Large language models have been game-changers in artificial intelligence, but the world is much more than just text. It’s a multi-modal landscape filled with images, audio, and video. These language models are breaking boundaries, venturing into a new era of AI — Multi-Modal Learning.
Join us as we explore this exciting frontier, where language models fuse with sensory data, opening doors to unprecedented possibilities across industries. In a world where words are just the beginning, AI is learning to speak the language of the senses.
Introduction

While large language models have demonstrated their powers in deciphering textual data, our era of the digital world is far more intricate, comprising many more sources like images, audio, videos, and more. To truly harness the potential of artificial intelligence, we must embrace a holistic understanding of these multi-modal inputs.
We delve into how these models, initially tailored for text, have expanded their capabilities to integrate and interpret a diverse array of sensory data seamlessly. From recognizing objects in images to discerning sentiment in audio clips, the amalgamation of language models with multi-modal learning opens doors to uncharted possibilities in AI research, development, and application in industries ranging from healthcare and entertainment to autonomous vehicles and beyond.
Understanding Multi-Modal Learning
Multi-modal learning is a paradigm within artificial intelligence (AI) that extends beyond the boundaries of traditional textual data. At its core, it encompasses integrating and interpreting diverse sensory inputs, including images, audio, videos, and more. This approach aims to equip AI systems with the ability to understand and make sense of the world analogous to human perception, where information is not limited to words but extends to the rich tapestry of sensory experiences like visual, audio, etc.

In multi-modal learning, the challenge lies in fusing information from various modalities and integrating features to extract meaningful insights. This process often involves cross-modal associations, where the AI system learns to connect textual descriptions with visual content or auditory cues. The ultimate goal is to create a more comprehensive and contextually aware understanding of the data, enabling AI systems to process words and perceive and interpret the world holistically. In the following sections, we will delve into the intricacies of multi-modal learning, exploring its methods, applications, and profound impact on AI.
The Rise of Large Language Models
The emergence and proliferation of large language models represent a pivotal chapter in the ongoing AI revolution. These models, powered by massive neural networks, have catalyzed groundbreaking advancements in natural language processing (NLP) and have reshaped the landscape of machine learning. They owe their success to many factors, including substantial computational resources, vast training data, and sophisticated architectures.
One of the standout achievements in this domain is the development of models like GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers). These models have demonstrated an unprecedented capacity to understand and generate human language, surpassing previous benchmarks in tasks such as text completion, translation, and sentiment analysis. The rise of these language models has enabled AI systems to communicate and interact with humans more naturally and contextually sensitively.
However, the influence of large language models extends beyond text alone. Researchers and engineers have recognized the potential to harness the underlying capabilities of these models to interpret and generate other types of data, such as images and audio. This realization has paved the way for integrating large language models with multi-modal learning, a synergy that holds immense promise in unlocking new dimensions of AI capabilities. In the subsequent sections, we will delve deeper into the transformative potential of multi-modal learning and how large language models are expanding their horizons to embrace this multi-sensory frontier.
How Are Large Language Models (LLMs) Expanding Their Horizons?
Expanding large language models into the multi-sensory domain represents a remarkable convergence of AI capabilities. Here’s how LLMs are evolving to embrace multi-modal data:
Multi-Modal Training Data: To tackle multi-modal tasks effectively, LLMs are trained on vast and diverse datasets that include text, images, audio, and even videos. This training process exposes these models to a wide range of sensory information, enabling them to learn to recognize patterns and develop associations across different modalities.
Architectural Adaptations: LLM architectures are evolving to accommodate multi-modal data as input and derive features from them. This involves modifying existing models to incorporate multiple input channels and designing mechanisms to process and integrate information from different sources effectively. These adaptations allow LLMs to handle a broader spectrum of data types.
Cross-Modal Embeddings: LLMs are learning to create cross-modal embeddings, which are representations that connect textual descriptions with visual or auditory content. This means the model can associate words with images or audio, facilitating tasks like image captioning, sentiment analysis in audio clips, and more.
Transfer Learning: LLMs leverage their pre-trained knowledge from textual data to bootstrap their understanding of other modalities. This transfer learning approach allows them to jumpstart their ability to process multi-modal inputs effectively.
