LLMs are powerful, but turning them into reliable, adaptable AI agents is a whole different game. After designing the architecture for several agentic AI systems myself, I’ve learned that success doesn’t come from prompt engineering alone. It comes from modular design, observability that isn’t an afterthought, and strong feedback loops that help your system improve with every interaction. I’ve learned that good AI agent design patterns has the following:
🧠 Modular and Role-Based Design: Multi-agent systems are the most effective when each agent has a specialized task.
📡 LLM Observability: Log every step in the process, and create metrics for LLM monitoring performance.
🔁 Agent Optimization: Allow the agent to automatically learn and improve from feedback loops.
In this post, I’ll share a practical breakdown of the design principles for AI agent architecture that have helped me ship and scale real-world AI agents, and why applying software engineering thinking to LLM systems is the key to moving beyond brittle demos.
What is an AI agent, really?
Before we dive into agentic AI design, let’s settle an age-old debate and confusion: what is an agent?
Over the history of mathematics, different mathematical frameworks have developed somewhat separately, and we’ve ended up with similar, if not the same, concepts defined and represented differently within separate mathematical paradigms. Let’s not do that again.
A generalized “agent” has already been defined in the context of reinforcement learning (source: Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Barto), and this classic definition maps surprisingly well onto the LLM-powered agents we are all abuzz about today.
An agent is a system that perceives its environment, makes decisions, and takes actions to achieve specific goals autonomously (or semi-autonomously), and then adapts to feedback loops.
This definition is beautifully general—it encompasses everything from simple chatbots to sophisticated multi agent orchestration systems, while providing a foundation we can build upon as we discover more advanced and specialized agent types.
The Agent Adoption Chasm
I’m also noticing this gap in the adoption of true agentic AI. There is a chasm between using AI in our day-to-day workflows and building and integrating truly autonomous agents.
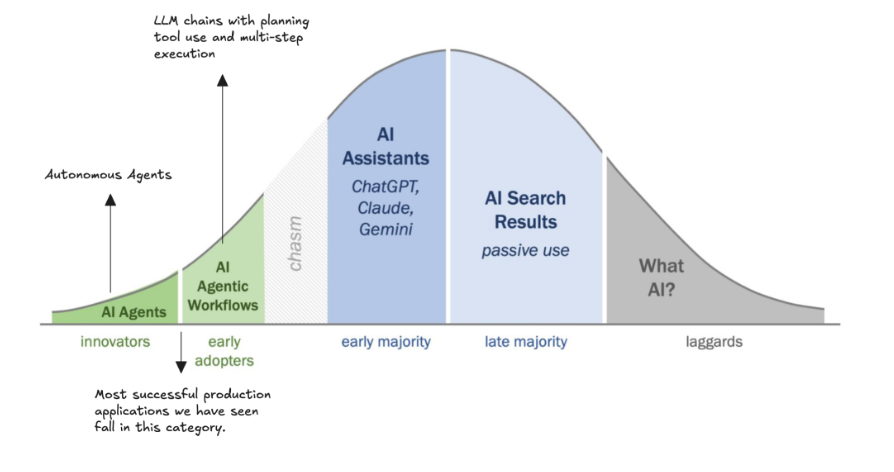
- What’s AI? – These folks are lagging behind the adoption curve, but we can help them! Educate your friends and family about the capabilities and limitations of AI so they don’t get left behind.
- AI Search Results – I don’t Google things anymore, I ask ChatGPT.
- AI Assistants – Many of us are using LLM assistants day-to-day in our work to improve our efficiency.
- AI Agentic Workflows – Workflows are LLM chains with planning, “reasoning,” and automated multi-step tool use. They’re moving towards autonomous agents, but they’re not fully there yet.
- AI Agents – truly autonomous and self-improving AI agents
To close this chasm, building and maintaining truly reliable AI agents must become easy and intuitive. And that all comes down to the architectural decisions we make as we build them, and the maturity of the tools we have available to build with.
AI Agent Architecture
After countless iterations and some failures on AI agent designs, I’ve identified three non-negotiable principles that separate mediocre agent architectures from transformational ones.
