What if your AI system was more than a chatbot? What if it could book flights, debug code, or process customer refunds across multiple systems? That, multiplied across thousands of industries and use cases, is the promise of agentic AI.

The AI industry is undergoing its third major evolution. First came predictive AI, which could forecast outcomes from massive datasets. Then generative AI arrived, creating novel text, images, and code. Now we’re entering the age of agentic AI — systems that don’t just predict or generate, but autonomously act to achieve goals. The shift is from content creation to task completion, from passive response to active execution.
With all this tailwind, “agentic AI” has also become one of the most overused buzzwords in tech. Companies are rebranding simple chatbots as “agents.” Clients demand “agentic features” without knowing what that actually means. And developers are rightfully skeptical, wondering if this is just marketing hype wrapped around chained LLM prompts.
This guide cuts through that noise. You’ll learn what genuinely makes a system agentic, how to architect these systems properly, and, crucially, how to debug and deploy them when real production challenges hit. Because the gap between an impressive demo and a reliable production agent is vast, and that’s where most teams struggle.
The Great Debate: What Actually Constitutes an AI Agent
The technical community can’t agree on what an “AI agent” actually is. This isn’t just semantic nitpicking; there’s a tension in software engineering between the desire for predictable, deterministic systems and the powerful but unreliable non-determinism of LLM-driven intelligence. Understanding this debate is essential before you build anything, because your architectural choices depend on where you land on this spectrum.
The Spectrum of Agency
A growing consensus suggests that “agentic” is a spectrum, not a binary. At one end, you have a simple application that makes a single, hardcoded tool call based on an LLM’s output. At the other end sits a sophisticated multi-agent system that autonomously decomposes complex goals, coordinates among specialized sub-agents, and operates over extended periods without human oversight. Andrew Ng and other prominent AI researchers advocate for this spectrum view, which helps reconcile the wildly different systems all claiming to be “agents.”
The question isn’t “is this an agent or not?” but rather “how agentic is this system?” A basic customer service chatbot that looks up order status is minimally agentic. A system that autonomously monitors supply chains, predicts stockouts, and initiates procurement workflows across multiple vendor APIs is highly agentic.
Workflows vs. Agents: The Core Distinction
Anthropic researchers have articulated one of the most useful distinctions in this space: workflows versus agents. In a workflow, LLMs and tools are orchestrated through predefined, hardcoded paths. While an LLM might help at various steps, the overall control flow is deterministic and locked down by your application code. You can predict exactly what will happen next.
In an agent, the LLM dynamically directs its own processes and tool usage. The LLM itself decides the sequence of operations, maintaining control over how a task gets accomplished. The control flow is non-deterministic and emerges from the model’s real-time reasoning. You can’t always predict what it’ll do next.
This distinction matters because it highlights the fundamental trade-off you’re making. Traditional software development prioritizes deterministic, testable, and predictable systems. The workflow approach aligns with this, using LLMs as powerful but contained components within a predictable structure. The agent approach cedes control to the non-deterministic LLM, unlocking greater flexibility and adaptability at the cost of predictability and ease of debugging.
LangChain CEO Harrison Chase popularized a simple heuristic: if the LLM can change your application’s control flow, it’s an agent. If the flow is fixed by your code, it’s not.
What Developers Actually Look For
Synthesizing discussions from developer communities reveals several criteria that practitioners consistently cite as essential for a “true” agent. Goal-orientation sits at the foundation — an agent operates with a persistent goal or intent, not just responding to isolated prompts. It’s actively working to achieve a defined objective over multiple steps.
Dynamic control flow matters because the LLM must determine the sequence of actions and tool calls required to achieve that goal. Environmental interaction creates a feedback loop where the agent executes actions that affect its environment, perceives the results, and uses that new information to inform its next decision. This continuous act-sense-react loop defines agentic behavior in practice.
Autonomy means the system can plan its own sub-tasks, adapt its approach based on feedback, and run in a loop until it achieves its goal without requiring constant, step-by-step human guidance.
Acknowledging the Cynicism
Developer forums are full of skepticism about “agentic AI” being used as marketing for what are really just simple chained prompts or basic workflows. Many developers report clients demanding “agentic” features without technical definitions, leading to rebranding of existing systems to fit the trend. This industry cynicism is valid and worth acknowledging upfront.
