You know the routine: Write your first prompt, and then spend hours manually tweaking prompts, testing variations, and documenting what works. You might get a 5% improvement. You might not. The unreliable process felt more like alchemy than engineering.

MIPRO (Multiprompt Instruction PRoposal Optimizer) changed that equation. Published in 2024 as part of the DSPy framework, MIPRO was one of the first systems to demonstrate that automated optimization could consistently outperform human prompt engineers. The original research from the team at Stanford showed prompts optimized with MIPRO performing up to 13% better than carefully hand-crafted alternatives using five diverse, multi-stage language model programs (based on evaluations in 2024).
MIPRO enabled a reproducible, systematic approach to a problem that previously relied on intuition, trial and error, and countless hours of manual iteration. MIPRO proved you could treat prompt optimization as an engineering problem with measurable outcomes rather than an art form that required specialized expertise and subjective processes.
From Manual Tweaking to Systematic Optimization
MIPRO simultaneously optimizes your prompt instructions and few-shot examples for each module in your pipeline. This approach tackles a time-consuming challenge in developing AI applications by updating the high-level task description and desired behavior in a single pass for each update, rather than separate iterations for each piece of the prompt.
With few-shot learning, you can provide your LLM a handful of input-output examples that demonstrate the task you want it to perform. Instead of fine-tuning the model on thousands of examples, you include two to ten demonstrations directly in your prompt. The model learns the pattern from these examples and applies it to new inputs.
Consider a typical retrieval-augmented generation (RAG) application. You might start with a query reformulation prompt like this:
Rewrite the user's question to be more specific and searchable.
Question: {query}
Rewritten: With a generic prompt like this, you over-simplify questions or miss important context. To improve the prompt, add a few examples to your prompt:
Rewrite the user's question to be more specific and searchable.
Question: What's the weather?
Rewritten: What is the current weather forecast for my location?
Question: Tell me about dogs
Rewritten: What are the key characteristics and behaviors of domestic dogs?
Question: {query}
Rewritten:This prompt is going to get better results. The next challenge is determining which examples help and how many do you need. Should the instruction emphasize specificity or preserve user intent? Next, you would need to test those variations, which could take days.
MIPRO automates this iteration process. You provide a training dataset of query-rewrite pairs and an evaluation metric. MIPRO generates multiple instruction variations, tests different combinations of few-shot examples from your training data, and systematically evaluates each configuration’s performance. Within a few hundred evaluations, MIPRO converges on an effective prompt, which might look like this example:
Transform ambiguous user queries into precise, searchable questions that preserve the user's underlying intent while adding necessary specificity.
Question: weather tomorrow
Rewritten: What is the weather forecast for tomorrow in [user location]?
Question: latest on Tesla
Rewritten: What are the most recent news developments regarding Tesla Inc.?
Question: {query}
Rewritten:The revised instructions are more precise about the goal. The examples demonstrate the specific transformations you want. Most importantly, MIPRO selected these automatically based on measured performance, not intuition. This reflects the Stanford research, which demonstrates that MIPRO reduces errors in complex reasoning tasks.
Bayesian Optimization Meets Prompt Engineering
MIPRO, implemented as MIPROv2 in DSPy, optimizes prompts by tuning the instruction and example variables from finite sets of possibilities rather than continuous ranges. The tuning criteria consist of all possible combinations of candidate instructions and example sets. Even with modest constraints, such as 10 instruction variants and 5 examples from a pool of 50, you would need to explore 20 million possible configurations. Testing them all is expensive and inefficient, virtually impossible.
MIPRO’s core innovation solves this conundrum by using Bayesian optimization guided by a surrogate model.
Bayesian optimization is a technique for finding the maximum or minimum of functions that are expensive to evaluate. Instead of testing every possibility, it builds a probabilistic model of the function and uses that model to decide which points to test next. The Bayesian element updates the model beliefs about the function as it gathers more data, refining its approach with each test.
