Within the GenAI development cycle, Opik does often-overlooked — yet essential — work of logging, testing, comparing, and optimizing steps within complex systems. For a long time, this didn’t include any actual GenAI features inside the product. We were focused on nailing the basics of capturing, organizing, and scoring data so AI developers could use it to make good decisions. But when the need arose to make all that logged data more digestible, with more actionable takeaways, we realized we had an opportunity to integrate an actual LLM-powered feature into our LLM observability product.
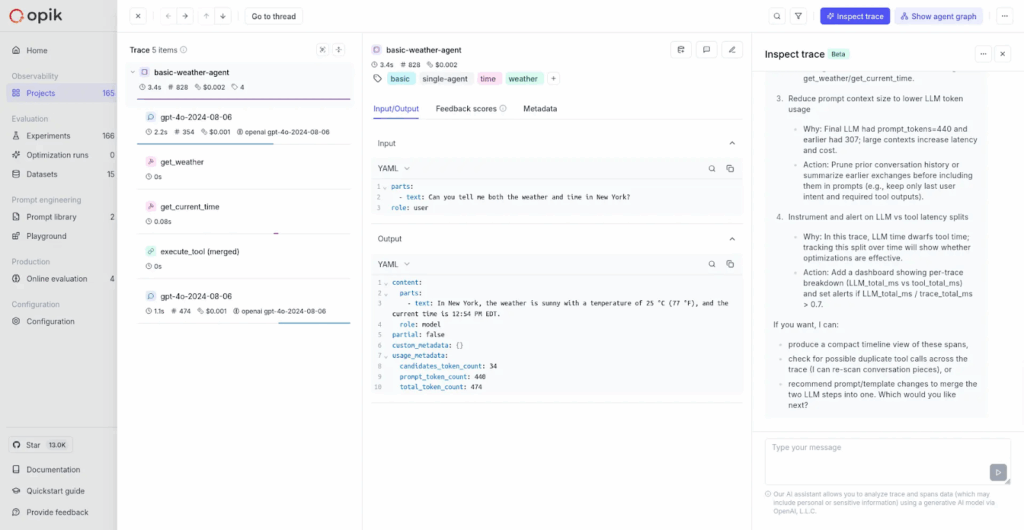
Enter OpikAssist, our AI-powered analysis tool that lets you go beyond inspecting the LLM inputs and outputs in your trace table row by row, helping you pinpoint where and why your application layer or model provider produced unexpected results, and decide what to do about it.
Not only did this project add a useful GenAI feature to the Opik platform, it gave us direct experience that would help us truly relate to our users: understanding what developers go through while building production-grade AI applications, what challenges they face, and where they get stuck.
In building our own user-facing AI agent, we took on the ultimate dogfooding challenge: the chance to use Opik’s LLM observability and evaluation suite to iterate and improve, just as our own users do. The process taught us as much about our platform as it did about the problem we were solving.
The Problem: Too Much Trace Data to Analyze Effectively
Our users kept hitting the same bottleneck: while Opik captured comprehensive trace data, capturing all of the inputs, outputs and metadata passed between an application and an LLM, it was overwhelming to manually analyze all those traces at scale. Teams could see every detail of what happened in their GenAI applications but struggled to understand why specific behaviors occurred, especially when dealing with hundreds or thousands of traces.
The challenge wasn’t missing data. Opik was already capturing detailed traces. The problem was bridging the gap between comprehensive observability and actionable insights, bringing the sheer volume of data into a scope humans could more easily analyze. Users needed help moving from “here’s what happened” to “here’s why it happened and what to do about it.”
So we decided to build an AI-powered solution to help interpret traces and surface recommendations — and we used Opik itself to develop that. While the technical challenge was clear, we also knew the broader context: most AI proofs-of-concept struggle to make it to production. Building a working prototype is one thing, but deploying a reliable, production-grade AI agent is another. Using Opik to develop our own AI feature would test whether our platform could help bridge that critical gap from pilot to production.
From LLM Observability to Action
Building effective GenAI applications requires moving through three distinct stages:
Observability gets you the raw data. You can see every input, output, and intermediate step your system takes, captured and organized in a table. This is foundational for any serious GenAI development.
Interpretability is where most teams get stuck. Raw trace data doesn’t automatically tell you why an agent chose the wrong tool, or why a RAG system’s retrieved context didn’t lead to a good answer. You need to connect the dots between system behavior and outcomes.
Action is the end goal. Once you understand the root cause, you need specific, implementable fixes. Should you adjust the prompt? Modify the retrieval strategy? Change the tool selection logic?
Observability is the easy part. We wanted to build something that could take users all the way through to actionable improvements.
Development Process: 91 Experiments & Counting
Why We Used Our Own Platform
It was both practical and strategic for us to use Opik to develop this new AI-powered trace analysis feature. We needed the AI agent we were building to work in production, not just as a proof-of-concept. We knew that would require systematic trace logging and evaluation throughout the entire development lifecycle. This also gave us the opportunity to validate that our platform could help teams navigate the challenging transition from pilot to production that derails so many AI initiatives.