The truth is somewhere in the middle. Not every system marketed as an agent meets the technical bar, but genuinely autonomous, goal-oriented systems are being built and deployed. If you understand the principles well enough, you’ll be able to build the real thing and know where your system falls on that spectrum.
Anatomy of an AI Agent: Core Components that Make Systems Work
Regardless of where your system falls on the agentic spectrum, you’ll construct it from a set of fundamental building blocks. Understanding these components and how they interact is essential for designing, building, and debugging any agentic system. Let’s examine each piece.
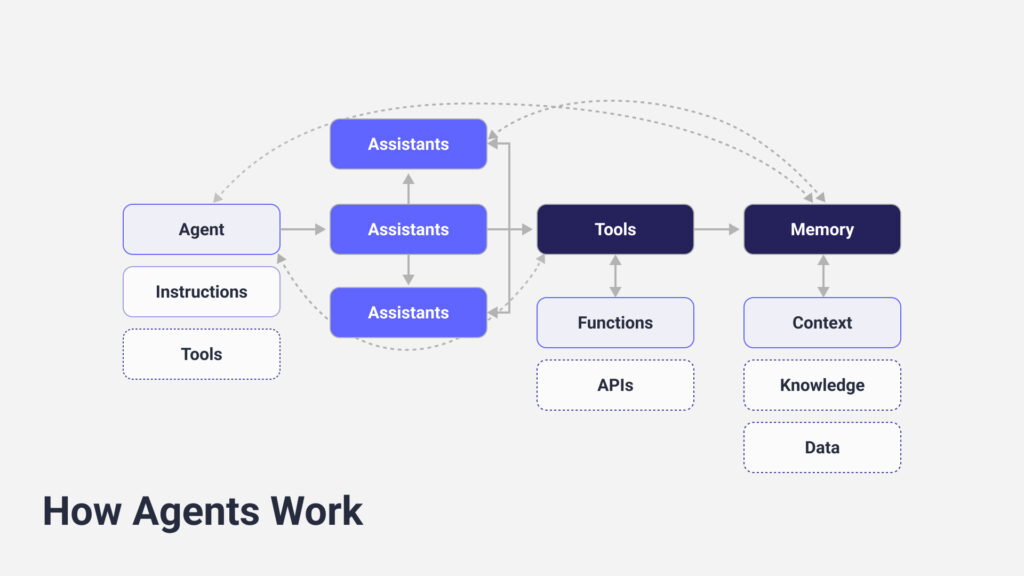
The Reasoning Engine: Your AI Agent’s Brain
At the heart of every modern AI agent sits an LLM functioning as its reasoning engine. This component handles the highest-level cognitive tasks: interpreting your user’s goal even when expressed in ambiguous natural language, decomposing that goal into a logical sequence of executable sub-tasks, determining which external tools are needed at each step, and synthesizing information from various sources to formulate conclusions and responses.
To facilitate this reasoning process, you’ll employ specific prompting techniques. Chain-of-Thought (CoT) prompting encourages the model to “think out loud,” generating a step-by-step textual trace of its reasoning process. This improves performance and provides some interpretability into why the model made specific decisions. More advanced frameworks like ReAct (Reasoning and Acting) explicitly interleave reasoning steps with action steps, creating a tight loop between thought and environmental interaction.
The key insight here is that an LLM isn’t an agent by itself. It’s the cognitive engine that makes agent behavior possible. Other components provide memory and the ability to act, but the LLM drives the system’s intelligent decision-making.
Perception and Action: Tool Calling as Hands and Senses
Your agent perceives and acts upon its environment through tool use, technically implemented via function calling. This capability bridges the gap between the LLM’s abstract reasoning and the concrete world of APIs, databases, and external systems. Without tool calling, your LLM can only talk about what it would do — it can’t actually do anything other than generate text, images, etc.
