
When ChatGPT launched in 2022, generative AI seemed like magic. With a simple API call and prompt, any application could become “AI-powered.” Gone were the days of cumbersome model training that characterized predictive machine learning. In mere hours, a developer could build an application to debug code, answer customer questions, or automate any number of tasks.
Three years later, the AI community has come face to face with a difficult reality: it was never that easy. Like any other technology, LLMs come with limitations: hallucinations, limited context windows, and unpredictable responses, to name a few. Building and maintaining AI systems that work at scale requires far more effort and ongoing iteration than anyone anticipated. But it’s not all bad news. In part, the challenges AI developers are encountering reflect a growing ambition when it comes to AI. Many AI applications now center around agents that take actions and complete tasks autonomously. While exciting, such systems come with more potential failure points and make it all the more important to ensure reliable, consistent performance.
Why Current Agent Testing Methods Are Flawed
As in traditional software development, AI developers go through repeated cycles of building, deploying to production, and incorporating fixes based on user feedback. For AI applications this means hours iterating on prompts, agent architectures, and LLM parameters. The challenge is that bad LLM outputs don’t usually come with obvious failures or error messages that point to the cause of the issue.
To address this, many teams implement testing systems to identify root-cause issues. While this type of evaluation is the first step, it does little to actually resolve the issues that are surfaced. It’s hard to be sure what part of a prompt or an agent’s system is the source of a problem, let alone what particular changes would fix it. This lack of clear understanding of issues leaves engineers to go through repeated cycles of trial and error — sometimes without any luck.
These challenges highlight the need for a more systematic and methodical approach. Once teams have an evaluation mechanism in place, the natural next step is to implement an optimization mechanism. The Opik team envisions a future in which the manual iteration and guesswork of AI development is handled automatically. Repetitive prompt editing and re-testing, fixes based on user feedback, and even improvements to tool definitions will be done automatically, leaving engineers free to do what they do best: innovate and build. This vision of the future isn’t all that far away. At Comet, we call it automatic agent optimization and we’re building it into every part of Opik, our GenAI observability platform.
Self-Optimizing Agents In A Nutshell
The principal idea is that agent optimization as an approach can fix and refine an entire agent system given the initial agent and a set of criteria to optimize for, like a golden dataset and a metric for success. This applies to both initial app development in the early stages and production maintenance for a large scale agent in the wild. During development, teams will run optimization for automatic refinement after developing a prototype. Once in production, agent optimization might run on a regular cadence, updating the system to adapt to changes in user behavior, dataset shifts, new models emerging, etc.
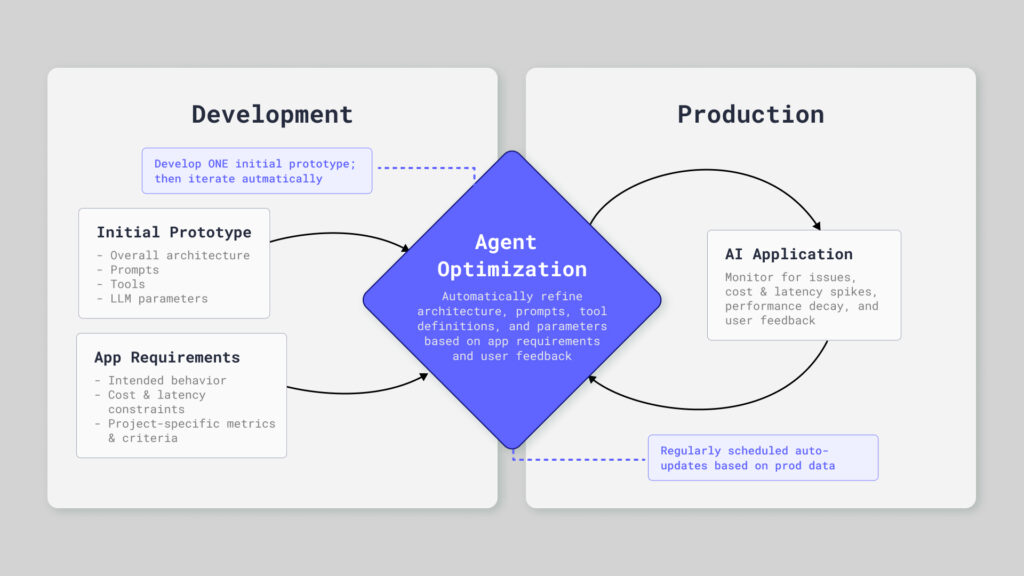
From Optimization to Automatic Agent Optimization
Optimization, including automatic agent optimization, is the disciplined process of improving a system against a clear goal. At its core, you define what “good” means, identify the levers you can adjust, and use a methodical search to find a configuration that best satisfies your goals within practical limits.
