
An Introduction to Conversational AI
AI chatbots and other conversational AI offer 24/7 availability support, minimize errors, save costs, boost sales, and engage customers effectively. Businesses are drawn to chatbots not only for the aforementioned reasons but also due to their user-friendly creation process.
As per Gartner, the primary source of customer service will be AI chatbots for 25% of organizations by 2027. Additionally, Zendesk reports that 72% of business leaders prioritize expanding AI and chatbots across the customer experience within 2024.
Creating a chatbot is now more accessible with many development platforms available. Among many options, LangChain stands out as a powerful library for creating chatbots because it is flexible, scalable, and open-source.
This article lightly touches on the history and components of chatbots. Later, it explores the s the implementation of chatbots using LangChain and the experiment tracking using Comet.
Chatbots — Then and Now
Early chatbots could not grasp the context and nuances of language. One of the first chatbots, ELIZA, was developed in 1966 to mimic human interaction and had built-in scripts to create the illusion of intelligence.
Later, chatbots relied on rule-based systems and simpler machine learning approaches. These chatbots had limited capabilities and responded to specific keywords and phrases. This evolution paved the way for the development of conversational AI.
The recent rise of Large Language Models (LLMs) has been a game changer for the ChatBot industry. These models are trained on extensive data and have been the driving force behind conversational tools like BARD and ChatGPT. These LLM-based bots have found various applications in various industries and have become the go-to information source for many people.
However, chatbots are not only restricted to such commercial platforms, and developers can create their custom models using frameworks like LangChain.
What is LangChain?
LangChain is an open-source framework, available in Python and Javascript libraries, that enables users to build applications using LLMs. Fundamentally, LangChain operates as an LLM-centered framework, capable of building chatbot applications, Visual Question-Answering (VQA), summarization, and much more.
Think of LangChain as a toolbox for Python and Javascript that provides ready-to-use building blocks for working with language models. These building blocks, similar to functions and object classes, are essential components for creating generative AI programs. These components connect seamlessly, allowing you to build applications with less code and without requiring complicated natural language processing (NLP) tasks.
A distinctive feature of LangChain is its innovative Agents. They operate on the fundamental concept of utilizing a language model to decide on a sequence of actions. Agents leverage a language model as a reasoning engine to determine the actions and their order dynamically.
Components of Conversational AI
The LangChain framework includes various modules, each of which adds to the chatbot’s functionality. This section will explore each component in detail and discuss how it facilitates the creation of a functional chatbot.
Chat Model
Chat models are a category of LLMs specifically trained to output human-like, conversational responses. LLMs and chat models are slightly different as LLMs are pure text completion models, and chat models are fine-tuned for having conversations.
Chat models utilize a distinct input interface compared to LLMs, accepting a list of chat messages labeled as System, AI, and Human. The AI chat message is then provided as the output from the chat model. LangChain provides a diverse range of chat models and also accommodates custom chat models.
Prompt Template
Prompt acts as a set of instructions or input to the language model by a user to guide model response. The purpose of prompting is to help chat models understand the context and generate relevant outputs.
Prompt templates serve as predefined formulas for crafting and reusing prompts across multiple language models. Language models commonly anticipate prompts as a string or a list of conversational messages.
Since the prompts are a list of messages, we can use `ChatPromptTemplate` for it. Each chat message is associated with content and role, e.g., Human, AI, or a system role.
Chains
A stand-alone LLM is great for basic tasks, but intricate applications require a complex architecture that chains multiple components with the model. LangChain-supported chains include LLMChain, RouterChain, and SequentialChain. The most basic chain is the LLMChain, which combines the LLM, prompt, and optionally an output parser.
Memory
A key component of natural conversation is the ability to reference prior information, which must be stored in memory for later use. In LangChain, the `memory` component solves the problem by simply keeping track of previous conversations.
Every chain in LangChain defines some core execution that expects certain inputs. Some inputs originate directly from the user, others are retrieved from the memory. When chains are executed, they interact with the memory system twice. First, when it receives the input from the user, it will read from the memory and augment the user inputs.
Additionally, prior to delivering the output, the chain will record the inputs and outputs of the ongoing execution in the memory.
Documents
Chatbots are most useful to businesses when custom-trained for a specific domain. LangChain loads training data in the form of ‘Documents’, and these contain text from various sources and their respective metadata. The `Document` class provides various document loader methods to load data from sources, including PDF, HTML, JSON, and CSV.
Retriever
It’s essential for chat models to extract only the information from relevant documents given a query for accurate responses. Retrievers do this job of returning documents by providing a query as input and returning a list of documents.
Building a Conversation AI With LangChain and Comet
The following section will guide you through the explanation and implementation of a retail chatbot. The chatbot will provide users with information about retail products, detailing specifications, prices, and reviews.
Setup
The following chatbot uses OpenAI’s chat model GPT-3.5-turbo and, therefore, includes OpenAI’s API key. Users can get the API key by creating a free account here. Additionally, the application will be monitored using the Comet platform to keep track of all inputs and outputs. First, we will need to create a Comet account to access its API key.
