Evaluate threads
Step-by-step guide on how to evaluate conversation threads
When you are running multi-turn conversations using frameworks that support LLM agents, the Opik integration will automatically group related traces into conversation threads using parameters suitable for each framework.
This guide will walk you through the process of evaluating and optimizing conversation threads in Opik using
the evaluate_threads function in the Python SDK.
For complete API reference documentation, see the evaluate_threads API reference.
Using the Python SDK
The Python SDK provides a simple and efficient way to evaluate and optimize conversation threads using the
evaluate_threads function. This function allows you to specify a filter string to select specific threads for
evaluation, a list of metrics to apply to each thread, and it returns a ThreadsEvaluationResult object
containing the evaluation results and feedback scores.
Most importantly, this function automatically uploads the feedback scores to your traces in Opik! So, once evaluation is completed, you can also see the results in the UI.
To run the threads evaluation, you can use the following code:
Want to create your own custom conversation metrics? Check out the Custom Conversation Metrics guide to learn how to build specialized metrics for evaluating multi-turn dialogues.
Understanding the Transform Arguments
Threads consist of multiple traces, and each trace has an input and output. In practice, these typically contain user messages and agent responses. However, trace inputs and outputs are rarely just simple strings—they are usually complex data structures whose exact format depends on your agent framework.
To handle this complexity, you need to provide trace_input_transform and trace_output_transform functions. These are critical parameters that tell Opik how to extract the actual message content from your framework-specific trace structure.
Why Transform Functions Are Needed
Different agent frameworks structure their trace data differently:
- LangChain might store messages in
{"messages": [{"content": "..."}]} - CrewAI might use
{"task": {"description": "..."}} - Custom implementations can have any structure you’ve defined
Without transform functions, Opik wouldn’t know where to find the actual user questions and agent responses within your trace data.
How Transform Functions Work
Using these functions, the Opik evaluation engine will convert your threads chosen for evaluation into the standardized format expected by all Opik thread evaluation metrics:
Example:
If your trace input has the following structure:
Then your trace_input_transform should be:
Don’t want to deal with transformations because your traces don’t have a consistent format? Try using LLM-based transformations, language models are good at this!.
Using filter string
The evaluate_threads function takes a filter string as an argument. This string is used to select the threads that
should be evaluated. For example, if you want to evaluate only threads that have a specific ID, you can use the
following filter string:
You can combine multiple filter strings using the AND operator. For example, if you want to evaluate only threads
that have a specific ID and were created after a certain date, you can use the following filter string:
Supported filter fields and operators
The evaluate_threads function supports the following filter fields in the filter_string using Opik Query Language (OQL).
All fields and operators are the same as those supported by search_traces and search_spans:
Rules:
- String values must be wrapped in double quotes
- DateTime fields require ISO 8601 format (e.g., “2024-01-01T00:00:00Z”)
- Use dot notation for nested objects:
metadata.model,feedback_scores.accuracy - Multiple conditions can be combined with
AND(OR is not supported)
The feedback_scores field is a dictionary where the keys are the metric names and the values are the metric values.
You can use it to filter threads based on their feedback scores. For example, if you want to evaluate only threads
that have a specific user frustration score, you can use the following filter string:
Where user_frustration_score is the name of the user frustration metric and 0.5 is the threshold value to filter by.
Best practice: If you are using SDK for thread evaluation, automate it by setting up a scheduled cron job with filters to regularly generate feedback scores for specific traces.
Using Opik UI to view results
Once the evaluation is complete, you can access the evaluation results in the Opik UI. Not only you will be able to see the score values, but the LLM-judge reasoning behind these values too!
