Note: this article originally appeared on Raúl Gómez’s website at https://gombru.github.io/2019/01/14/miro_styletransfer_deepdream/ and was reposted here with his permission. We highly encourage you to read the rest of Raúl’s pieces here.
Neural Style Transfer
The Neural Style Transfer Algorithm
Neural Style Transfer uses Deep Convolutional Neural Networks to transfer the style of one source image to another keeping its content. It’s often applied to transfer the style of a painting to a real word image. The key here is: How do we define style and how do we define content?
- Style: Aesthetic of the image (line style, color range, brush strokes, cubist patterns, etc.)
- Content: Image objects and shapes that make the scene recognizable.
How are style and content represented in a CNN?
CNNs are attached convolutional layers where each layer processes the previous layer output. The first convolutional layer operates directly over the image pixels. Regardless the task the CNN is optimized for, this layer will learn to recognize simple patterns from images, such as edges or color. Next layers will learn to recognize a little bit more complex patterns, such as corners or textures. Last layers will learn to recognize more complex patterns related to the task the CNN is optimized for. If it is trained to classify buildings, it will be sensible to windows or door shapes, and if it is trained to classify faces, it will sensible to eyes or mouths. Simple features (extracted by the first layers) are called low-level features, and complex features (extracted by the lasts layers) high-level features.

Based on those observations, Neural Style proposes the following definitions (simplified):
- Style: Two images are similar in style if their CNN low-level features are similar.
- Content: Two images are similar in content if their CNN high-level features are similar.
How does it work?
Neural Style Transfer uses two different CNNs in the training phase: An Image Transformation Network, which is the one trained and the one that will generate the styled images, and a Loss Network, which is a pretrained and frozen classification CNN (VGG-16) used to compute the Style-Loss and the Content-Loss used to train the Image Transformation Network.
The training process is as follows:
- We chose a source style image (in our case a Joan Miró painting image) and we forward it though the Loss Network (VGG-16).
- Then we use a general classification dataset, such as ImageNet. We forward each ImageNet image though the Loss Network, and compute a Style-Loss based on the similarity between low-level activations with the source style image.
- Then we forward the ImageNet image though the Image Transformation Network, and forward its output through the Loss Network.
- There, a Content-Loss based on the similarity between higher-level activations with the original ImageNet image.
The Neural Style transfer algorithm I’ve schematically explained and used here was developed by Google. It’s explained deeply in their paper “A Learned Representation for Artistic Style” and also in their blog post about it. This Google work is based on Justin Johnson paper “Perceptual Losses for Real-Time Style Transfer and Super-Resolution”.
To train the Joan Miró style transfer model, I’ve used TensorFlow Magenta implementation, which is available here.
Miró Neural Style Transfer
I trained a Neural Style Transfer model with 9 different Joan Miró paintings source styles. Here I show the results in a few testing images.
Results in my cat image for the 9 source styles.

More styling: We show the original image and the source style image, along with the styled image in sets of three.
Which one is your favorite?
Set #1:



Set #2:



Set #3:



Set #4:



Set #5:



Set #6:



Set #7:



Set #8:



Set #9:



DeepDream
The DeepDream algorithm
DeepDream is an algorithm by Google that magnifies the visual features that a CNN detects in an image, producing images where the recognized patterns are amplified. I research in methods to learn visual features from paired visual and textual data in a self-supervised way. A natural source of this multimodal data is the Web and the social media networks. A detailed explanation of how I train this models, of how the DeepDream algorithm works, and of how I apply it to them, can be found in the Barcelona Deep Dream blog post where I apply DeepDream to a model trained with #Barcelona Instagram data. I recommend reading it to understand what we are visualizing in the following images.
Miró DeepDream
I collected 200K Instagram posts containing #joanmiro and #miro hashtags, and trained a CNN model to learn visual features from those images using the text as a supervisory signal. The CNN learns filters to recognize the visual patterns that are most useful to differentiate between images with different associated texts. DeepDream allows to visualize those patterns, amplifying them and showing them in a single image.
The following images show the visual patterns recognized by different layers of the CNN model (GoogleNet).
Miró Forest

