
Editor’s Note: This blog post was co-written alongside William Arias, Technical Marketing Manager at GitLab, and has been syndicated with permission. Check out the original version of this post on GitLab’s blog.
Introduction
Building ML-powered applications comes with numerous challenges. When we talk about these challenges, there is a tendency to overly focus on problems related to the quality of a model’s predictions — things like data drift, changes in model architectures, or inference latency.
While these are all problems worthy of deep consideration, an often overlooked challenge in ML development is the process of integrating a model into an existing software application.
If you’re tasked with adding an ML feature to a product, you will almost certainly run into an existing codebase that must play nicely with your model. This is, to put it mildly, not an easy task.
ML is a highly iterative discipline. Teams often make many changes to their codebase and pipelines in the process of developing a model. Coupling an ML codebase to an application’s dependencies, unit tests, and CI/CD pipelines will significantly reduce the velocity with which ML teams can deliver on a solution, since each change would require running these downstream dependencies before a merge can be approved.
In this post, we’re going to demonstrate how you can use Comet with GitLab’s DevOps platform to streamline the workflow for your ML and Software Engineering teams, allowing them to collaborate without getting in each other’s way.
TL;DR — Check out this technical walkthrough for an inside look at how you can add reliable CI/CD pipelines to your ML workflows with GitLab + Comet.
The Challenge for ML Teams working with Application Teams
Let’s say your team is working on improving a feature engineering pipeline. You will likely have to test many combinations of features with some baseline model for the task, to see which combinations make an impact on model performance.
It is hard to know beforehand which features might be significant, so having to run multiple experiments is inevitable. If your ML code is a part of your application codebase, this would mean having to run your application’s CI/CD pipeline for every feature combination you might be trying.
This will certainly frustrate your Engineering and DevOps teams, since you would be unnecessarily tying up system resources, given that Software Engineering teams do not need to run their pipelines with the same frequency as ML teams do.
The other issue is that despite having to run numerous experiments, only a single set of outputs from these experiments will make it to your production application. Therefore, the rest of the assets produced through these experiments are not relevant to your application code.
Keeping these two codebases separated will make life a lot easier for everyone — but it also introduces the problem of syncing the latest model between two codebases.
Using GitLab DevOps Platform and Comet for your Model Development Process
With the GitLab DevOps platform and Comet, we can keep the workflows between ML and Engineering teams separated, while enabling cross-team collaboration by preserving the visibility and audit-ability of the entire model development process across teams.
We will use two separate projects to demonstrate this process. One project will contain our application code for a handwritten digit recognizer, while the other will contain all the code relevant to training and evaluating our model.
We will adopt a process where discussions, code reviews, and model performance metrics get automatically published and tracked within the GitLab DevOps platform, increasing the velocity and opportunity for collaboration between data scientists and software engineers for machine learning workflows.
Project Setup
Our application consists of two projects. The comet-model-trainer and ml-ui.
The comet-model-trainer repository contains scripts to train and evaluate a model on the MNIST dataset. We have set up the GitLab DevOps Platform in a way that runs the training and evaluation Pipeline whenever a new Merge Request is opened with the necessary changes.
The ml-ui repository contains the necessary code to build the frontend of our ML application.
Since the code is integrated with Comet, your ML team can easily track the source code, hyperparameters, metrics, and other details related to the development of the model.
Once the training and evaluation steps are completed, we can use Comet to fetch summary metrics from the Project as well as metrics from the Candidate model and display them within the Merge Request — this will allow the ML team to easily review the changes to the model.