Afterwards, we need to install the following libraries using the PIP package manager. Run the following command:
!pip install langchain openai comet_ml comet-llm textstat tiktoken faiss-gpu```
Chat Models
As discussed above, chat models are backed by LLMs such as GPT or Anthropic and are essential for conversational AI. They specialize in having a conversation rather than text completion. For this chatbot, we will be using GPT-3.5. There are many chat models supported in LangChain that can be found here.
Here’s a snippet to initialize a chat model:
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature = 0.4, openai_api_key="...")
Here, the temperature parameters adjust the creativity of the response as it increases with a higher temperature.
Prompt
Prompts guide chatbots in responding to queries. LangChain provides prompt templates that simplify the creation of prompts by combining default messages, user input, and chat history.
The following is the prompt for the chatbot:
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
)
instructions = """You are a friendly chatbot capable of answering questions related to products. Users can ask questions about its specifications, prices, and reviews. Be polite and redirect conversation specifically to product information when necessary."""
human = """ Chat history of the user: {chat_history} New human question: {input} """
prompt = ChatPromptTemplate(messages=[
SystemMessagePromptTemplate.from_template(instructions), # Guidance
HumanMessagePromptTemplate.from_template(human), #User query],
input_variables=['chat_history','input'] # variables)
Memory
Memory is important for conversational AI, as it allows the conversation to be stored and adds it to the current query for reference of the previous conversation. There are many memories supported by LangChain, as discussed above.
Now, we will use ConversationBufferWindowMemory to track the last four interactions. Here’s how to create it:
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(memory_key = "chat_history",k = 4)
The parameter `k` determines how many previous conversations need to go to the chat model.
Chains
Chains are a simple concept of connecting different pieces, like language models, prompts, memory buffers, etc, into a single chain.
Here’s how the previous components can be connected to make the chatbot:
from langchain.chains import ConversationChain
conversation = ConversationChain(llm = llm,
prompt = prompt,
memory = memory,
verbose = False) # LLMChain conversation
conversation.run("Hi, my name is Bob.")
#### AI: Hey Bob, how can I help you?
conversation.run("What is my name?")
#### AI: Your name is Bob. Is there anything else I can help you with?
As we can see, the chatbot is using the previous conversation. `ConversationChain()` takes in multiple parameters such as LLM, prompt and memory to respond to the queries of users, but this chatbot does not have the information of the products.
Documents
Our chatbot requires documents for lookup and answering product-related questions which include reviews, product specifications, and prices.
So, let’s download the dataset from the data world.
import pandas as pd
df = pd.read_csv(
'https://query.data.world/s/76kyenosebb7rtcruaarjgnfogum66?dws=00000')
df.to_csv('product.csv',
sep=',',
index=False,
encoding='utf-8') #Saving as a csv
- Load: In order to load the CSV dataset, LangChain provides CSVLoader. Here’s how to load the CSV file.
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='product.csv',
csv_args={ 'delimiter': ','})
data = loader.load()
- Split: Here we need special care as we can not pass in data without splitting because the context that will be passed later to the LLM can exceed the token limit. Therefore, we need to split the data. Here’s how:
from langchain.text_splitter import RecursiveCharacterTextSplitter
Splitter = RecursiveCharacterTextSplitter(chunk_size = 1500, chunk_overlap = 150)
splits = Splitter.create_documents(
[datum.page_content for datum in data]
)
In the snippet, the text splitter is splitting the document in equal 1500 characters with an overlapping chunk of 150. This will create more documents but with fewer words in each document.
Retriever
Retrievers can be created very easily using vector stores. Here we will be using the FAISS vector store and using OpenAI’s embeddings.
Let’s look at a code snippet:
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings( openai_api_key="...")
vectorstore = FAISS.from_documents(splits, embeddings)
LangChain establishes a Retriever interface that encapsulates an index capable of providing pertinent documents in response to a textual query. All retrievers uniformly implement the method `get_relevant_documents().`
Additionally, it is required to pass in the context to the prompt template. We can fix it by passing context as input:
instructions = """...""" # Same instructions as above
human = """ The context is provided as: {context} New human question: {question} """
prompt = ChatPromptTemplate( messages=[#same as above], input_variables=['context','question'])
LangChain conversation Retrieval chain is very useful to cater memory, retriever and prompt altogether. Here’s the code snippet:
from langchain.chains import ConversationalRetrievalChain
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 5})
qa = ConversationalRetrievalChain.from_llm(llm = llm, memory=memory, get_chat_history=lambda x : x,
retriever=retriever,
combine_docs_chain_kwargs={"prompt": prompt})
The retriever is searching the similarity of the query with documents which will result in the first five relevant documents. These will be passed as a context to the chat model.
Now, let’s create a simple function to chat with the chatbot:
def predict(question):
ai_msg = qa({"question":question})['answer']
return ai_msg
Here are the results from the chatbot:
predict("Hi, my name is Bob?")
### Hello Bob! How can I assist you today?
predict("What can you do?")
### As a chatbot, my capabilities include answering questions about product specifications, prices, and reviews. I can provide information on a wide range of products. If you have any specific questions or need assistance with a particular product, feel free to ask!
predict("What's the price kindle paperwhite?")
