Few-Shot Bayesian Optimizer
Optimize few-shot examples for chat prompts with Bayesian techniques.
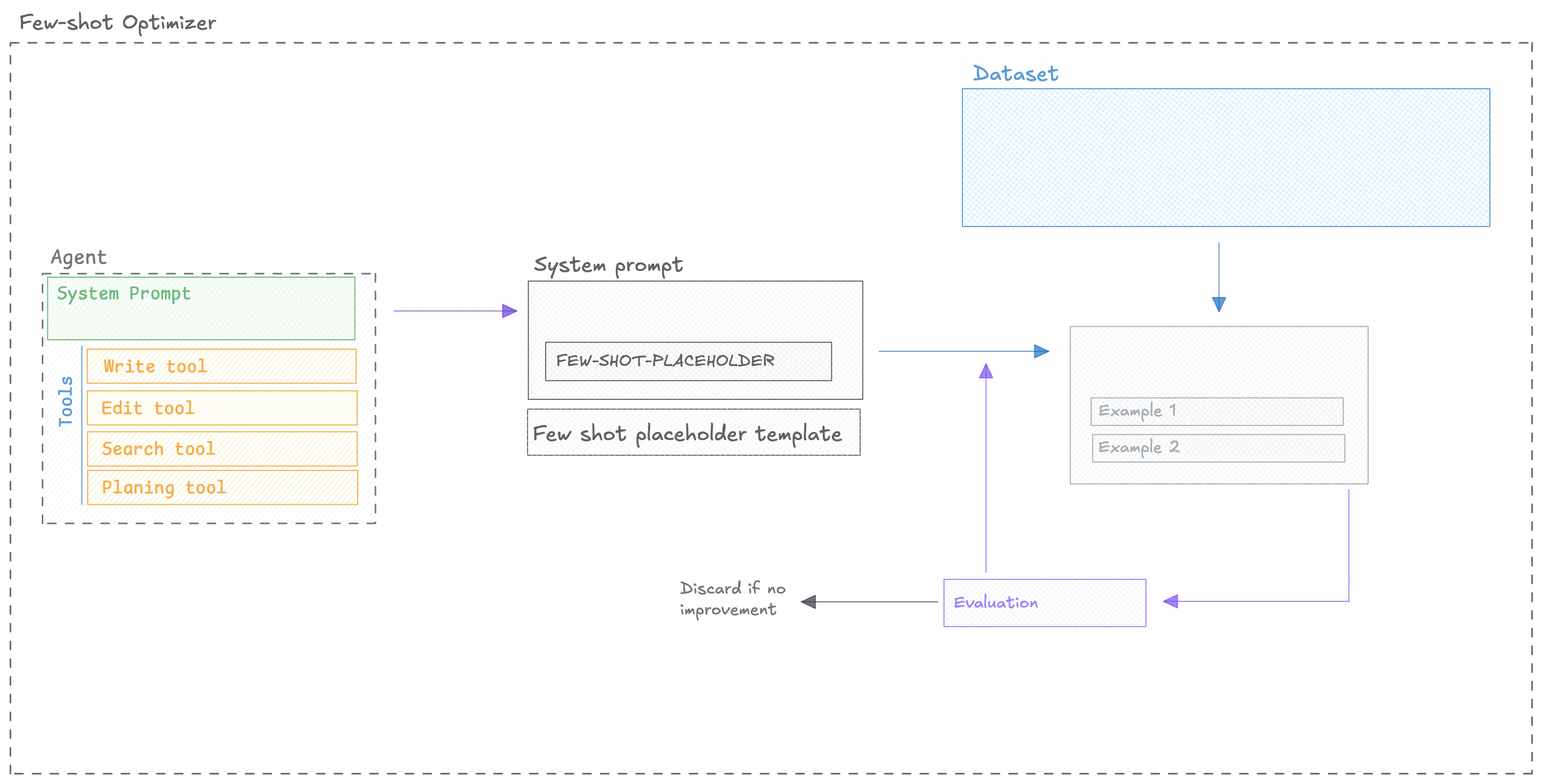
The FewShotBayesianOptimizer is a sophisticated prompt optimization tool adds relevant examples from your sample questions to the system prompt using Bayesian optimization techniques.
The FewShotBayesianOptimizer is a strong choice when your primary goal is to find the optimal number and
combination of few-shot examples (demonstrations) to accompany your main instruction prompt,
particularly for chat models. If your task performance heavily relies on the quality and relevance of in-context examples, this optimizer is ideal.
How It Works
The FewShotBayesianOptimizer uses Bayesian optimization to find the optimal set and number of
few-shot examples to include with your base instruction prompt for chat models. It Uses
Optuna, a hyperparameter optimization framework, to guide the search for the
optimal set and number of few-shot examples.
Quickstart
You can use the FewShotBayesianOptimizer to optimize a prompt by following these steps:
Configuration Options
Optimizer parameters
The optimizer has the following parameters:
optimize_prompt parameters
The optimize_prompt method has the following parameters:
50), fractions (e.g., 0.1), percentages (e.g., “10%”), or “all”/“full”/None for the full dataset.Model Support
There are two models to consider when using the FewShotBayesianOptimizer:
FewShotBayesianOptimizer.model: The model used to generate the few-shot template and placeholder.ChatPrompt.model: The model used to evaluate the prompt.
The model parameter accepts any LiteLLM-supported model string (e.g., "gpt-4o", "azure/gpt-4",
"anthropic/claude-3-opus", "gemini/gemini-1.5-pro"). You can also pass in extra model parameters
using the model_parameters parameter:
Next Steps
- Explore specific Optimizers for algorithm details.
- Refer to the FAQ for common questions and troubleshooting.
- Refer to the API Reference for detailed configuration options.