
Introduction
In the field of computer vision, Kangas is one of the tools becoming increasingly popular for image data processing and analysis. Similar to how Pandas revolutionized the way data analysts work with tabular data, Kangas is doing the same for computer vision tasks.
Kangas is an open-source tool by Comet ML for exploring, analyzing, and visualizing large-scale multimedia dataset like images, videos, and audio. Kangas enables ML professionals to visualize, sort, group, query, and interpret their data (structured or unstructured) to obtain meaningful insights and speed up model development.
Pandas, on the other hand, is a popular open-source Python library for data analysis and manipulation for tabular data. It can also be used to clean and prepare data. It is easy to use, fast, and flexible compared to other libraries, but does not natively support unstructured data types, as Kangas does.
Kangas is to computer vision data what Pandas is to tabular data. Kangas provides methods for reading, manipulating and analyzing images as we will see in a few examples in this tutorial.
Benefits of Kangas
- Simple to use: The main benefit of Kangas is its ability to simplify the process of working with computer vision data. It has a user-friendly API that is fast and data professionals can load, process, and analyze visual data without writing complex lines of code. This makes it easier for data professionals to focus on the task at hand, rather than the technicalities of data processing.
- Speed and efficiency: Compared to other computer vision tools, Kangas can handle large datasets with ease and process them quickly, allowing for real-time data analysis and decision-making. This makes it ideal for use in time-sensitive applications such as self-driving vehicles, where quick and accurate analysis of visual data is crucial.
- Diverse: Kangas provides a wide range of machine learning algorithms that can be applied to computer vision tasks. These algorithms can be used to perform tasks such as image classification, object detection, and image segmentation.
- Ability to handle large amounts of data: Kangas uses a memory-efficient data structure that allows data professionals to process large amounts of image and video data with great performance. This makes it ideal for working with high-resolution images and video data.
- Flexible: Kangas can be run in multi-platform applications like Jupyter notebook, stand-alone applications, or web apps.
Reading CSV files with Kangas
Reading data from a csv file is quite similar in Kangas and Pandas. The difference is that Kangas creates a DataGrid and Pandas creates a DataFrame. The code below shows how to read data from a csv file into a DataGrid:
import kangas as kg
dg = kg.read_csv("path_to_csv_file")
This can be compared to the code used to read csv files in Pandas:
import pandas as pd
df = pd.read_csv("path_to_csv_file")
Next, we’ll visualize the data in the csv file using the code below:
dg.show()
Output:

Compared to Pandas’ syntax below:
df.head()
Note that the Kangas DataGrid is interactive, whereas the Pandas DataFrame is static.
Reading image files
Unlike other computer vision image libraries like OpenCV, reading image files using Kangas uses the simplicity of Pandas to ensure the data scientist puts effort where it is required.
To read an image file using Kangas, run the code block below:
import kangas as kg
image = kg.Image("path_to_images").to_pil()
Visualize the image file by running the name the variable “image” as shown in the code below:
image
Output:

From the examples above, you can see how similar Kangas’ syntax is to Pandas.
Pandas and Kangas Similarities
- Syntax: Kangas and Pandas have a similar syntax which is easy to write and use.
- Data handling: Kangas and Pandas both have data handling functionalities. Both can read data of any format from csv, Json to xlsx (Excel) files. Kangas uses DataGrid while Pandas uses Data Frame and Series to store data.
- Data manipulation: Both Kangas and Pandas enable users to filter, sort, merge, and reshape data, but Kangas does so interactively.
- Indexing: Both libraries allow users to index and select data based on labels or conditions. In Pandas, this is done using
locandilocmethods, while in Kangas it is done from the DataGrid. - Data analysis: Both libraries provide methods for basic data analysis, like descriptive statistics, aggregation, and grouping operations.
Kangas and Pandas Differences
- Kangas processes image files while Pandas does not.
- Kangas provides a user interface for manipulating the data in the DataGrid while Pandas only allows for programmatic manipulation.