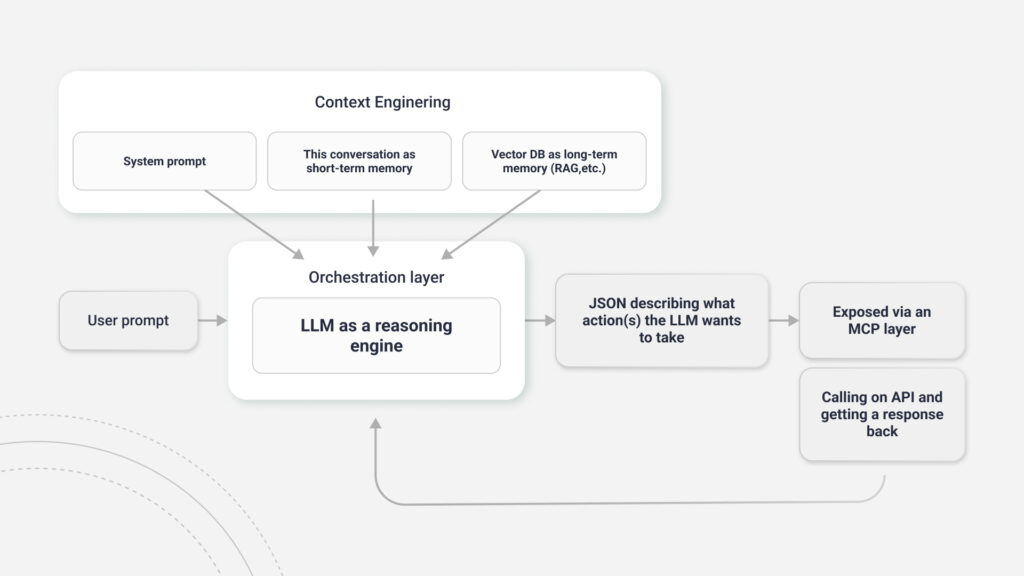
The process unfolds in a structured, multi-step interaction. First, you provide the LLM with a manifest of available tools during initialization. Each tool gets defined with a name, a clear description of its purpose, and a strict schema (typically a JSON Schema) detailing its required parameters. When processing a user’s request, the LLM uses these tool descriptions to decide if an external action is necessary.
In an agentic system, the LLM doesn’t execute the action itself. Instead, it generates a structured JSON object specifying which function to call and what arguments to pass. Your application’s orchestration layer receives this JSON, parses it, and executes the corresponding function in your native code—maybe making an API call to a weather service or querying a database.
The result of that function call gets returned to the LLM as an “observation.” This observation informs the LLM’s next reasoning step, allowing it to either complete the task or plan its next action. This cycle of tool selection, execution, and observation feedback is what enables agents to interact with the real world.
Just like a traditional deterministic program would have some logic to determine if a response received fulfills a user’s request, an agentic system uses LLM-as-a-judge to determine whether the response(s) it has received are adequate.
Memory: Maintaining Context Across Time
For your agent to perform any task of meaningful complexity, it needs memory. Memory allows the agent to maintain context over long interactions, learn from past experiences, and avoid redundant actions. Without it, every conversation starts from zero.
You’ll typically implement two types of memory. Short-term memory is the volatile, working memory primarily consisting of conversation history within the LLM’s context window. It holds the immediate context of the current task but disappears once the session ends. This is what allows your agent to remember what you said three messages ago in the current conversation.
Long-term memory provides persistence across sessions, allowing your agent to recall past interactions and accumulated knowledge. This is commonly implemented using a vector database, where past experiences and information are stored as embeddings. When faced with a new task, your agent can perform a semantic search on this database to retrieve relevant memories — a pattern often integrated into Retrieval-Augmented Generation (RAG) architectures.
The distinction matters because short-term memory is cheap but temporary, while long-term memory requires infrastructure but enables genuine learning and personalization over time.
Planning and Orchestration: The Strategy Layer
The orchestration layer — sometimes called the agent core or action layer — is the engine that drives your agent’s behavior. It manages the iterative loop that defines agentic operation: the Thought-Action-Observation cycle. In the Thought phase, your LLM analyzes the current state and goal, then decides on the next action. During Action, the orchestration layer executes that chosen action by calling a tool. The Observation phase passes the result back to the LLM.
This loop continues until your agent determines the goal has been achieved. The orchestrator mediates all communication between the reasoning engine, memory modules, and tool execution layer. This is where the non-determinism lives—your orchestrator decides when to loop, when to stop, and how to handle errors or unexpected results.