Implementation Approach
Initial Prototyping with Comprehensive Tracing
We started by building a basic prototype using Google’s Agent Development Kit (ADK), one of the most popular AI agent frameworks among Opik users. Through Opik’s integration with ADK, we and logged every interaction. This gave us visibility into how our AI agent was performing across different trace interpretation scenarios.
Collecting Human Feedback
After getting the prototype functional, we started using it to track the AI agents we use in our day-to-day work, gathering a collection of traces with issues. For more realistic data, we developed our own custom coding assistants with strict requirements, logging their traces in Opik as well. Next, we defined a set of four questions that a user might ask about a trace. These became the default questions, now visible in the UI. We assembled an internal team of annotators to review the traces we had collected for each of the default questions. This feedback was crucial, showing us where the agent succeeded and where it failed to provide useful insights. It was the key to building our golden evaluation dataset.
Creating a Golden Evaluation Dataset
The next step was to build a “golden evaluation dataset,” a high-quality, curated dataset that serves as a benchmark or “ground truth” for evaluating an AI system. We used the traces we had collected with human feedback, saving them as a dataset in Opik . This became our ground truth for measuring improvements. The dataset included examples of good and poor trace interpretations, annotated with what users actually found helpful.
Scaling Evaluation with LLM-as-a-Judge
Using the evaluation dataset, we implemented automated scoring using LLM-as-judge metrics alongside our human annotations. This allowed us to test different approaches systematically rather than relying on manual spot-checking.
Structured Improvement Loop
With comprehensive tracing and systematic evaluation in place, Opik became central to our iteration process. We could track detailed information about each development attempt, compare performance across prompt versions, and identify what changes actually improved the agent versus what just felt better subjectively. Overall we ran 91 experiments before we were ready to deploy our agent. The biggest improvement came from updating our base model to GPT-5.
Key Learnings
Opik Platform Validation
What Worked: Tracing was fundamental throughout the development process. It provided the visibility needed for debugging and optimization. After collecting human feedback and creating datasets, Opik’s tracing capabilities allowed us to iterate quickly on the agent’s prompts, tools, and architecture while tracking what changes improved performance.
What We Could Improve: While Opik provides all the building blocks for GenAI development, it’s still up to developers to structure their own iteration processes. We’re thinking about ways we can structure Opik’s featureset as a reusable template across the dev cycle, providing clearer guidance on how to use these building blocks effectively.
Bridging Pilot to Production
What Made the Difference: The systematic approach enabled by comprehensive tracing and evaluation was crucial for moving beyond a working prototype to a production-ready feature. Visibility into every step of our agent’s decision-making process, combined with structured evaluation datasets, gave us the confidence to deploy.
Production Readiness Indicators: We could track not just whether our agent worked, but how consistently it worked across different scenarios, how it handled edge cases, and how its performance changed as we iterated. This level of systematic evaluation is what separates successful production deployments from abandoned pilots.
GenAI Development Insights
The development process revealed important patterns:
Prototyping vs Production: Getting a first version running is straightforward. Making it reliable, scalable, and maintainable is significantly harder.
Evaluation Challenges: Evaluating systems that return unstructured text responses is challenging. Human-annotated evaluation datasets became fundamental for measuring improvement.
Overwhelming Options: The number of options in GenAI development can be overwhelming. Choosing initial validation datasets and evaluation metrics requires clear frameworks.
Product Development Impact
These insights directly shaped our product direction. We’re focusing on making the iteration loop more efficient by improving human feedback collection, both during initial development and in production, and delivering more guided workflows for continuous improvement.
What We Built: OpikAssist Capabilities
Core Functionality
Intelligent Trace Interpretation: Ask questions about individual traces and get AI-powered insights. Instead of manually parsing complex trace hierarchies, users can instruct the agent to “Diagnose the reason for this trace failure” or “Analyze this trace and identify any anomalies”.
GPT-5 Analysis: The system uses GPT-5 for analysis, integrated directly in the Opik UI.
Actionable Recommendations: Rather than just explaining behavior, the system provides specific improvement suggestions.
The result is more than just a useful feature. It’s proof that with the right approach to development and evaluation, AI pilots can successfully make the leap to production.
Applications
- Identify anomalies and unexpected behavior within a trace
- Root-cause analysis for failed agent interactions
- Performance bottleneck identification in multi-step workflows
- Debugging complex agent decision chains
- Summarize the contents of a trace
Conclusion: Process & Evaluation for Production-Ready AI Features
Building this feature proved something important about AI development: the gap between “it works in demo” and “it works in production” comes down to having the right development process. Most AI pilots fail not because the underlying technology isn’t good enough, but because teams lack the systematic approach needed to debug, iterate, and deploy with confidence.
Using Opik to build our own AI agent validated that comprehensive tracing and structured evaluation can bridge that gap. We went from prototype to production-ready feature because we could see exactly what was happening at every step, measure improvements objectively, and iterate based on data rather than gut feelings.
The trace inspection feature represents more than just a new capability in Opik. It’s proof that with the right tools and approach, AI projects can successfully make the leap from promising pilot to reliable production system.
Try it yourself: AI-powered trace analysis is available now for Opik cloud users. Open any trace in your project and ask questions like “Why did this fail?” or “What caused the performance issue?” You’ll get actionable insights right where you’re already debugging. Try Opik free today.
