HRPO (Hierarchical Reflective Prompt Optimizer)
HRPO (Hierarchical Reflective Prompt Optimizer)
HRPO (Hierarchical Reflective Prompt Optimizer) uses hierarchical root cause analysis to identify and address
specific failure modes in your prompts. It analyzes evaluation results, identifies patterns in
failures, and generates targeted improvements to address each failure mode systematically.
In code, use the HRPO class (for example from opik_optimizer import HRPO). The underlying module name still uses
hierarchical_reflective_optimizer for backwards compatibility.
HRPO is ideal when you have a complex prompt that you want to refine
based on understanding why it’s failing. Unlike optimizers that generate many random variations,
this optimizer systematically analyzes failures, identifies root causes, and makes surgical
improvements to address each specific issue.
How It Works
HRPO (Hierarchical Reflective Prompt Optimizer) has been developed by the Opik team to improve prompts that might have already gone through a few rounds of manual prompt engineering. It focuses on identifying why a prompt is failing and then updating the prompts to address the issues.
As datasets can be large, we split the analysis into batches and analyze them in parallel. We then synthesize the findings across all batches to identify the core issues with the prompt.
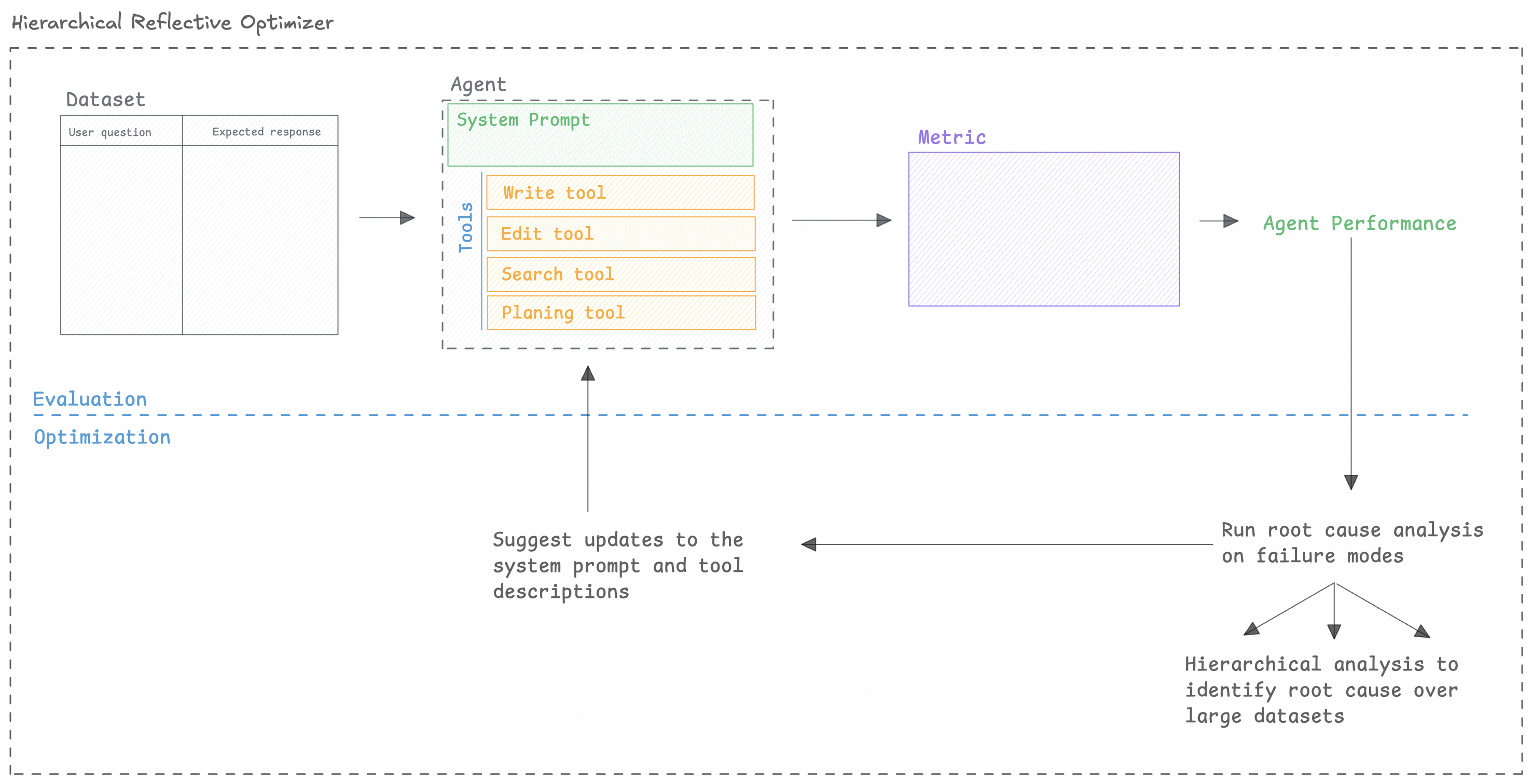
The optimizer is open-source, you can check out the root cause analysis code and prompts in the Opik repository.
Quickstart
You can use HRPO to optimize a prompt:
Configuration Options
Optimizer parameters
The optimizer has the following parameters:
optimize_prompt parameters
The optimize_prompt method has the following parameters:
50), fractions (e.g., 0.1), percentages (e.g., “10%”), or “all”/“full”/None for the full dataset.Model Support
There are two models to consider when using HRPO:
HRPO.model: The model used for the root cause analysis and failure mode synthesis.ChatPrompt.model: The model used to evaluate the prompt.
The model parameter accepts any LiteLLM-supported model string (e.g., "gpt-4o", "azure/gpt-4",
"anthropic/claude-3-opus", "gemini/gemini-1.5-pro"). You can also pass in extra model parameters
using the model_parameters parameter:
Next Steps
- Explore specific Optimizers for algorithm details.
- Refer to the FAQ for common questions and troubleshooting.
- Refer to the API Reference for detailed configuration options.