Across engineering, business, and applied mathematics, this pattern is everywhere. Logistics teams optimize delivery routes to reduce cost and time. Finance teams optimize portfolios to balance return and risk. Manufacturing teams run continuous optimization to maximize production and reduce waste. The specifics differ, but the structure is consistent: a measurable objective, constraints, variables, and a process for exploring alternatives. When each of these components is defined mathematically, the process can be completely automated, with no need for manual steps in the process.
Most optimization frameworks share a few building blocks:
- Objectives or metrics: a quantitative way to measure success.
- Constraints: limits that must be respected, like budgets, service levels, compliance, or SLAs.
- Variables: the parts you can change, which together form a “search space” of possible solutions.
- Data: representative scenarios or datasets used to evaluate candidates.
- Algorithm: a strategy for exploring the search space and deciding what to try next, from simple heuristics to advanced gradient-based methods.
In practice, optimization is iterative, much like running a series of controlled experiments. You generate a candidate solution, evaluate it on your metrics and data, learn from the results, and use that feedback to propose a better candidate. Over cycles, the system converges on a configuration that performs well and remains within the defined constraints.
Automatic agent optimization applies this same proven pattern to generative AI applications and agents. That means optimizing the components of an agent (prompts, tool definitions, model parameters, etc.) or even the agent as a whole by refining the structure of the agent graph. In the context of agent optimization, the objectives (metrics) can span multiple dimensions: task success or usefulness, correctness, safety and compliance, latency and cost, or any use case specific metric. Constraints might include spending limits, maximum response time, or required steps for safe tool use. Data used for agent optimization can be curated test cases, simulated interactions, and real production traces.
The variables to be optimized in agent optimization include prompts, tool definitions, agent architectures, retrieval settings, and model parameters. Prompt optimization is already a relatively common practice among generative AI developers, and typically involves improving an individual prompt within an application. More advanced agent optimization is still in its infancy, with researchers and early adopters taking the first steps. For example:
- Prompt optimization can be extended to multi-prompt optimization in complex systems where multiple prompts may need to be optimized simultaneously.
- Tool optimization targets tool schemas and descriptions, MCP integrations, and the tools themselves for optimization.
- Model choice and parameter optimization selects the best combination of base LLMs and parameters (temperature, top_p, etc.)
Agent Optimization Algorithms
When it comes to optimization algorithms used to optimize prompts or whole agents, there is no one-size-fits-all approach and the research is still evolving. Many modern generative optimization algorithms incorporate a LLM-driven analysis where the optimization process is driven by the LLM itself. This can come from a larger, more powerful reasoning model akin to distillation (student vs teacher model paradigm in machine learning) or can be more complex approaches combing deep learning, reinforcement learning, and classical machine learning methods to improve the prompt or the agents overall. For example:
- Meta-prompting is a popular approach that excels at general prompt refinement. It uses LLMs to first evaluate a prompt, then critique it and generate an improved candidate. This is a simple CoT (chain of thought) based approach where the model will reason with itself and try to update its prompts.
- Genetic and evolutionary optimization algorithms, which simulate natural evolutionary processes to “evolve” a population of candidates to find the best one. Some agent and prompt optimization algorithms combine these techniques. The well-known GEPA algorithm combines LLM-driven reflection with an evolutionary algorithm to improve prompts as well as our own evolutionary optimizer which uses a similar approach by evolving sentence’s and parts of a prompt.
- Reflective optimization, developed by the Comet team, uses hierarchical root cause analysis to identify and address specific failure points in prompts. The approach is similar to how modern coding agents solve complex problems.