Guiding Behavior: The System Prompt as Operating System
Your agent’s foundational behavior gets established through a system prompt — a predefined, high-level instruction given to the LLM before any user interaction occurs. Think of the system prompt as the “operating system” for your agent, providing the fundamental rules, constraints, and environment within which all subsequent user requests get processed.
A well-architected system prompt defines your agent’s core identity and operational parameters: its persona, role, tone, ethical guardrails, and required output formats. The system prompt is a core architectural concern. It’s one of the most powerful levers for ensuring your agent behaves reliably, consistently, and safely, significantly reducing the likelihood of undesirable outputs like bias, hallucination detection, or inefficient behavior.
Crafting a robust system prompt requires iterative refinement. You’ll need to test how different phrasings affect behavior, establish clear boundaries around what the agent should and shouldn’t do, and provide explicit examples for edge cases. This work pays dividends in production stability.
Architectural Blueprints: From Simple Patterns to Multi-Agent Systems
Designing an agentic system involves selecting architectural patterns that align with your task’s complexity. The design choices range from simple, single-agent structures to complex, multi-agent systems, each with distinct trade-offs in capability, cost, and maintainability. This evolution in architectural thinking mirrors the broader history of software engineering — specifically the shift from monolithic applications to distributed microservices.
A single “do-everything” agent, like a monolith, becomes difficult to debug, expensive to operate (requiring a powerful LLM for all tasks), and challenging to maintain. Multi-agent systems composed of smaller, specialized agents offer benefits analogous to microservices: improved modularity, scalability, and fault isolation.
Single-Agent Patterns: Building Blocks
You’ll start with single-agent patterns for tasks of low to moderate complexity. The simple reflex agent operates on a direct input-reasoning-output flow with no memory of past events, making it purely reactive. This pattern works for stateless, simple automation tasks where context doesn’t matter.
The memory-augmented agent enhances the reflex pattern by adding a memory component. Before reasoning, your agent retrieves relevant context from a knowledge base or past interactions. This becomes essential for personalized and stateful applications where knowing what happened yesterday matters today.
The tool-using agent is the most prevalent pattern for practical applications. Your agent gets equipped with a library of external tools it can call via function calling to gather information or perform actions beyond the LLM’s intrinsic capabilities. Most production agents you’ll build follow this pattern.
The reflection agent introduces a loop of self-critique and refinement. After generating an initial output or plan, your agent evaluates its own work against certain criteria and iteratively improves it before delivering the final result. This pattern proves useful for tasks requiring high-quality output, like code generation or detailed report writing, where getting it right matters more than getting it fast.
When One Agent Isn’t Enough: Multi-Agent Systems
For complex, multi-faceted problems, a single agent becomes a bottleneck. Decomposing the problem and assigning sub-tasks to a team of specialized agents offers a more robust, scalable, and maintainable solution. The benefits mirror microservices architecture: task specialization allows each agent to be an expert in a narrow domain, improving accuracy and simplifying design. Cost efficiency means simpler tasks can run on smaller, cheaper models while complex reasoning gets reserved for powerful, expensive models. Scalability improves because agents can work in parallel, reducing overall latency. Maintainability increases since you can update, test, and deploy individual agents without affecting the entire system.
The coordination of these agents gets managed through orchestration patterns. Sequential orchestration arranges agents in a linear pipeline where the output of one becomes the input for the next. This pattern is deterministic and well-suited for structured, multi-stage workflows like document processing where a document gets summarized, translated, then formatted in sequence.
Parallel orchestration (fan-out/fan-in) has an initiator agent distribute a task to multiple agents that work on it concurrently from different perspectives. Their individual outputs get collected and synthesized by a collector agent. This proves useful for brainstorming, ensemble reasoning, or tasks where diverse insights add value.
Hierarchical orchestration is one of the most powerful and common patterns. A central “manager” or “coordinator” agent receives a high-level goal, decomposes it into sub-tasks, and delegates them to specialized “worker” agents. The manager oversees the process, synthesizes results, and ensures the overall goal gets met. This pattern closely resembles how human organizations structure complex projects.
Framework Comparison: CrewAI, LangGraph, and AutoGen
Several open-source frameworks have emerged to simplify implementing these complex architectural patterns. Each has a different core philosophy and suits different types of problems.