Fine-Tuning: LLMs can be fine-tuned on specific multi-modal tasks after pre-training on a diverse dataset. This fine-tuning process refines their ability to perform tasks like image recognition, speech-to-text conversion, or generating text from audio cues.
Hybrid Models: Researchers are exploring hybrid models that combine the strengths of LLMs with specialized neural networks designed for image processing (convolutional neural networks or CNNs) or audio analysis (recurrent neural networks or RNNs). This hybridization allows LLMs to work in synergy with specialized models to handle multi-modal tasks more efficiently.
In summary, large language models are transcending their text-based origins and actively embracing the multi-sensory frontier by adapting their architectures, learning cross-modal embeddings, and extending their capabilities to process and generate content from various sensory inputs.
Examples of LLMs That Have Adapted to Multi-Modal Inputs
Several large language models (LLMs) have adapted to multi-modal data, demonstrating their ability to process and generate content beyond text. Here are some examples:
MAGMA (Multi-modal Augmentation Generative Models): MAGMA based models combine textual and visual modalities for use-cases like document retrieval. MAGMA is a simple method for augmenting language models with other modalities followed by finetuning. It can understand and retrieve documents based on textual queries and images, making it useful for information retrieval tasks where documents contain a mix of text and visual content.
CLIP (Contrastive Language-Image Pre-training): CLIP, developed by OpenAI, is a multi-modal model that can understand images and text. It learns to associate images with their textual descriptions, allowing it to perform tasks like image classification, image generation from text prompts, and even zero-shot image recognition. CLIP has proven highly versatile in understanding the relationship between images and language.

DALL·E: Also developed by OpenAI, DALL·E is a variant of the GPT architecture designed for generating images from textual descriptions. It can generate unique and creative images based on textual prompts, demonstrating its ability to bridge the gap between text and visual content generation.
ViT (Vision Transformer): While initially designed for image classification, ViT models have been fine-tuned for multi-modal tasks. By combining ViT with textual data, researchers have created models to understand and generate text-based descriptions for images, making them valuable for tasks like image captioning.
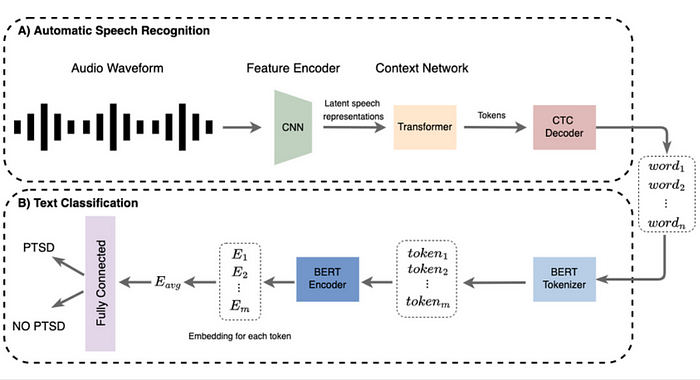
Wav2Vec: Developed by Facebook AI, Wav2Vec is a large-scale audio pre-training model. Although primarily focused on audio data, it can be integrated with text models to perform speech recognition and transcription tasks, effectively bridging the gap between audio and text processing.
UNIMO: UNIMO is a multi-modal model that handles text, image, and audio data. It can simultaneously process and generate content across these modalities, making it suitable for various applications, including content recommendation, multimedia analysis, and more.
These examples showcase the adaptability of large language models to multi-modal data, highlighting their capacity to process and generate content across various sensory inputs, including text, images, audio, and more.
Challenges in Multi-Modal Learning
Multi-modal learning, the convergence of multiple data modalities (e.g., text, images, audio), offers tremendous potential but also presents several unique challenges:
1. Heterogeneous Data Integration: Combining data from different modalities that differ in format, scale, and dimensionality requires careful integration. Ensuring that information from each modality is appropriately aligned and weighted is crucial for accurate multi-modal analysis.
2. Scarcity of Multi-Modal Data: Large-scale multi-modal datasets are relatively scarce compared to their single-modal counterparts. Building high-quality, diverse multi-modal datasets for training can be resource-intensive.
3. Model Complexity: Multi-modal models are inherently more complex than their single-modal counterparts. Designing and training models that can handle multiple data types while maintaining computational efficiency is a significant challenge.