- Other approaches incorporate traditional mathematical optimization, such as bayesian optimization, which works well for tasks like model parameter optimization or finding the best few-shot examples to use in a prompt.
Agent optimization can involve a nearly infinite search space, making it essential to select the algorithm best suited for the task, especially since developers may need to optimize many prompts and tools at once.
By framing agent optimization as standard optimization applied to the components of an AI agent, the concept becomes intuitive: the same rigor that improves complex systems elsewhere now continuously refines prompts, tools, parameters, and agent architecture to meet application requirements with consistency and confidence.
Optimization in the context of AI agents:
- Objectives: accuracy or usefulness on representative tasks, safe behavior, cost and latency targets, use case specific metrics.
- Constraints: budget caps, latency SLAs, required guardrails, approved tools and data sources.
- Variables: prompts and prompt structure, agent roles and orchestration, tool schemas and selection policies, model choice and parameters.
- Data for evaluation: curated test cases, synthetic scenarios, and real user traces with feedback to ensure the results generalize.
- Algorithms: GEPA, Meta-prompting, HAPO and specialized algorithms
Our Vision for Opik
Today’s generative AI still leans heavily on manual human trial and error. Teams spend hours hand-tuning prompts, experimenting with model parameters, and tweaking tool definitions. There’s no guarantee that any change will show improvement during testing, and the whole process feels more like “guess and check” than disciplined development. In production, behavior drifts as users and the world change, forcing ongoing maintenance just to keep quality steady. What works for one model often fails for another, so “migrating” prompts during model upgrades becomes a costly chore. And as systems mature, organizations break a single prompts and model calls into multiple agents and tools, making end‑to‑end performance all the more difficult to reason about and improve.
The Workflow
Comet’s vision is to make AI development as routine and reliable as modern software engineering by turning that grind into an automated, data‑driven optimization loop. Here’s how we envision the workflow:
- Define Requirements: The development team agrees on AI app requirements such as intended behavior, cost and latency constraints, and any specific metrics and criteria. Key requirements are transformed into evaluation metrics. This step is crucial to optimization as it spells out the both the objectives and the constraints to be used during optimization.
- Initial Prototype Development: The initial app, with a first pass at prompts, architecture, and tools integration is developed as a starting point.
- Assemble Evaluation Data: Developers gather curated test cases for key flows, edge cases, and safety checks. This can take the form of representative production traces from early users or simulated scenarios. These test cases will be used to evaluate candidates during optimization.
- Prepare and Run the Optimization Loop: Optimization variables (e.g. prompts, tools, architecture, etc), objectives (cost, latency, evaluation metrics), and algorithms are selected based on the complexity and requirements of the use case. Optimization runs behind the scenes, automatically improving anything from individual prompts to multi-agent architectures.
- Validate Results and Promote to Production: Teams evaluate the optimized agent against hold-out test scenarios, data intentionally kept separate from the optimization loop to ensure the improvements generalize. This validation may include human review to confirm that changes align with intended behavior. The agent is promoted to production with full observability and continuous testing mechanisms in place. These monitoring and evaluation systems become the foundation for ongoing optimization, capturing real-world performance data and user feedback that will drive future refinement cycles.
- Optimization in Production: In production, optimization runs at a regular cadence, using real production traces and user feedback as evaluation data. This continuous loop automatically resolves emerging issues and improves performance with each release, adapting the system to shifting user needs and new edge cases. Optimization in production may look different than full scale optimization during development, focusing smaller improvements (e.g prompt improvements, tool descriptions, etc.), with occasional comprehensive agent optimization for major updates .
Key Considerations
This is a flexible framework, not a rigid prescription
There’s no single optimization algorithm or configuration that works for every use case. A simple chatbot answering general FAQs has different needs than a multi-agent system orchestrating financial transactions. Comet is designing agent optimization as a flexible to work with a variety of our optimizers and public open-source optimizers rather than a one-size-fits-all tool. Developers can bring in any optimization algorithm, choose the metrics that matter for their use case, and select which variables to optimize based on their system’s complexity, lifecycle stage, and tolerance for failure. An early prototype might benefit from broad multi-prompt optimization, while a mature production system might run focused prompt tuning on a weekly schedule. The framework adapts to the situation rather than forcing developers into a prescribed approach.