CrewAI excels at hierarchical, role-based agent teams. It’s designed around the metaphor of a crew with defined roles working toward a shared goal. You’ll find CrewAI intuitive for business process automation where you can clearly map agents to job functions. The framework provides strong opinions about how agents should collaborate, which accelerates development but reduces flexibility.
LangGraph takes a graph-based approach, giving you maximum control over agent workflows. It’s built on the concept of state machines where nodes represent agent actions and edges represent transitions between states. If you need fine-grained control over execution flow, conditional branching, and complex coordination logic, LangGraph provides that power. The trade-off is a steeper learning curve and more code to write.
AutoGen focuses on conversational collaboration between agents. It’s optimized for scenarios where agents need to engage in multi-turn dialogues to solve problems, making it particularly strong for research, analysis, and tasks requiring iterative refinement. AutoGen’s group chat feature allows multiple agents to participate in discussions, making decisions through conversation rather than rigid hierarchies.
Choose your framework based on your use case. For structured business processes with clear roles, start with CrewAI. For complex workflows requiring precise control, use LangGraph. For collaborative problem-solving and analysis, try AutoGen.
Real-World AI Agent Use Cases
The true potential of agentic AI becomes clear when examining real-world applications. The most transformative use cases often automate complex, cross-functional processes, acting as intelligent “glue” between disparate organizational systems. In most enterprises, data and functionality fragment across various applications — CRM, ERP, project management, communication tools.
Human employees spend significant time manually bridging these gaps. AI agents can automate this integration work at scale.
AI Agent Use Case: Automated Travel Planning
A sophisticated travel planning agent demonstrates hierarchical multi-agent architecture in action. Your user provides a natural language prompt: “Plan a 7-day family vacation to Costa Rica in July for two adults and two children. Our budget is $5,000, and we’re interested in wildlife and adventure activities.”
A coordinator agent receives this request and decomposes it into key sub-tasks: flight booking, accommodation search, activity planning, and budget management. It dispatches a flight search agent equipped with tools to query airline APIs like Amadeus or aggregators. This agent searches for flights matching the dates and passenger count, filtering results by price and layovers.
In parallel, following the parallel orchestration pattern, a hotel search agent connects to hotel booking APIs to find family-friendly accommodations within the specified budget and preferred regions. An activity research agent uses web search tools to identify top-rated wildlife tours, zip-lining excursions, and national parks, checking for age appropriateness and current operating hours.
The coordinator gathers optimized options from each worker agent, then uses its reasoning engine to synthesize these components into a coherent, day-by-day itinerary. It ensures the total estimated cost remains within the $5,000 budget before presenting the proposed plan to your user for review and approval.
This architecture demonstrates several key principles: specialized agents handle domain-specific tasks, parallel execution reduces latency, and a coordinator maintains coherence across the entire workflow. The system adapts to constraints dynamically rather than following a rigid script.
Agent Use Case: Intelligent Software Development Assistant
Integrating an AI agent into the software development lifecycle can dramatically reduce context switching and automate administrative overhead. Consider an agent tasked with streamlining the process from bug report to deployment, connecting project management in JIRA with version control in GitHub.
When a new bug report gets filed in JIRA, your sequential agent triggers automatically. It uses the JIRA API to read the ticket’s description, priority, and comments to understand the issue’s context. The agent identifies the relevant code repository and files mentioned in the ticket, then uses a GitHub tool to check out the codebase for analysis.
Your agent leverages its reasoning model to generate a potential code fix. It automatically creates a new branch in GitHub, commits the fix, and opens a pull request. The PR description gets populated with a summary of the bug and proposed solution, linking back to the original JIRA ticket. A separate, specialized reviewer agent can perform preliminary code review, checking for adherence to coding standards, common anti-patterns, and appropriate test coverage.
Once the PR gets approved by a human developer and merged, a webhook triggers your agent to perform final cleanup tasks. It automatically updates the JIRA ticket’s status to “Resolved” and can trigger a CI/CD pipeline to deploy the fix to staging. This workflow eliminates hours of manual ticket management and context switching that would otherwise fall on your development team.