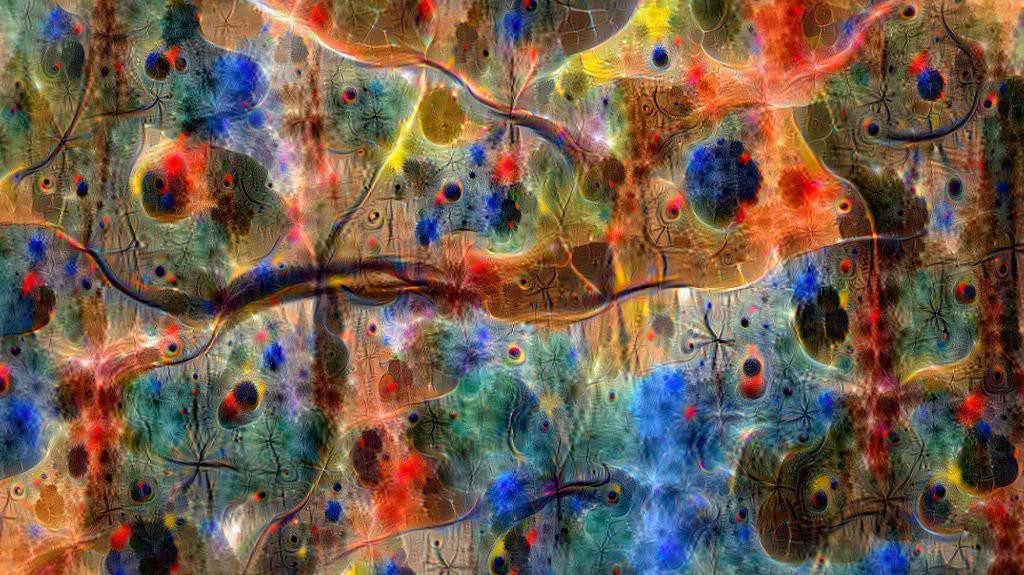
Miró Lakes

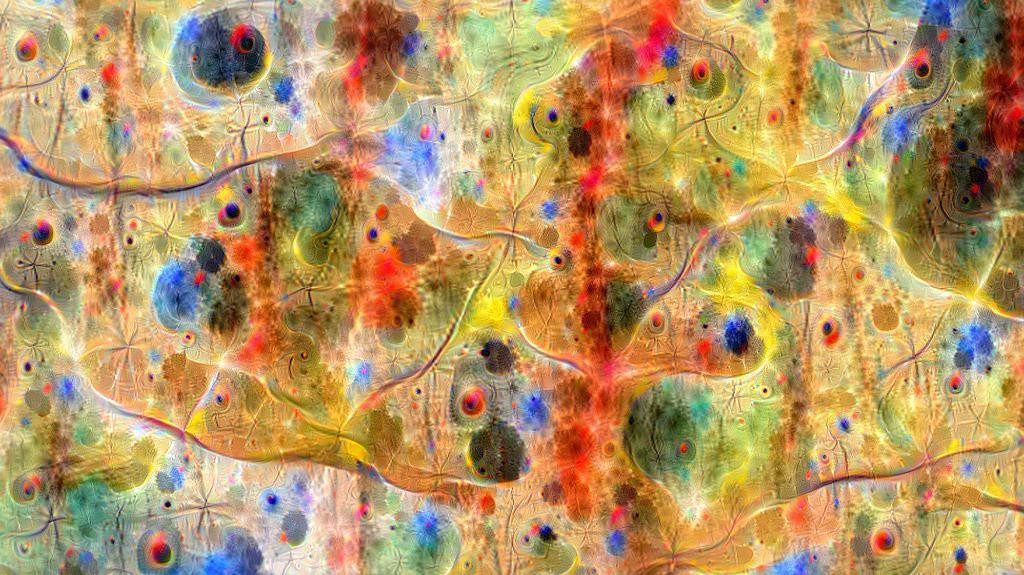
Miró Lights