4. Cross-Modal Associations: Teaching models to understand the relationships between different modalities, such as associating words with images or sounds, is a non-trivial task. Learning these associations accurately can be challenging.
5. Semantic Gap: Different modalities may convey information at varying levels of abstraction. Bridging the semantic gap between, for example, high-level textual descriptions and low-level visual features is a complex problem.
6. Data Quality and Noise: Ensuring data quality across modalities is essential. Noisy or mislabeled data in one modality can negatively impact model performance, making quality control a significant challenge.
7. Ethical and Bias Concerns: Multi-modal models, like any AI system, can inherit biases in their training data. Addressing ethical concerns and bias mitigation in multi-modal AI is a critical challenge.
Future Advancements and Trends in LLMs in Combination with Multi-Modal Learning
The future of multi-modal learning with large language models (LLMs) promises to be transformative, with several key trends and developments poised to shape the landscape of artificial intelligence. Here’s an elaboration on some of the future trends in this field:
1. Customized Multi-Modal Models: We can expect the emergence of specialized multi-modal models tailored to specific domains and industries. These models will be fine-tuned to excel in tasks unique to healthcare, autonomous vehicles, entertainment, and more.
2. Privacy-Preserving Multi-Modal AI: As concerns about data privacy grow, there will be a greater emphasis on developing privacy-preserving techniques for multi-modal AI. This includes methods for processing and analyzing data without exposing sensitive information.
3. Improved Cross-Modal Associations: Advances in models’ ability to understand the connections between different modalities will lead to more accurate and contextually relevant multi-modal analysis. This will enhance tasks like image captioning, audio-to-text conversion, and more.
4. Hybrid Architectures: Researchers will continue to explore hybrid architectures that combine the strengths of LLMs with specialized neural networks for better performance in multi-modal tasks. These hybrids will be optimized for efficiency and accuracy.
5. Real-Time Multi-Modal AI: The development of real-time multi-modal AI systems will enable applications in augmented reality, virtual reality, and live streaming, enhancing user experiences across various domains.
6. Ethical AI Governance: The ethical considerations surrounding multi-modal AI, including bias mitigation, fairness, and transparency, will drive the development of governance frameworks and regulatory guidelines to ensure responsible AI deployment.
The future of multi-modal learning with large language models is marked by expansion into new domains, improved capabilities, and a growing emphasis on responsible AI practices.
Conclusion
In the dynamic landscape of artificial intelligence, the convergence of large language models with multi-modal learning has opened doors to a new era of possibilities. This article has explored the transformative journey “Beyond Text,” where AI models, initially designed for processing and generating human language, have extended their capabilities to embrace the diverse world of multi-sensory data.
Multi-modal learning represents a profound shift in AI’s ability to understand and interact with the world. It transcends the boundaries of single-modal analysis, allowing AI systems to perceive and interpret information from text, images, audio, and other modalities simultaneously. The examples of CLIP, DALL·E, ViT, and others showcase the adaptability of these models in understanding and generating content beyond traditional text-based data.
As we look to the future, multi-modal learning promises to reshape industries, from healthcare and entertainment to autonomous vehicles and more. Yet, it also presents challenges, including data integration, model complexity, ethical concerns, and the need for robust evaluation metrics. Addressing these challenges requires collaborative efforts from researchers, developers, and policymakers to ensure multi-modal AI’s responsible and ethical advancement.
In conclusion, combining large language models with multi-modal learning represents a remarkable milestone in AI’s evolution. It is a testament to the field’s relentless pursuit of understanding and emulating the depth and richness of human sensory perception. As AI continues its journey into this multi-sensory frontier, the possibilities are boundless, promising to reshape how we interact with technology and the world around us.
References
Here is a list of references and sources that contributed to the information presented in this article:
1. [OpenAI — CLIP]
2. [OpenAI — DALL·E]
3. [Vision Transformer (ViT) — Paper]
4. [Facebook AI — Wav2Vec]
5. [UNIMO: Universal Multi-modal Understanding]
6. [Visual Language Pre-training (VLP) — Paper]
7. [MARGE: Multi-modal Augmented Generative Encoder]
Please note that this list is not exhaustive, and additional sources and references have been consulted to understand the subject matter comprehensively. Readers are encouraged to explore these references for in-depth information on multi-modal learning and large language models.