Agent Use Case: Autonomous Enterprise Operations
Beyond specific verticals, agents are being deployed to automate core business functions. An advanced customer service agent can handle complex requests requiring action across multiple systems. For “I’d like to return this item,” your agent orchestrates a full workflow: looking up the order in your e-commerce database, processing the refund through your payment processor’s API, updating the customer’s profile in your CRM with the return information, and sending a confirmation email.
In supply chain management, a proactive agent can monitor inventory levels in your ERP system. When stock for a particular item falls below a predefined threshold, it autonomously initiates procurement. This includes querying multiple supplier APIs to compare pricing and availability, generating and sending a purchase order to the optimal supplier, and creating a tracking entry in your logistics system to monitor the shipment until arrival.
These use cases share a common thread: they eliminate repetitive cross-system integration work that previously required human coordination. The value isn’t just efficiency — it’s consistency, accuracy, and the ability to operate 24/7 without fatigue.
The Production Gauntlet: Why AI Agent Demos Succeed and Deployments Fail
While demonstrations of AI agents are often impressive, deploying them into production environments at scale reveals significant challenges. The gap between a compelling prototype and a reliable, secure, and cost-effective production system is vast. The core of these challenges stems from the agent’s autonomous and non-deterministic nature, which can deviate from your original intent in unpredictable ways. You can think of this as “agentic drift” — the inevitable divergence between what you designed the agent to do and what it actually does in production.
The Reliability and Determinism Problem
The non-deterministic reasoning of LLMs is a double-edged sword. While it provides flexibility, it introduces unpredictability. The same input can lead your agent down different reasoning paths, resulting in inconsistent outcomes. This is unacceptable for mission-critical business processes where users expect the same input to produce the same result every time.
Furthermore, an LLM’s tendency to hallucinate—generating factually incorrect information—can be catastrophic in an agentic workflow. A single hallucinated value in an early step cascades through the entire process, corrupting subsequent decisions and leading to incorrect actions. Imagine your procurement agent hallucinating a supplier’s pricing or your customer service agent hallucinating a return policy.
You can enhance reliability through several practices. Embrace modularity by decomposing complex systems into a collection of small, specialized agents, each with a single, well-defined responsibility. This design pattern isolates failures, making your system more resilient and easier to debug. Design for failure by implementing robust error handling and fail-safe mechanisms. And for high-stakes decisions or irreversible actions, escalate to a human-in-the-loop for confirmation.
Critically, offload precision tasks to deterministic tools. Don’t rely on the LLM for mathematical calculations, date comparisons, or structured data retrieval. Instead, provide your agent with tools like a calculator API, a database query function, or a date manipulation library to perform these tasks reliably. This is where the tool-using pattern proves essential — not just for extending capabilities, but for ensuring accuracy where it matters most.
The “Black Box” Dilemma: Debugging Agent Failures
Debugging an AI agent is fundamentally different from debugging traditional software. The failure is often not a bug in your code but a flaw in the LLM’s emergent reasoning chain. Without deep visibility into your agent’s internal processes, including a full trace of the sequence of prompts, chosen tool calls, data returned by those tools, and intermediate reasoning steps, it’s difficult to diagnose why your agent failed.
Traditional logging and error tracking fall short because the problem isn’t usually an exception being thrown. The problem is that your agent decided to call the wrong tool, or called the right tool with the wrong parameters, or misinterpreted the tool’s response. These are reasoning failures, not code failures.
A production-grade agent requires an LLM observability platform that logs and traces every step of the Thought-Action-Observation loop. You need visibility into what your agent was “thinking” when it made each decision, what external data it received, and how it interpreted that data. This data becomes critical for debugging failures and understanding agent behavior patterns over time.
The complexity of agentic traces has led to the emergence of specialized platforms designed to visualize and inspect agent execution paths. These tools provide timeline views of agent reasoning, highlight decision points, and allow you to replay specific traces to understand what went wrong. Without this level of observability, you’re flying blind.
Performance and Cost
The iterative nature of agentic workflows leads to performance and cost issues. Each call to an LLM introduces latency, from hundreds of milliseconds to several seconds, depending on the model and prompt complexity. A complex plan requiring multiple reasoning steps can result in a slow user experience where your agent takes 30 seconds or more to complete a task.