Here’s how MIPRO works in practice:
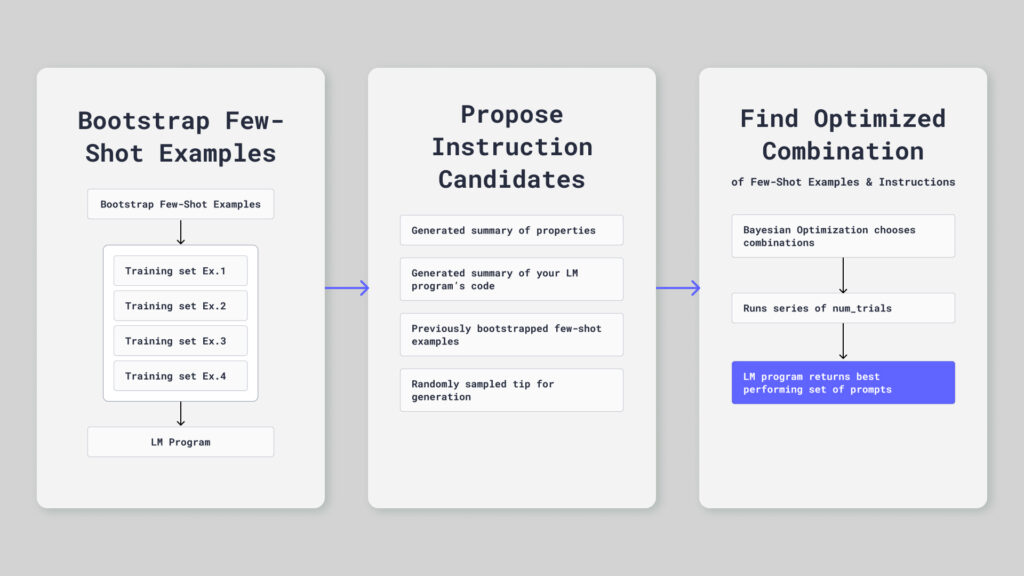
MIPRO starts by generating several variants for the instructions. It does this by prompting a model to create variations that might improve performance, often by analyzing failure cases from an initial baseline evaluation. For example, if your prompt fails on questions about specific products, MIPRO might generate an instruction variant that explicitly mentions handling product names.
Next, MIPRO builds a pool of candidates for your examples. You can use your training data and bootstrap examples. MIPRO selects the examples as a binary choice problem, deciding if each example is in or out of the few-shot context.
Rather than randomly testing configurations, MIPRO uses a surrogate model. This statistical model predicts how well a configuration will perform without actually running it. Think of it as a learned approximation. After the system evaluates a few dozen configurations, the model starts to understand which types of instructions and example combinations tend to work well together. The system initially trains this model on a small number of random evaluations, then updates it after each iteration as MIPRO gathers more performance data.
The optimizer uses this surrogate model to decide what to try next. It looks for configurations that either seem very promising based on the model’s predictions or sit in unexplored regions of the space where the model is uncertain. This balance is crucial because simply exploiting the model’s predictions gets stuck in local optima; meanwhile, exploring where the model is uncertain wastes compute on unlikely candidates. Pairing the two paths together maximizes the impact of the results.
For each iteration, MIPRO’s surrogate model proposes five to 10 new configurations that look promising. The system then actually evaluates these configurations on your validation set. This means your LLM runs with those prompts and you measure real performance. The results update the surrogate model, which in turn becomes more accurate about which configurations work well. The process repeats until you hit your evaluation budget or performance plateaus.
In the authors’ experiments from the original paper, MIPRO typically converged within 100 to 300 evaluations, or 20 to 50 full dataset evaluations. The researchers demonstrated substantial improvements across their benchmark tasks, with optimized prompts consistently outperforming hand-crafted baselines.
Pipeline Optimization Beats Isolated Prompt Tuning
Most LLM applications aren’t singular prompts. They’re pipelines with multiple stages, each with its own prompt. A RAG system might have separate modules for query analysis, passage ranking, and answer synthesis. A software development agent might have prompts for planning steps, selecting tools and APIs, executing code changes, and validating outputs. A customer support bot might have prompts for intent classification, knowledge base retrieval, response generation, and tone adjustment.
MIPRO addresses these realities by optimizing the entire pipeline. The system evaluates end-to-end performance rather than individual module performance.
This approach matters because prompt changes in one module affect downstream behavior. If you optimize your query reformulation prompt to be more specific, you might need different examples in your answer synthesis prompt to handle that increased specificity. Optimizing modules independently misses these interactions.
MIPRO runs within DSPy, a framework that structures LLM applications as composable modules with defined signatures (input/output types) and prompts that compile at runtime. This structure gives MIPRO visibility into the entire pipeline and enables it to measure how prompt changes in one module ripple through the system.
In multi-stage optimization, MIPRO treats each module’s prompt as a separate optimization variable but evaluates their joint effect on final output quality. Researchers found this holistic approach yielded higher accuracy than optimizing modules sequentially in certain benchmarks. These meaningful gains came purely from accounting for inter-module dependencies.
The Cost of Automation
MIPRO’s effectiveness comes at the cost of a higher evaluation budget. Each configuration requires running your LLM multiple times on your validation set. If you’re evaluating 200 examples and testing 150 configurations during optimization, that’s 30,000 calls to the LLM. For complex pipelines where each evaluation involves three to four API calls, you’re quickly looking at 100,000-plus calls per optimization run. These costs are acceptable for major application changes or when deploying to production, but could be unnecessarily expensive if you’re optimizing daily during rapid development cycles.
Time is another factor. Running 150 evaluations on a 200-example validation set could take a few hours depending on API rate limits and your pipeline’s complexity. This is acceptable for infrequent optimization but becomes a bottleneck if you’re iterating rapidly on your application design.