Apply human review where it matters most
While agent optimization automates some of the GenAI development process, it is still essential to keep a human in the loop. Initial agent prototyping, prompt drafting, and context engineering requires thoughtful design by human developers or subject matter experts. For evaluation, (and thus optimization) to work, developers must define metrics that capture what “good” actually means for their use case. Before promoting changes to production, teams review and approve optimized prompts and configurations to ensure they align with brand voice, compliance requirements, and intended behavior. In production, user feedback becomes critical data: it validates metrics, surfaces edge cases for the optimization dataset, and highlights when adjustments are needed. Over time, teams can even develop data-driven evaluation metrics based on patterns in human feedback, making the optimization loop smarter with each cycle.
Create a continuous development lifecycle for agents
Agent optimization is part of a larger shift toward continuous development for AI systems. Just as modern software engineering relies on CI/CD pipelines, automated testing, and observability, GenAI development needs the same disciplined infrastructure. Observability and evaluation must be built into every stage of the lifecycle. Product owners need continuous visibility into how well their agents are performing and when failures occur. Without that foundation, optimization has nothing to build on. Evaluation is the first step; once teams can measure performance reliably, optimization becomes the logical next step to act on those measurements. The full workflow is end-to-end and continuous: ongoing data collection feeds updated quality and performance metrics, which trigger optimization runs, which produce candidates that can be pushed to production automatically once approved. This is the CI/CD rhythm applied to agents.
The Result
The shift from manual iteration to automated agent optimization fundamentally changes how teams build and maintain GenAI applications. Developers and subject matter experts draft an initial prompt once, then let the optimizer handle the refinement. This removes the guesswork and trial-and-error cycles that currently consume days of engineering time. Teams no longer need specialized prompt engineering expertise to achieve reliable performance. Instead the optimizer can systematically explores improvements based on prompt engineering best practices.
More importantly, agent optimization addresses the entire system rather than isolated components. When multiple prompts, tools, parameters, and architectural elements are optimized together, the system can improve holistically. Changes that might break one part of the agent while improving another are identified and avoided, leading to more robust overall performance.
In production, optimization runs on a schedule, automatically catching and addressing drift and regressions before they become a problem. When a base model is upgraded or user behavior shifts, the system adapts without requiring manual prompt rewrites. This continuous refinement means that agents improve over time rather than degrade, turning maintenance from a reactive chore into a proactive, automated process.
Early results validate the approach. Research and internal testing show that prompt optimization alone delivers measurable performance improvements across task success, correctness, and efficiency metrics. As agent optimization matures to encompass tools, multiple simultaneous prompts, and architectures, those gains will compound.
In Conclusion: Agent Development Has Evolved
GenAI is still an immature technology. Development practices today reflect that immaturity: manual prompt tweaking, trial-and-error debugging, and reactive fixes dominate the workflow. But this pattern is familiar. Most technologies that reach scale eventually move beyond ad hoc methods toward automated, quantitative approaches. Traditional software development evolved from manual testing to CI/CD pipelines. Manufacturing shifted from artisanal craftsmanship to process optimization. Finance moved from intuition-driven decisions to algorithmic portfolio management.
GenAI is following the same trajectory. As agent systems become more complex and the stakes of failure grow higher, the industry will demand more rigorous development practices. Comprehensive observability and evaluation are the first step in that process. Agent optimization represents the next step, bringing the discipline of systematic improvement to a field that has relied too long on guesswork. At Comet, we’re building that future into Opik, making agent optimization a core capability rather than an afterthought. This shift is already underway, and we’re committed to leading it.
Optimize Agents with Opik Today
We may be looking toward the future of AI agent development, but did you know that a great deal of the automated optimization functionality described above already exists within Opik today? The fully open-source Opik repository includes practical, usable implementations of seven optimization algorithms (MetaPrompt, Hierarchical Reflective, Few-Shot Bayesian, Evolutionary, GEPA, Parameter Optimization, and Tool Optimization), plus a full suite of tools to help you log, define, measure, and improve AI agent performance.
All LLM observability, evaluation, and agent optimization features are included in both the OSS version and the free cloud-hosted version of Opik, with no strings attached. Choose your version and start optimizing agents today.
