
-
What Is an Agent Harness? The Layer That Makes AI Agents Actually Work
If you’ve shipped an LLM-powered feature beyond a simple chat interface, you’ve already built parts of an agent harness. The…

-
How We Optimized Opik’s MCP Server for Cost & Performance
Like a lot of engineering teams, earlier this year we found ourselves hitting limits on AI token spend, trying to…

-
Engineering Insights: How Internal Optimizations Led to Comet Cost Intelligence
AI budgets are no longer growing unchecked. Across the industry, engineering teams are being asked to do more with less,…

-
How Evaluation-Driven Development (EDD) Works
Turn every AI agent change into a measured experiment you compare before and after to detect regressions and measure performance.…

-
Opik + Oracle Agent Specification: Build Once, Run Anywhere
Today, we’re announcing Opik’s integration with Oracle’s Open Agent Specification, a partnership that fundamentally changes how AI teams build, test,…

-
AI Evaluation Simplified: Automate Dataset & Metric Eval Workflows with Test Suites
You shipped an agent. It worked in the demo. In production, a user phrased a question differently than you expected…

-
Advanced Claude Code Cost Tracking: How to Save 30% on Token Spend
With tools like Claude Code and Codex now standard in engineering workflows, developers are shipping new products, features, and bug…

-
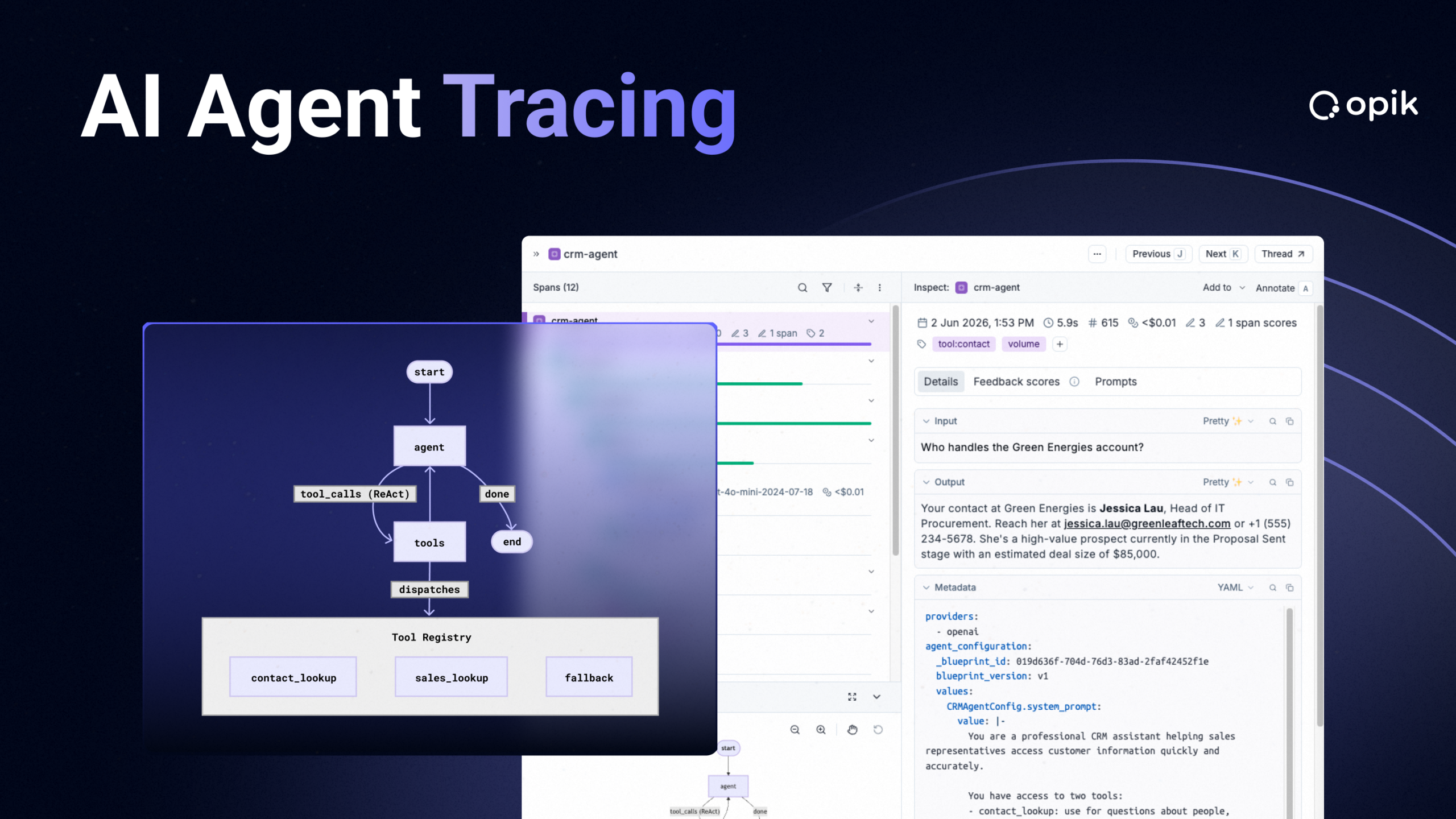
Agent Tracing and Observability: Log & Debug Complex AI Systems
Your customer service agent correctly retrieved order details, checked your return policy, verified the return window and initiated the return…
-
The Best AI Observability Tools for Agentic Systems in 2026
AI applications used to rely on a handful of straightforward LLM calls. Now agents make hundreds of decisions in response…

-
What Held Up at 3 AM: One Engineer’s RAG Case Study
Most AI demos work. Most AI products don’t. This series is a collection of interviews with engineers who shipped AI…
New! Track & optimize Claude Code spend across your engineering team. Learn More→
Comet Blog
-
Understanding Your Claude Code Spend: What’s Actually Driving the Cost
I’ve been spending time looking at how teams are actually using Claude Code, and one thing keeps coming up: most…









Get started today for free.
You don’t need a credit card to sign up, and your Comet account comes with a generous free tier you can actually use—for as long as you like.