🧠 Modular & Role-Based AI Agent Design
Modular and role-based design is a foundational principle for building scalable and maintainable agent architectures. Designing a single, monolithic agent to handle everything is a recipe for spaghetti. If your system’s logic is contained in a single prompt, it will become very difficult to measure and improve the system overall and pinpoint specific issues.
So instead of building one giant agent that does everything, break your system into smaller, role-specific components. Rather than creating a single, monolithic agent responsible for every task, this approach breaks the system into specialized agents, each with a clearly defined role.
This approach mirrors good software engineering:
- 🧠 Each agent or tool has one responsibility.
- 🧪 Individual modules can be tested and debugged in isolation.
- 🔄 You can optimize or replace agents and tools without breaking the whole system.
👉 Why it matters: Modular design increases scalability, improves interpretability, and helps avoid the dreaded prompt spaghetti. This compartmentalization mirrors proven software engineering patterns, making the system easier to test, debug, and extend. It also enables better observability and optimization, as each agent’s behavior and performance can be analyzed in isolation.
📡 Deep Observability from Day 1
An agent isn’t done once it runs. The journey of adding value and improving is only just beginning. We should also consider LLM observability before we ship a live agent. Agents are unpredictable. They can fail silently, hallucinate, or experience concept drift.
As AI develops towards language-based decision systems like LLM agents, observability becomes absolutely critical. As software engineers or developers, you may already be familiar with or an expert in monitoring your software systems. But AI systems present unique design challenges and components that need a different approach to observability.
- Don’t wait until things break. Integrate LLM observability tools early. (Pro tip: use open-source LLM evaluation frameworks like Opik)!
- Track token usage, latency, success rates, and LLM inputs and outputs.
- Add LLM-as-a-judge or LLM juries eval metrics to measure quality consistently.
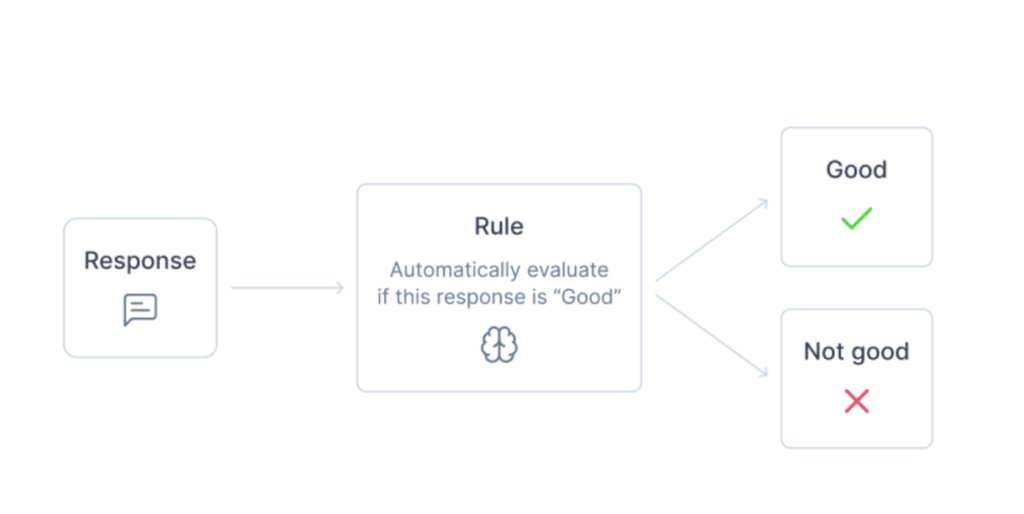
In the context of agent observability, LLM-as-a-judge is a powerful technique for evaluating the quality of an agent’s outputs without requiring constant human review. Instead of relying solely on manual feedback or brittle heuristics, this approach utilizes a trusted language model to score or critique the agent’s responses based on criteria such as accuracy, relevance, tone, or task completion.
LLM-as-a-judge eval metrics are especially useful in complex multi-agent workflows where subjective quality matters. For example, ranking research summaries, assessing reasoning steps, or for hallucination detection. When integrated into your observability stack (e.g., with tools like Opik), LLM-as-a-judge enables metrics for automated, scalable LLM evaluation pipelines that help you monitor performance over time, debug regressions, and fine-tune behavior based on structured feedback.
