Observability for AutoGen with Opik
Autogen is a framework for building AI agents and applications built and maintained by Microsoft.
Autogen’s primary advantage is its enterprise-ready architecture with built-in logging and observability features, making it ideal for production multi-agent systems that require robust monitoring and debugging capabilities.
Getting started
To use the Autogen integration with Opik, you will need to have the following packages installed:
In addition, you will need to set the following environment variables to configure the OpenTelemetry integration:
Opik Cloud
Enterprise deployment
Self-hosted instance
If you are using Opik Cloud, you will need to set the following environment variables:
To log the traces to a specific project, you can add the
projectName parameter to the OTEL_EXPORTER_OTLP_HEADERS
environment variable:
You can also update the Comet-Workspace parameter to a different
value if you would like to log the data to a different workspace.
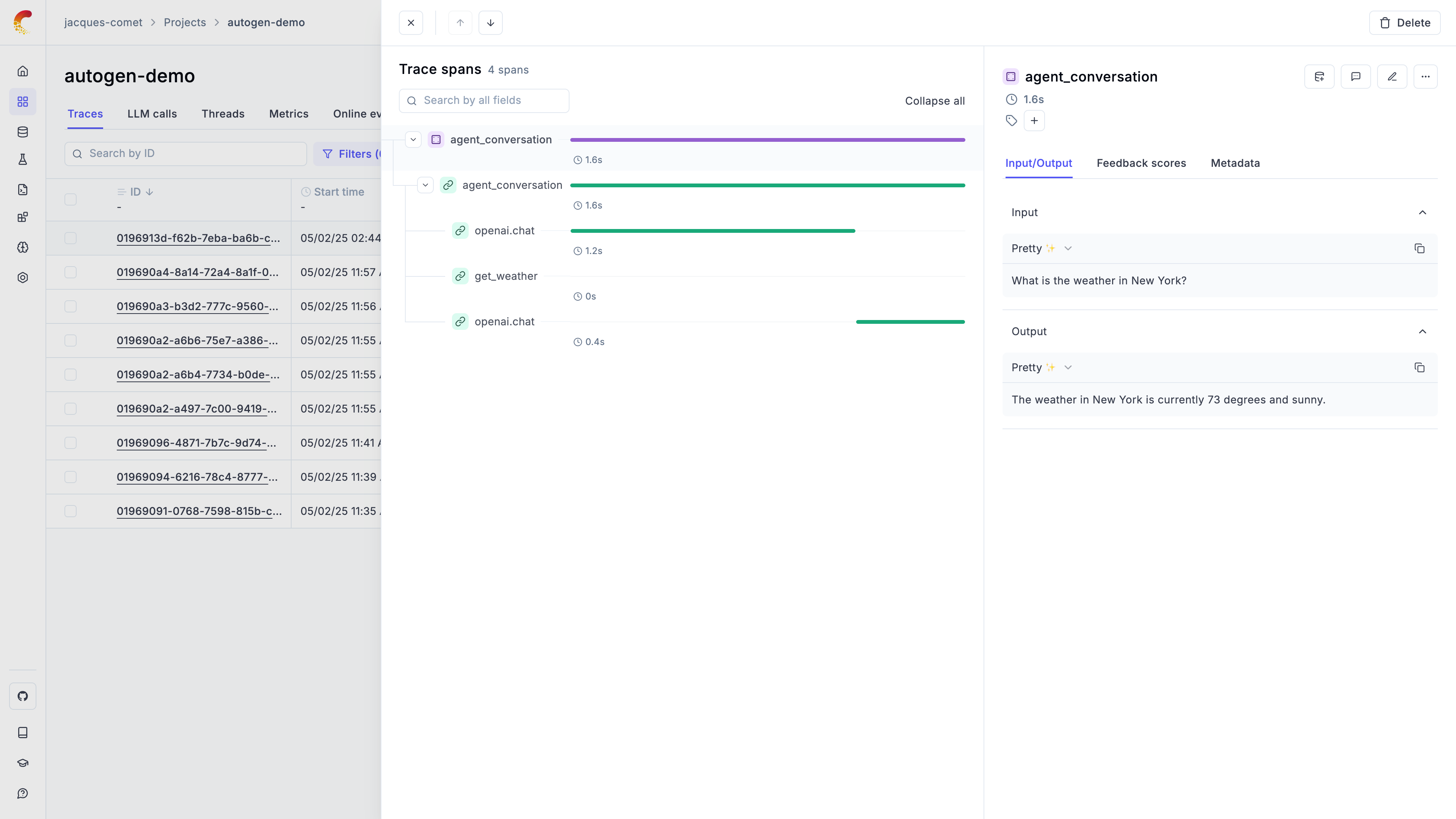
Using Opik with Autogen
The Autogen library includes some examples on how to integrate with OpenTelemetry compatible tools, you can learn more about it here:
- If you are using autogen-core
- If you are using autogen_agentchat
In the example below, we will focus on the autogen_agentchat library that is a
little easier to use:
Further improvements
If you would like to see us improve this integration, simply open a new feature request on Github.