
-
The Best AI Observability Tools for Agentic Systems in 2026
AI applications used to rely on a handful of straightforward LLM calls. Now agents make hundreds of decisions in response…

-
What Held Up at 3 AM: One Engineer’s RAG Case Study
Most AI demos work. Most AI products don’t. This series is a collection of interviews with engineers who shipped AI…
-
LLM Cost Tracking Solution: How to Monitor and Control AI Spend in Agentic Systems
The first sign of trouble isn’t always performance. Sometimes it’s the invoice. Your team ships a new agent that routes…

-
Introducing the Opik Agent Playground
In the early stages of agent development, you make big changes to your agent’s code: designing the architecture, integrating tools,…

-
Introducing Ollie: Auto-Fix Your Agent’s Codebase
In standard software engineering, developers use proven, repeatable workflows to develop, test, debug, and update software products. They use intelligent…

-
Introducing Opik Test Suites: Straightforward Unit & Regression Testing for AI Agents
One of the biggest challenges when it comes to agent development is quality. It’s getting easier every day to spin…

-
Multimodal LLM Evaluation: A Developer’s Guide to Multimodal Language Models
Production teams processing billions of product listings, such as Shopify, report that multimodal LLMs analyzing product images alongside metadata can…

-
AI Agent Evaluation: Building Reliable Systems Beyond Simple Testing
Your customer service agent routes 2,000 queries daily. During testing, it resolved 85 percent of requests correctly. Three weeks after…

-
Axios Supply Chain Attack: What Happened, How We Responded, and What You Should Do Right Now
On March 31, 2026, axios — one of npm most popular packages — was compromised with a remote access trojan.…

-
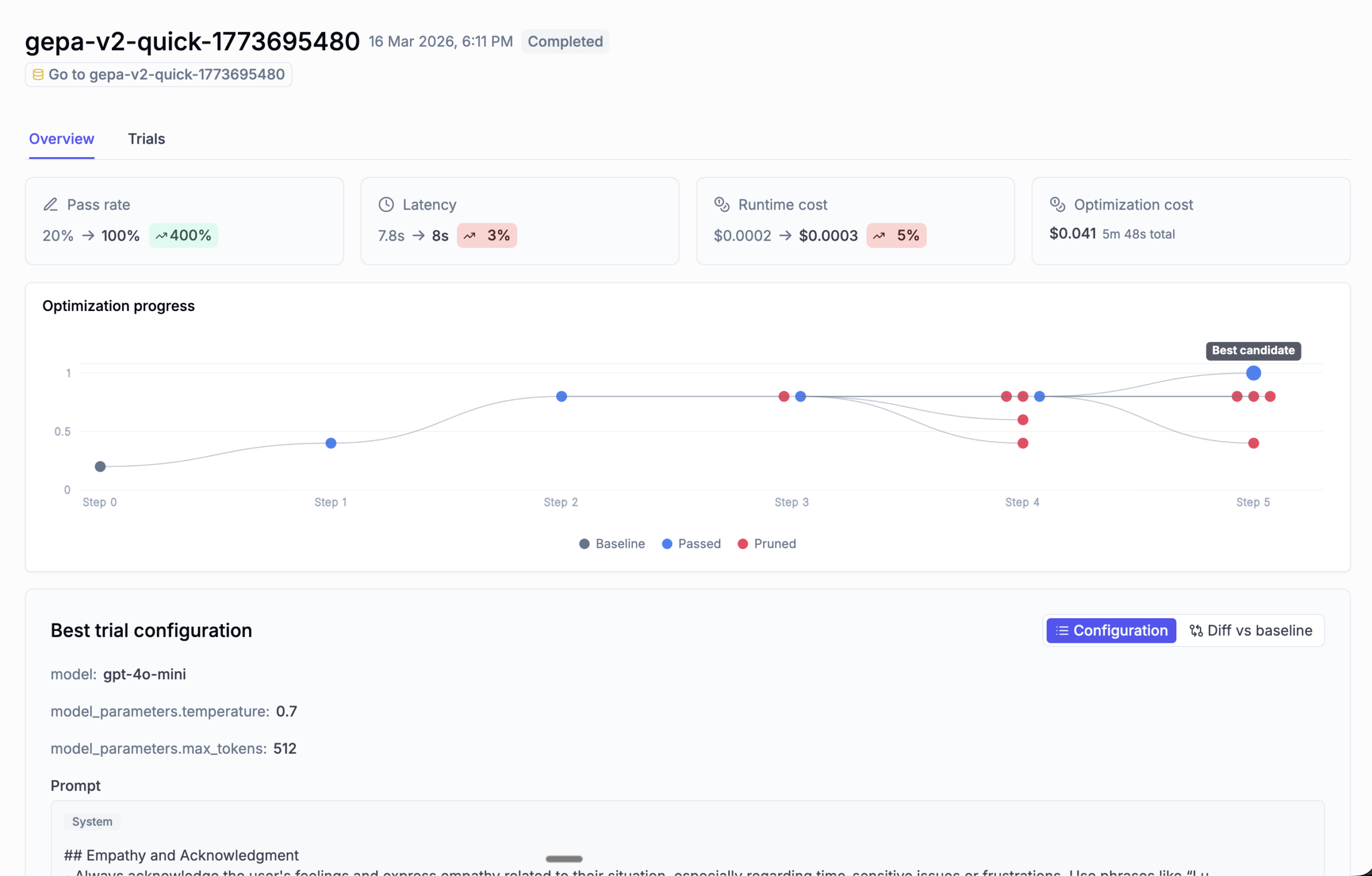
New in Opik: Native OpenClaw Observability, Custom Dashboards, Optimization UI Upgrades, & More!
Whether you’re tracing complex agent workflows, comparing prompt optimization runs, or building dashboards around the metrics that matter most, this…
New! Track & optimize Claude Code spend across your engineering team. Learn More→
Comet Blog
-
Understanding Your Claude Code Spend: What’s Actually Driving the Cost
I’ve been spending time looking at how teams are actually using Claude Code, and one thing keeps coming up: most…








Get started today for free.
You don’t need a credit card to sign up, and your Comet account comes with a generous free tier you can actually use—for as long as you like.