During the evaluation of machine learning (ML) models, the following question might arise:
- Is this model the best one available from the hypothesis space of the algorithm in terms of generalization error on an unknown/future data set?
- What training and testing techniques are used for the model?
- What model should be selected from the available ones?
The hold-out method is used to address these questions.
Consider training a model using an algorithm on a given dataset. Using the same training data, you determine that the trained model has an accuracy of 95% or even 100%. What does this mean? Can this model be used for prediction?
No. This is because your model has been trained on the given data, i.e. it knows the data and has generalized over it very well. In contrast, when you try to predict over a new set of data, it will most likely give you very bad accuracy because it has never seen the data before and thus cannot generalize well over it. To deal with such problems, hold-out methods can be employed.
In this post, we will take a closer look at the hold-out method used during the process of training machine learning models.
What is the Hold-Out Method?
The hold-out method involves splitting the data into multiple parts and using one part for training the model and the rest for validating and testing it. It can be used for both model evaluation and selection.
In cases where every piece of data is used for training the model, there remains the problem of selecting the best model from a list of possible models. Primarily, we want to identify which model has the lowest generalization error or which model makes a better prediction on future or unseen datasets than all of the others. There is a need to have a mechanism that allows the model to be trained on one set of data and tested on another set of data. This is where hold-out comes into play.
Hold-Out Method for Model Evaluation
Model evaluation using the hold-out method entails splitting the dataset into training and test datasets, evaluating model performance, and determining the most optimal model. This diagram illustrates the hold-out method for model evaluation.
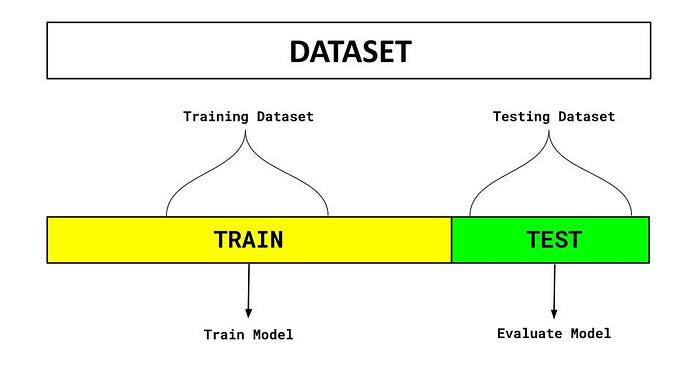
There are two parts to the dataset in the diagram above. One split is held aside as a training set. Another set is held back for testing or evaluation of the model. The percentage of the split is determined based on the amount of training data available. A typical split of 70–30% is used in which 70% of the dataset is used for training and 30% is used for testing the model.
The objective of this technique is to select the best model based on its accuracy on the testing dataset and compare it with other models. There is, however, the possibility that the model can be well fitted to the test data using this technique. In other words, models are trained to improve model accuracy on test datasets based on the assumption that the test dataset represents the population. As a result, the test error becomes an optimistic estimation of the generalization error. Obviously, this is not what we want. Since the final model is trained to fit well (or overfit) the test data, it won’t generalize well to unknowns or future datasets.
Olcay Cirit and his team at Uber AI was able to build a neural network that outperformed XGBoost. Learn more by checking out this clip from our recent Comet customer roundtable.
Follow the steps below for using the hold-out method for model evaluation:
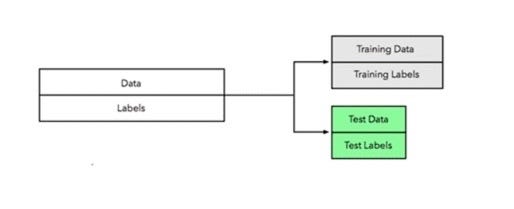
1. Split the dataset in two (preferably 70–30%; however, the split percentage can vary and should be random).
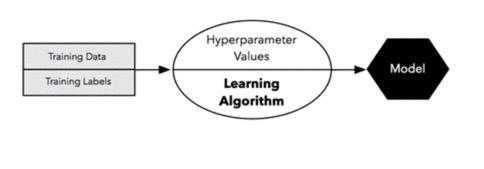
2. Now, we train the model on the training dataset by selecting some fixed set of hyperparameters while training the model.
