Facebook AI’s new unsupervised approach to speech recognition, Sweetviz + Comet for supercharged EDA, and more
Welcome to issue #3 of The Comet Newsletter!
This week, we take a closer look at Facebook’s impressive new unsupervised approach to speech recognition and the concept of “In-context learning” as it relates to GPT-3.
Additionally, you might enjoy a new way to automatically visualize and log your EDA experiments with Sweetviz+Comet, as well as some compelling perspective on the issue of academic fraud in the ML community.
Like what you’re reading? Subscribe here.
And be sure to follow us on Twitter and LinkedIn — drop us a note if you have something we should cover in an upcoming issue!
Happy Reading,
Austin
Head of Community, Comet
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
Facebook AI: High-performance speech recognition with no supervision at all
Traditionally, speech recognition systems require thousands of hours of annotated speech and text data in order to correctly identify phonemes. This limits the technology to only a small fraction of all the languages spoken on earth and largely favors the American Dialect of English, as it is the largest annotated corpus of data.
Facebook AI Research (FAIR) recently open sourced their new unsupervised learning approach for speech recognition. Their approach leverages self-supervised speech representations from their previously published wav2vec model to segment unlabeled audio and learn a mapping from these representations to phonemes via adversarial training.
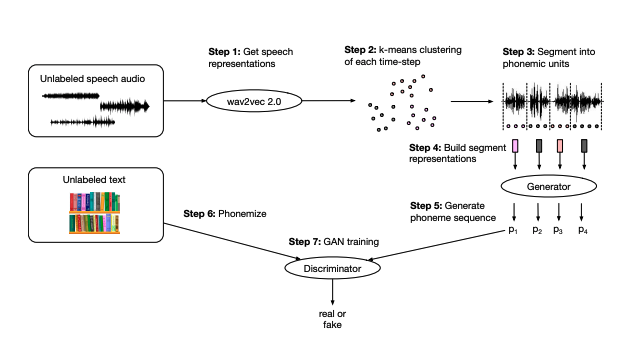
The performance of this method on benchmark datasets is truly astounding. Wav2Vec-U is able to achieve a word error rate of 5.9% with zero hours of annotated data. This is comparable to the best speech recognition system from 2019, Spec-Augment, which required at least 960+ hours of labeled data.
The dependency on labelled training data is a huge barrier to scaling and democratizing machine learning technology globally, since it just isn’t possible to collect high-quality, annotated data for every possible language. This approach from Facebook seems like the breakthrough that could lead to speech recognition systems being available in all spoken languages. Learning across all language types implies that these models are comprehensive enough to learn some “higher level” representation of the data in a way that humans cannot.
“We are moving from ‘all problems that can be solved with a declarative program’ to ‘all problems that can be express[ed] as inputs and outputs’ – which is – um – a lot of problems?”
Mike Schroepfer (@schrep), CTO at Facebook
Read the full overview from Facebook AI.
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
GPT-3 and In-context Learning

In this post, researchers at Stanford explore an interesting emergent phenomenon within the GPT-3 model: In-context learning.
In-context learning refers to a form of learning where the model is fed an input that describes a new task along with a set of examples. The resulting output behaves as if the model has “learned” the input description task.
The aim is to have the model produce an output that is simply a copy of the input. The model has not been explicitly trained for this purpose. The output sequence is generated based on the context provided by the prompt.
For example, the researchers fed in the following sequence completion task as a prompt
Input: g, c, b, h, d
Output: g, c, b, h, d
Input: b, g, d, h, a
Output: b, g, d, h, a
Input: a, b, c, d, e
Output:
The expected completion:
a, b, c, d, e
The team went through many different prompts to test GPT-3’s in-context learning ability. They tested the accuracy of the model by varying the number of prompts and the model size. What they found was that the accuracy of the output consistently increased when more in-context examples were provided and in general, results were better when the task was concordant with the expected semantics.
“The idea that simply minimizing the negative log loss of a single next-word-prediction objective implies this apparent optimization of many more arbitrary tasks – amounting to a paradigm of “learning” during inference time – is a powerful one, and one that raises many questions.” – Frieda Rong (@frieda_rong)
Read Frieda’s full blog post here.
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
Automatically Track your EDA with Sweetviz + Comet
Sweetviz is an excellent Python library that, with just two lines of code, allows you to jumpstart your Exploratory Data Analysis (EDA) with a range of rich visualizations. In other words…a perfect fit to integrate with Comet!
In a new article on Towards Data Science, Francois Bertrand, the engineer behind Sweetviz, shows how this integration can help accelerate your EDA work, while ensuring you’re able to track and manage your dataset experimentation history.
Read Francois’s full article here
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
Please Commit More Blatant Academic Fraud

Jacob Buckman (@jacobmbuckman), current PhD student at MILA and former Google AI Resident, shares his perspective on the first well-documented case of academic fraud in the Artificial Intelligence Community. The incident centers on a group of academics forming collusion rings in order to get their papers accepted at top conferences.
Buckman posits that this blatant fraud is the natural extension of the day-to-day fraud that most academics in the ML community are prone to committing. Things such as, “Running a big hyperparameter sweep on your proposed approach but using the defaults for the baseline” or “Cherry-picking examples where your model looks good, or cherry-picking whole datasets to test on, where you’ve confirmed your model’s advantage.”
He argues that this type of low-key fraud is indistinguishable from simple mistakes—and comes with plausible deniability. Almost everyone in the ML community is complicit with this subtle fraud, and as a result nobody is willing to accept its existence.
“We have developed a collective blind-spot around a depressing reality,” Buckman says. “Even at top conferences, the median published paper contains no truth or insight.”
By participating in this blatant case of fraud that is no longer within the bounds of plausible deniability, the researchers in the collusion ring may have finally succeeded in forcing the community to acknowledge one of its blind spots.