MIPRO needs enough evaluations to build an accurate surrogate model and explore the configuration space adequately. Cut the budget too aggressively and you risk premature convergence on mediocre prompts. The original paper found that diminishing returns set in around 200 to 300 evaluations for most tasks, making this a reasonable default budget.
The Bayesian optimization approach generally helps save time and money by being sample-efficient. Traditional grid search or random search might need 500 to 1,000 evaluations to find good configurations. MIPRO typically finds near-optimal prompts in 100 to 300 evaluations, which is a huge reduction in compute cost.
The Limitations of MIPRO
MIPRO’s instruction generation has a fundamentally obvious limitation: In MIPRO (and MIPROv2) a separate prompt model generates instruction candidates, the quality and diversity of those candidates depends on that model and the initial context you provide. The generated instruction prompts tend to follow predictable patterns, including more detailed task descriptions, different framings of the goal, and variations in specificity.
What MIPRO doesn’t discover are genuinely novel prompting strategies. Techniques like chain-of-thought prompting, self-consistency, or role-playing emerged from human experimentation and creativity, not automated optimization. MIPRO refines within a paradigm; it doesn’t invent new paradigms.
The Bayesian optimization component also has limits. When the true performance landscape is highly nonlinear or contains regions where performance is locally maximal but not globally optimal, the surrogate model struggles to guide search effectively. You might converge on a configuration that performs well but misses substantially better configurations elsewhere in the space.
The MIPRO framework also assumes your LLM evaluation metrics accurately capture what you care about. This is tricky in practice. You might optimize for exact match accuracy, but what you really want is answers that are factually correct and appropriately hedged. If your metric doesn’t capture this nuance, MIPRO will optimize for the wrong thing, and do so very efficiently.
Finally, MIPRO doesn’t handle distribution shift gracefully. This distribution shift can occur when your production traffic differs from your training and validation data. If users ask questions in different ways than your test set anticipated, the prompts optimized on your validation set might not generalize to production traffic with this gap. On some benchmarks, the original paper showed two to four percentage point drops when moving from validation to test sets. This shift isn’t catastrophic, but serves as a reminder that optimization is only as good as your data.
Creating A Lasting Impact
MIPRO proved that automated optimization can work. Before MIPRO, the conventional wisdom held that prompt engineering required human intuition, domain expertise, and extensive trial and error. MIPRO demonstrated you could treat it as a computational problem with measurable, reproducible results.
This validation catalyzed research into more sophisticated optimization approaches. Evolutionary algorithms showed they could explore more creative instruction variations by maintaining populations of prompts and applying mutation and crossover operations, similar to how genetic algorithms work in other optimization domains. Research teams have reported substantial improvements using evolutionary methods that build on MIPRO’s foundational work.
These improvements come from several advances. Evolutionary approaches can discover more creative instruction variations because they’re not limited to what an LLM can generate through meta-prompting. Gradient-based methods emerged as another option. While prompts are discrete text, researchers developed ways to approximate gradients with respect to prompt changes, enabling optimization techniques borrowed from continuous optimization. When gradients provide good directional information, these approaches can be more sample-efficient.
These methods all share the core insight MIPRO established: systematic, automated optimization beats manual iteration.
The specific algorithm matters. Evolutionary methods might discover more creative solutions. Gradient methods might converge faster. But the fundamental principle holds across approaches.
Beyond MIPRO’s Foundation
If you’re building LLM applications today, the question isn’t whether to automate prompt optimization but which tools to use. MIPRO’s original implementation remains available in DSPy and provides a solid foundation for understanding how these systems work. The framework offers a clear path from manual prompting to automated optimization. The research behind it is well-documented and reproducible.
However, the field has evolved substantially since MIPRO’s introduction. Modern optimizers build on MIPRO’s foundations while addressing its core limitations through more sophisticated search mechanisms and better instruction generation. Current evolutionary and reflective approaches explore more creative prompt variations and better model the interactions between instructions and examples. These advances deliver measurably stronger performance than MIPRO’s original results.
Opik provides an open-source platform for LLM evaluation and optimization that includes evolutionary optimization representing the next generation beyond MIPRO. The platform handles the evaluation infrastructure, metric tracking, and optimization orchestration that make automated prompt engineering practical for production use. Where MIPRO pioneered the concept of treating prompt optimization as a systematic engineering discipline, Opik’s evolutionary optimizer refines these techniques to deliver measurably better results.
The path forward clearly requires systematic optimization infrastructure, which beats manual prompt tweaking. MIPRO proved this approach works and established the foundational techniques. Modern tools have refined those techniques to deliver even stronger performance gains. Whether you’re building RAG systems, AI agents, or complex multi-stage pipelines, automated optimization transforms prompt engineering from an artisanal craft into a reproducible engineering practice with measurable outcomes.
Try Opik for free and see how evolutionary optimization delivers the next generation of prompt performance beyond what MIPRO pioneered.