### The base model of the Kindle Paperwhite is priced at $99.
Tracking and Monitoring Conversational AI with Comet
When creating applications with LLMs, most of the time is spent on prompt engineering rather than training the models. This has introduced a new area of expertise: LLMOps.
Comet has a rich set of features for LLMOps:
- LLM Projects: It is designed for analyzing prompts, responses, and chaining.
- LLM Panels: While working with LLMs, workflows may involve a combination of fine-tuning and prompt engineering. This can be tracked using either separate projects for each part or a single project with LLM panels.
After creating the Comet account, go to accounts settings and generate an API key. After logging in successfully, go to account settings and generate an API key.
Next, simply replace with the following texts:
COMET_API_KEY = "COMET_API_KEY"
COMET_WORKSPACE = "COMET_WORKSPACE"
PROJECT_NAME = "Product-Bot-v1" # initialize comet comet_llm.init(COMET_API_KEY, COMET_WORKSPACE, project=PROJECT_NAME)
Tracking Conversational AI
Now, to track the outputs of the conversational AI and check whether the prompt is good for your use case, Comet has a simple function log_prompt.
queries = ["Hi,my name is Bob?",
"What can you do?",
"What is the best product?",
"What's the price kindle paperwhite?"]
expected_response = ["Hello, how can you assist you.",
"As a chatbot, my capabilities include answering questions about product specifications, prices, and reviews. \ I can provide information about various products and assist you in finding the information you need. \ If you have any specific questions or need assistance with a particular product, feel free to ask.",
"Based on the information provided, there is no single clear winner among the tablets mentioned.\ Each tablet has its own strengths and weaknesses. The Amazon HDX and Nexus are praised for their pricing, \ while Apple and Google have more app choices. If you are heavily invested in the Apple ecosystem, \ the iPad Mini might be a good choice. Ultimately, the best product will depend on your personal preferences and requirements.",
"The base model of the Kindle Paperwhite is priced at $99."]
for index, convo in enumerate(queries): # log the few-shot predictions
comet_llm.log_prompt(prompt=convo,
prompt_template= instructions,
output=predict(convo),
tags = ["gpt-3.5-turbo", "prompt_1"],
metadata = { "expected_answer":
expected_response[index]})
The function log_prompt requires two parameters: user query and output of the model. The rest are optional like prompt template, metadata, tags, etc.
After this step, the logs will be on the Comet’s LLMOps dashboard:
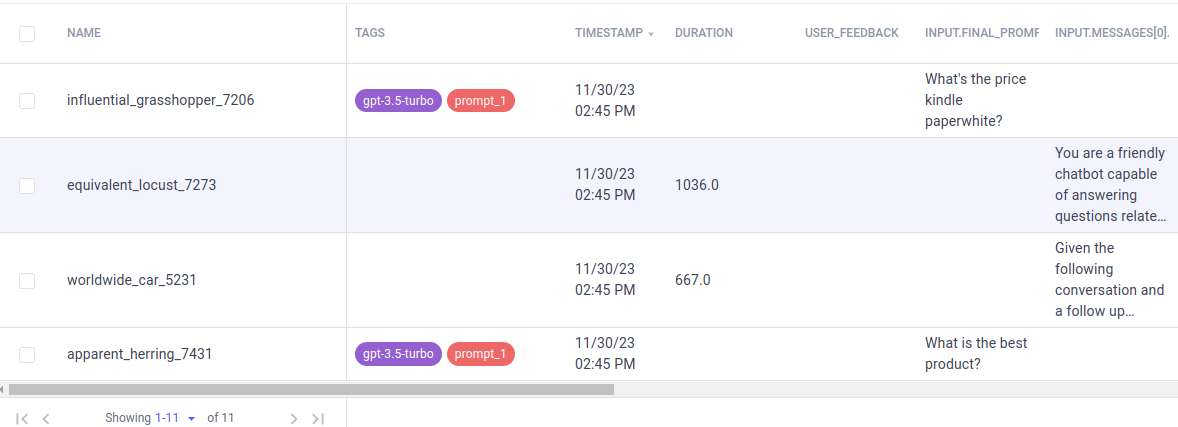
Each column represents necessary information like name is a unique identifier, tags are used for classification, input_prompt represents the user query and so on. Comet provides many other features for LLMOps to make the development of chatbots and other conversational AI easier and more organized.
There are many other useful ways to represent information. For example, the group by option is used to group prompts on columns.

Conversational AI: Key Takeaways
LangChain emerges as a robust open-source framework for creating chatbots, offering flexibility and scalability. With components like Chat Models, Prompt Templates, Chains, Memory, Documents, and Retrievers, LangChain simplifies chatbot development, catering to diverse business needs.
Comet, a monitoring and tracking tool, complements LangChain seamlessly. Simplifying LLMOps, Comet’s features like LLM Projects and Panels aid in prompt analysis, response evaluation, and chaining visualization. Comet’s platform is utilized by data science and machine learning teams to monitor, contrast and enhance models, including the leading conversational AI applications of today.