Creating Kangas DataGrid
A Kangas DataGrid is an open-source SQLite database that provides the ability to store and display large amounts of data and perform fast complex queries. A DataGrid can also be saved, shared, or even served remotely.
Some key features of the Kangas DataGrid include:
- Lazy loading: Kangas DataGrid loads data only when needed, which makes it ideal for displaying large datasets.
- Filtering and sorting: Users can filter and sort the data displayed in the grid based on various criteria.
- Cell editing: Users can edit individual cells within the grid, and those changes can be saved back to the underlying data source.
- Column resizing and reordering: Users can resize and reorder columns within the grid.
- Virtual scrolling: Kangas DataGrid supports virtual scrolling, which means that only the visible rows are rendered in the DOM, resulting in a significant performance boost.
Kangas DataGrid is easy to customize and configure which allows developers to tailor its design and functionality to meet the needs of their specific applications.
Creating a Kangas DataGrid is quite easy for tabular data compared to image data. For tabular data, a DataGrid is created simply by reading a csv file using Kangas as shown below:
dg = kg.read_csv("/path_to_csv_file")
dg.show()
For image data, below is a step-by-step process of creating a DataGrid:
- First, collect data or download from a data repository like Kaggle.
- Split the data into x_train, x_test, y_train and y_test partitions.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2,
random_state=42)
- Next, train the model.
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.applications.mobilenet import MobileNet
# Define the model
model = Sequential([MobileNet(include_top=False,
input_shape=(150, 150, 3),
weights="imagenet",
pooling='avg',
classes=1000),
Dense(128, activation='relu'),
Dropout(0.25), Dense(1, activation='sigmoid')
])
model.summary()
# compile model
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
# fit the model
batch_size = 20
classifier = model.fit(
X_train, y_train,
steps_per_epoch=train_samples // batch_size,
epochs=10,
validation_data=(X_test, y_test),
validation_steps=validation_samples // batch_size)
- Create and save a Kangas DataGrid.
from kangas import DataGrid, Image
dg = DataGrid(
name="potato-tuber",
columns=[
"Epoch",
"Index",
"Image",
"Truth",
"Output",
"score_0",
"score_1",
"score_2",
],
)
# Make image of the test set for reuse
images = [Image(test, shape=(28, 28)) for test in X_test]
# Do it once before training:
outputs = model.predict(X_test)
epoch = 0
for index in range(len(X_test)):
truth = int(y_test[index].argmax())
guess = int(outputs[index].argmax())
dg.append([epoch, index, images[index], truth, guess] + list(outputs[index]))
dg.save()
- Explore and share the DataGrid.
After creating the DataGrid, access the path where the DataGrid is saved and copy the path. Run the command below to explore the created DataGrid:
kg.show('/path_to_datagrid/')
Output:
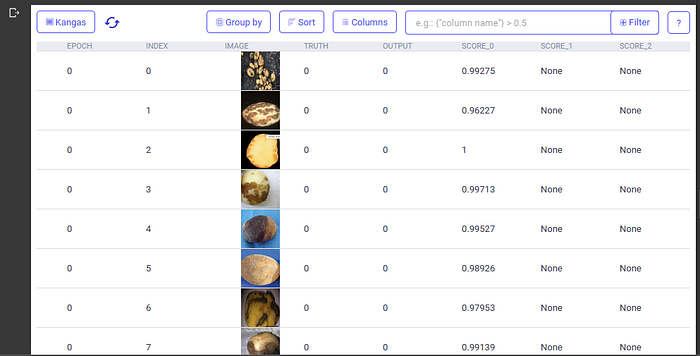
You can access the created Kangas DataGrid here.
Conclusion
Kangas is on its way to becoming the Pandas of computer vision data processing and analysis. Its user-friendly API, speed, efficiency, and ease-of-use makes it a valuable tool for data scientists and computer vision experts alike. Whether you’re working on a cutting-edge autonomous vehicle project or simply analyzing data for research purposes, Kangas is the perfect tool for the job.
Learn more about Kangas from the official documentation.
If you enjoyed this article, check out one of my others!
