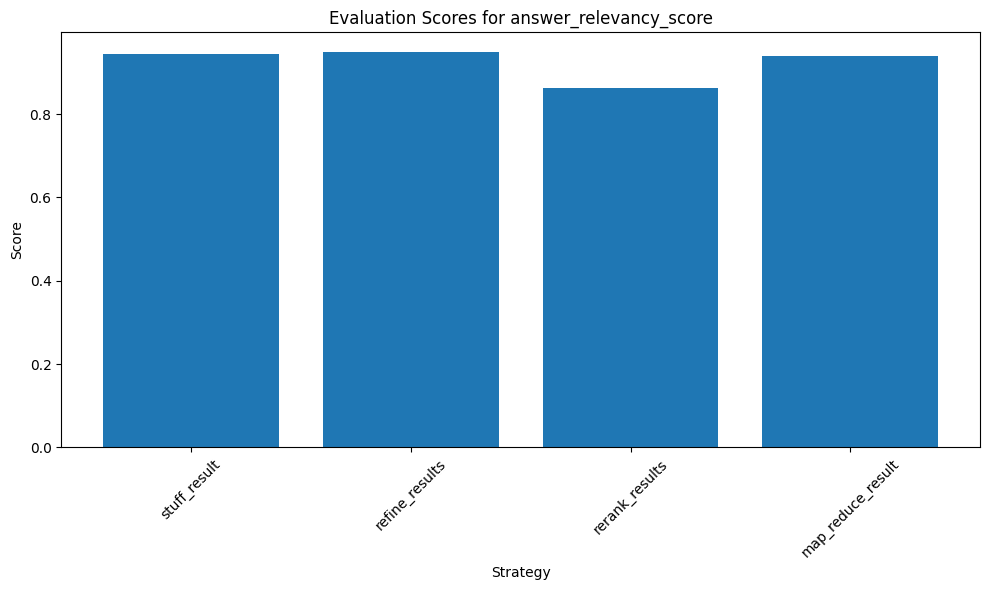
The ‘refine_results’ strategy outperformed others with a score of approximately 0.949, indicating its effectiveness in providing relevant answers to the questions.
The ‘rerank_results’ strategy scored the lowest, suggesting a potential mismatch between the questions and the provided answers.
Context Relevancy
The Context Relevancy metric is critical in evaluating language models, especially in question-answering systems, ensuring that the answers are grounded and supported by relevant context.
By focusing on the relevancy of individual sentences within the context, the metric provides a detailed and nuanced assessment of the context’s usefulness to the question.
Definition and Purpose
Context Relevancy is a metric designed to assess the relevance of the context provided for a given question. It evaluates how well the context supports, relates to, or provides necessary information for answering the question.
Key Attributes and Process
- Scoring Range: The metric scores on a scale from 0 to 1, with higher scores indicating greater context relevance to the question.
- Relevance Evaluation: The metric involves analyzing the sentences in the context to determine their relevance to the question. This process includes (1) Extracting critical sentences from the context and (2) Evaluating these sentences for their direct relevance and support to the question.
Calculation Method
- Sentence Relevance: The source code indicates that the number of relevant sentences is used for scoring. This suggests a quantitative approach where the context is evaluated sentence by sentence.
- Contextual Alignment: The assessment involves checking whether each sentence contributes meaningfully to answering the question or is aligned with the topic of the question.
Application in ragas
Within the ragas framework, the Context Relevancy metric is crucial to ensuring that the AI-generated answers are based on contextually appropriate and relevant information.
As suggested by the source code, the ragas implementation indicates an advanced use of language model capabilities to automate and refine this evaluation process, enhancing the accuracy and reliability of the system’s outputs.
plot_evaluation_score(results, 'context_relevancy_score')
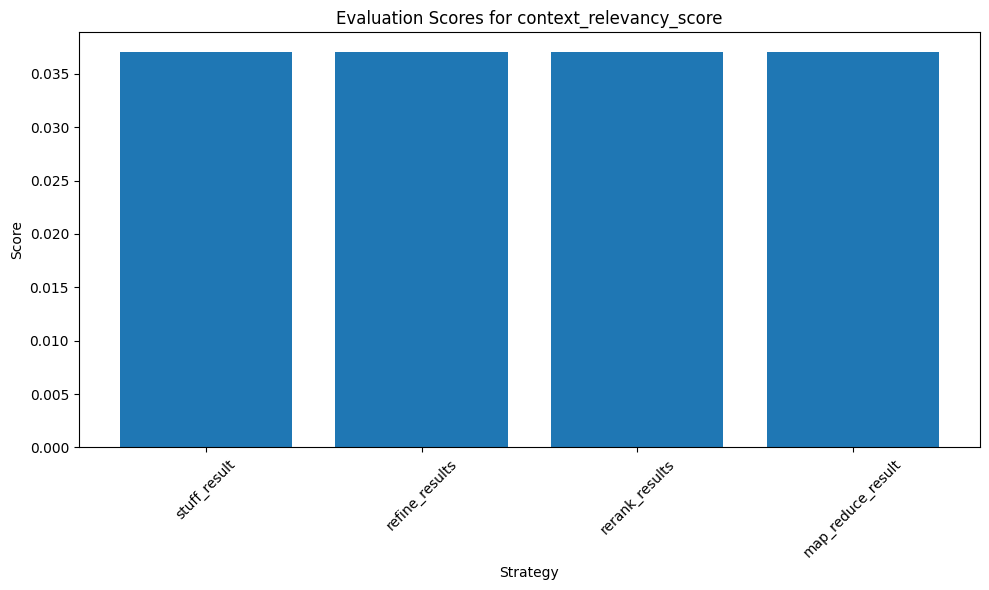
All strategies scored identically (around 0.037), indicating a consistent but lower ability to filter out irrelevant context across all strategies.
These results provide valuable insights into the strengths and weaknesses of each RAG pipeline strategy, with implications for their optimization in real-world applications.
Conclusion
To wrap up, this exploration of the ragas library has equipped you with a clear understanding of how different RAG pipeline strategies perform against critical metrics.
With these insights, you can refine your language models to enhance factual accuracy and relevancy, ensuring that your AI systems deliver precise and reliable outputs. Remember, practical evaluation is critical to advancing the capabilities of LLMs for Retrieval Augmented Generation.
The findings here serve as a testament to ragas’ utility in achieving that goal.