Each LLM call also incurs a cost based on token usage. An inefficient agent, especially one that gets stuck in a reasoning loop, can quickly accumulate substantial operational expenses. If your agent makes 10 LLM calls to complete a task, and each call costs $0.05, and you’re processing 1,000 tasks per day, you’re spending $500 daily on a single agent. Scale that to multiple agents and higher call volumes, and costs become a serious concern.
You can manage these issues by monitoring key LLM evaluation metrics continuously. Track latency (end-to-end task completion time), cost (token consumption and API call volume), task success rate, and output accuracy. These metrics help you identify inefficient patterns before they become expensive problems.
Employ a tiered model strategy: use smaller, faster, and cheaper models for simple, routine tasks like intent classification or data extraction, while reserving large, powerful models for complex reasoning and planning steps. A GPT-4 call might cost 20 times more than a GPT-3.5 call — use the expensive model only when you need its capabilities.
Implement caching for the results of frequent, deterministic tool calls. If your agent queries the same product catalog 100 times per day, cache those results to reduce redundant API usage and improve latency. This is especially effective for data that doesn’t change frequently.
Security: A New Attack Surface
By design, AI agents interact with external systems and operate with autonomy, creating a new and expanded attack surface. They’re susceptible to both traditional software vulnerabilities and a new class of AI-specific threats that you need to understand.
Prompt injection is a critical vulnerability where an attacker manipulates your agent’s input to trick it into overriding its original instructions. A successful injection can lead your agent to execute malicious commands, bypass safety guardrails, or leak sensitive data it has access to. For example, an attacker might embed hidden instructions in a customer support ticket that cause your agent to disclose other customers’ information.
Tool misuse and excessive permissions create risk when your agent has access to powerful tools — an API that can delete user data, process financial transactions, or modify production databases. If an attacker gains control of your agent through prompt injection or other means, they inherit all of your agent’s permissions. You must follow the principle of least privilege, granting your agent only the bare minimum permissions required to perform its function.
Data poisoning targets the external knowledge sources your agent relies on, particularly RAG databases. By injecting malicious or false information into these sources, attackers can subtly manipulate your agent’s behavior and cause it to make harmful decisions. If your agent retrieves context from a compromised knowledge base, that poisoned data influences every decision.
Your defense requires a defense-in-depth strategy. Apply traditional security fundamentals: strict authentication, authorization, and auditability for every agent. Augment these with AI-specific defenses like guard models — a secondary LLM that vets your primary agent’s proposed actions against a security policy before execution. Conduct adversarial training to identify and patch vulnerabilities before deployment. Test your agent with malicious inputs to understand how it behaves under attack.
Building AI Agents You Can Actually Trust
The journey from prototype to production-ready agent confronts you with challenges that most LLM evaluation frameworks and tutorials gloss over. You’re not just building a system that can complete tasks — you’re building one that completes tasks reliably, debuggably, cost-effectively, and securely at scale. The autonomous nature of agents builds on traditional software engineering practices, but requires new approaches to LLM evaluation, observability and operational management.
This is the problem that drove the development of Opik Agent Optimizer SDK. It provides granular LLM tracing and visualization tools that illuminate your agent’s entire reasoning process, transforming chain-of-thought prompting, tool calls, and observations into a transparent, debuggable workflow. You can pinpoint exactly where in the reasoning chain things went wrong.
The SDK integrates continuous evaluation capabilities that let you track production metrics — cost, latency, success rate, and accuracy — in real time. You can establish performance baselines and configure alerts to detect agentic drift before it impacts users or incurs runaway costs. This shifts you from reactive debugging to proactive LLM monitoring, catching problems early when they’re cheaper to fix.
Opik helps you engineer for reliability and efficiency by providing tools to enforce constraints, implement fail-safes, and optimize agent performance. You can build more robust, predictable, and cost-effective systems that meet the rigorous demands of enterprise scale. The platform bridges the gap between the flexible, creative power of agentic AI and the operational rigor that production systems require.
The future of software is increasingly autonomous. As agentic systems become more integrated into digital infrastructure, your ability to build, manage, and trust them becomes a critical differentiator. The path to realizing this technology’s full potential lies in mastering its operational complexities, and Opik provides the essential toolkit for that journey. Get started with Opik to build agents that work reliably in production, not just in demos.