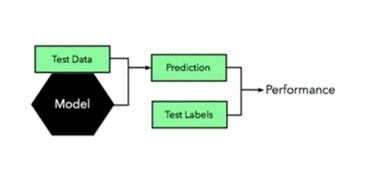
3. Use the hold-out test dataset to evaluate the model.
4. Use the entire dataset to train the final model so that it can generalize better on future datasets.
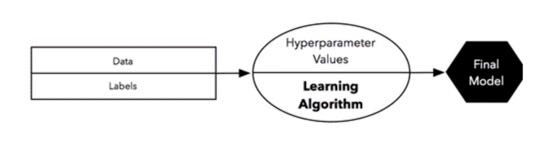
In this process, the dataset is split into training and test sets, and a fixed set of hyperparameters is used to evaluate the model. There is another process in which data can also be split into three sets, and these sets can be used to select a model or to tune hyperparameters. We will discuss that technique next.
Hold-Out Method for Model Selection
Sometimes the model selection process is referred to as hyperparameter tuning. During the hold-out method of selecting a model, the dataset is separated into three sets — training, validation, and test.
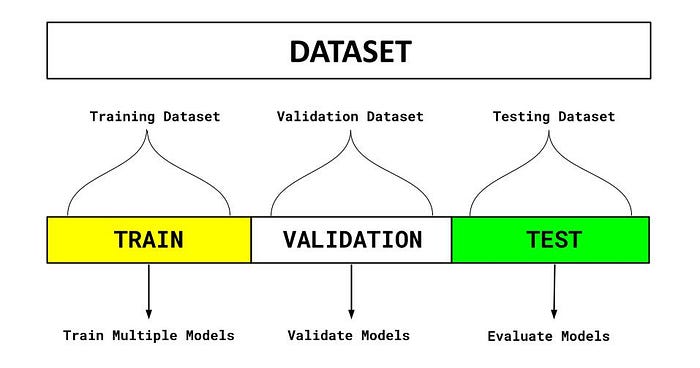
Follow the steps below for using the hold-out method for model selection:
- Divide the dataset into three parts: training dataset, validation dataset, and test dataset.
- Now, different machine learning algorithms can be used to train different models. You can train your classification model, for example, using logistic regression, random forest, and XGBoost.
- Tune the hyperparameters for models trained with different algorithms. Change the hyperparameter settings for each algorithm mentioned in step 2 and come up with multiple models.
- On the validation dataset, test the performance of each of these models (associating with each of the algorithms).
- Choose the most optimal model from those tested on the validation dataset. The most optimal model will be set up with the most optimal hyperparameters. Using the example above, let’s suppose the model trained with XGBoost with the most optimal hyperparameters is selected.
- Finally, on the test dataset, test the performance of the most optimal model.
Now, let’s see how to implement this in Python.
Implementing Python Code for Training/Test Split
The following Python code can be used to split the dataset into training and testing. Here is a code example that uses the Sklearn Boston housing datasetto show how the train_test_split method from Sklearn.model_selection can be used to split the dataset into training and test. The test size is specified using the parameter test_size.
#Importing the dataset from sklearn import datasets from sklearn.model_selection import train_test_split#Then, loading the Boston Dataset bhp = datasets.load_boston()#Finally, creating the Training and Test Split X_train, X_test, y_train, y_test = train_test_split(bhp.data, bhp.target, random_state=42, test_size=0.3)
Conclusion
If you have a large dataset, you’re in a hurry, or you’re just starting out with a data science project, you might benefit from the hold-out method. Hold-out methods can also be used to avoid overfitting or underfitting problems in machine learning models. Choosing a classifier is best done using hold-out methods. Additionally, these methods reduce error pruning for trees and facilitate early stopping of neural networks.
I hope that by now you have a better understanding of what hold-out methods are and how they are used in model selection and model evaluation for training machine learning models.
Happy Learning!!