👉 Why it matters: You can’t optimize or trust what you can’t observe. Layer in logging and LLM evaluation metrics early in your development process. Deep observability turns your agent from a black box into a transparent, debuggable system.
🔁 Feedback Loops & Iterative Optimization
Feedback loops and iterative optimization built into the agent architecture design separate static chatbots from truly intelligent agents that evolve and improve over time.
We’re witnessing a fundamental shift in how intelligent systems operate. To me, the gap between simple LLM interactions and truly autonomous agents represents one of the most exciting frontiers in AI development. Building agents isn’t just about the technical architecture; it’s about creating systems that can handle the chaos of real-world deployment.
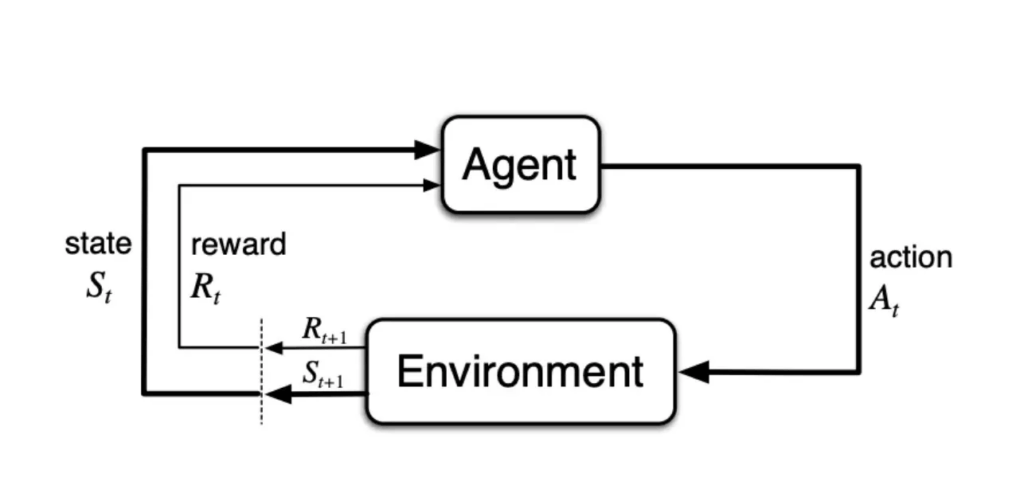
An AI system may work well on test data during development, and even perform as expected on new data once it’s live. But it’s common for live data patterns to shift, and your agent will encounter new, unseen edge cases in the data it experiences in the live environment. In these production settings, agents face unpredictable inputs, edge cases, and shifting user needs, and this means the initial prompt or logic is rarely perfect.
So, live feedback loops and iterative optimization are essential for building AI agents that evolve beyond static behavior and allow agentic systems to improve over time by continuously learning and adjusting based on real-world performance.
We can also leverage feedback loops in Automatic Prompt Optimization to create systems that improve themselves in an iterative fashion.
By incorporating structured feedback from users, automated evaluations (like LLM-as-a-judge), or LLM tracing data, developers can iteratively refine how the agent reasons, chooses tools, or responds to queries. Over time, this leads to more reliable, accurate, and efficient agent performance.
The Feedback Sources That Actually Matter:
- User ratings and explicit feedback
- Automated evaluation signals and metrics
- Collecting trace data showing decision patterns
- A/B testing results across different prompts
- Human-in-the-loop (HITL) corrections
- Self-reflection patterns where agents critique their own outputs
Implementation Strategies:
- Feed evaluation data back into prompt tuning processes
- Continuously optimize RAG components based on retrieval success
- Adjust agent routing logic based on performance patterns
- Build self-correction mechanisms into agent workflows
👉 Why it matters: Continuous feedback is what turns an “okay” agent into a great one. This is how we close the adoption chasm and move towards building truly autonomous, self-improving agents.
Sounds a lot like reinforcement learning, doesn’t it? 🤖 That’s because the fundamental principles are the same. AI agents learn from environmental feedback to optimize their behavior over time. This framework is how we get toward truly autonomous, self-improving agentic systems. I’m convinced that thinking about AI systems in the proper mathematical framework is the key to innovation of more complex and autonomously capable AI that can be measured and controlled in these chaotic real-world environments.
I’m excited to see what you build! 🚀