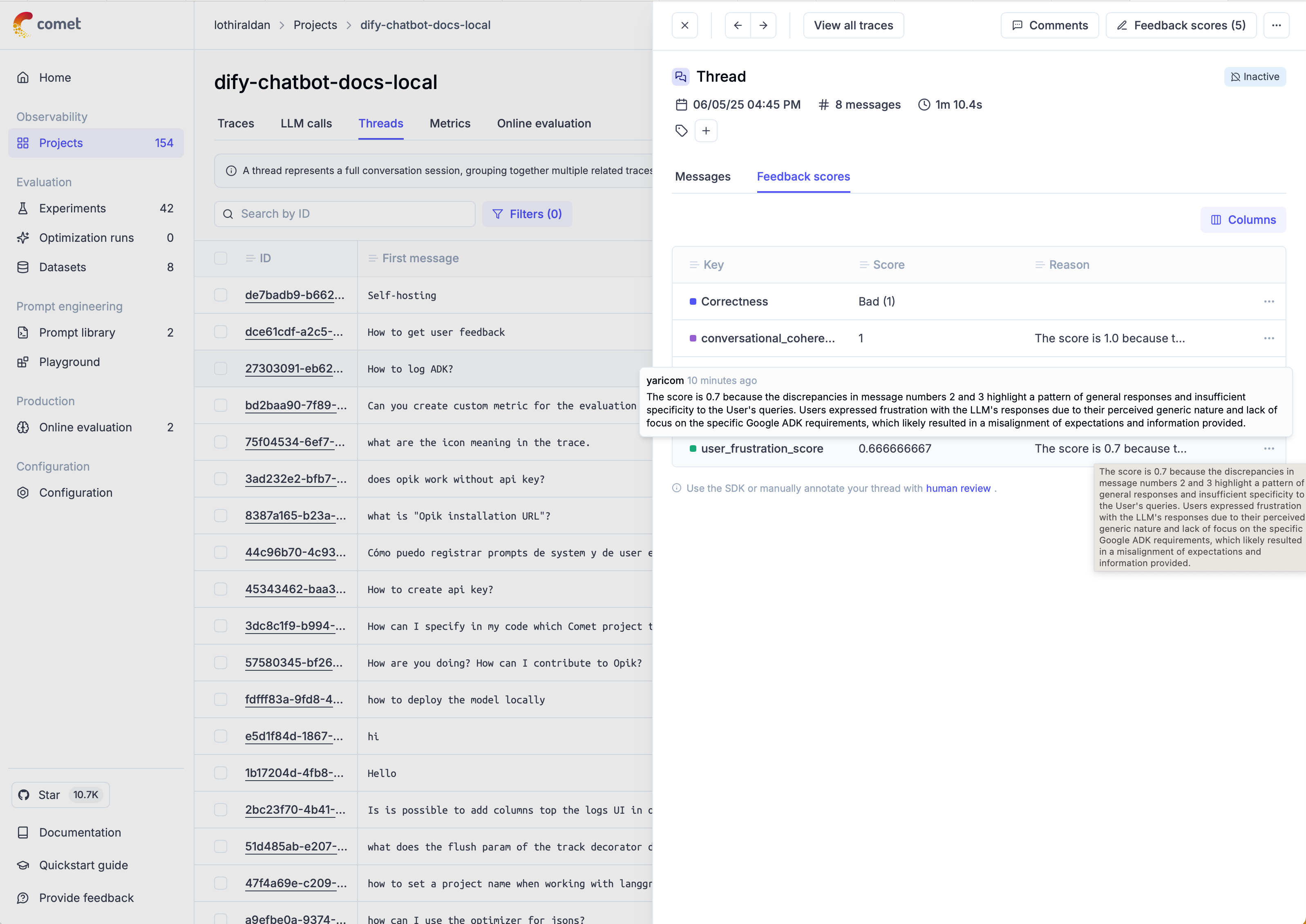
SDK Evaluation vs. Manual Feedback:
- When using the SDK’s
evaluate_threadsfunction, only threads marked as “inactive” (after the cooldown period) are evaluated. This ensures you’re scoring complete conversations. - You can manually add feedback scores to any thread at any time through the UI or API, regardless of its status.
- For thread-level online evaluation rules (automatic scoring), Opik waits for a configurable “cooldown period” after the last activity before running the rules.
Multi-Value Feedback Scores for Threads
Team-based thread evaluation enables multiple evaluators to score conversation threads independently, providing more reliable assessment of multi-turn dialogue quality.
Key benefits for thread evaluation:
- Conversation complexity scoring - Multiple reviewers can assess different aspects like coherence, user satisfaction, and goal completion across conversation turns
- Reduced evaluation bias - Individual subjectivity in judging conversational quality is mitigated through team consensus
- Thread-specific metrics - Teams can collaboratively evaluate conversation-specific aspects like frustration levels, topic drift, and resolution success
This collaborative approach is especially valuable for conversational threads where dialogue quality, context maintenance, and user experience assessment often require multiple expert perspectives.
Next steps
For more details on what metrics can be used to score conversational threads, refer to the conversational metrics page.
You can also define custom metrics to evaluate conversational threads, including LLM-as-a-Judge (LLM-J) reasoning metrics, as described in the following section: Custom Conversation Metrics guide.