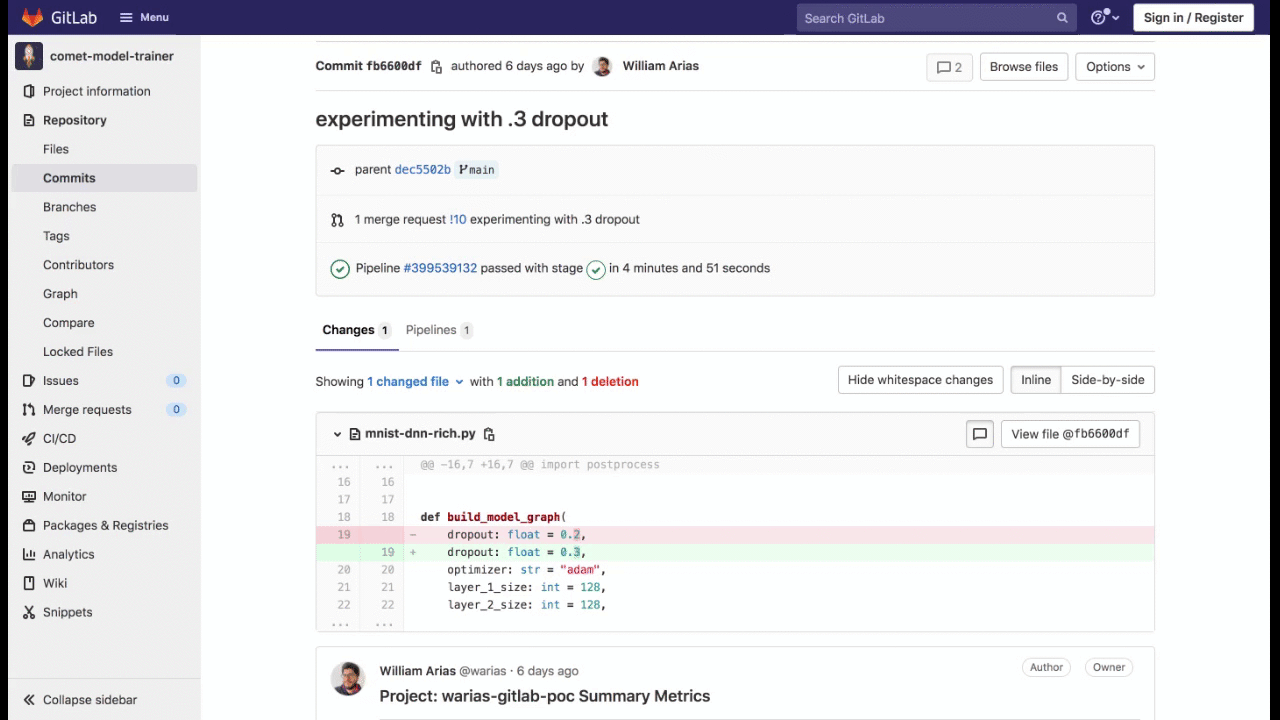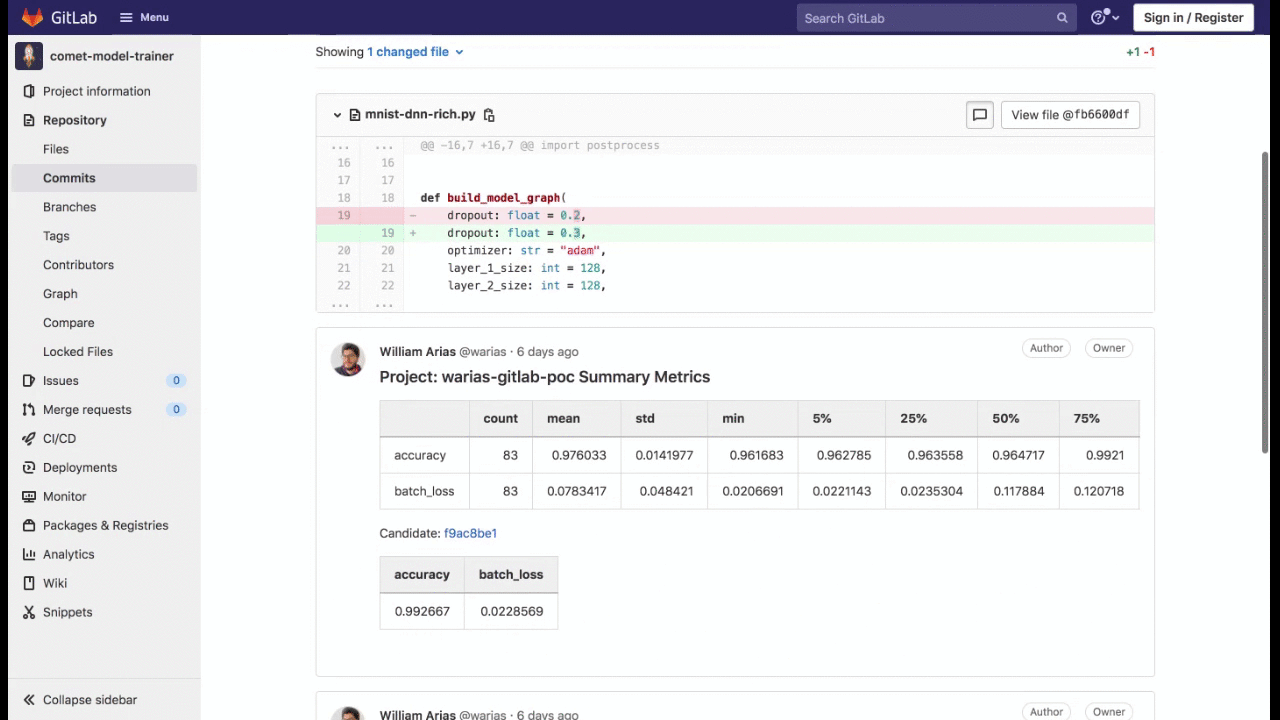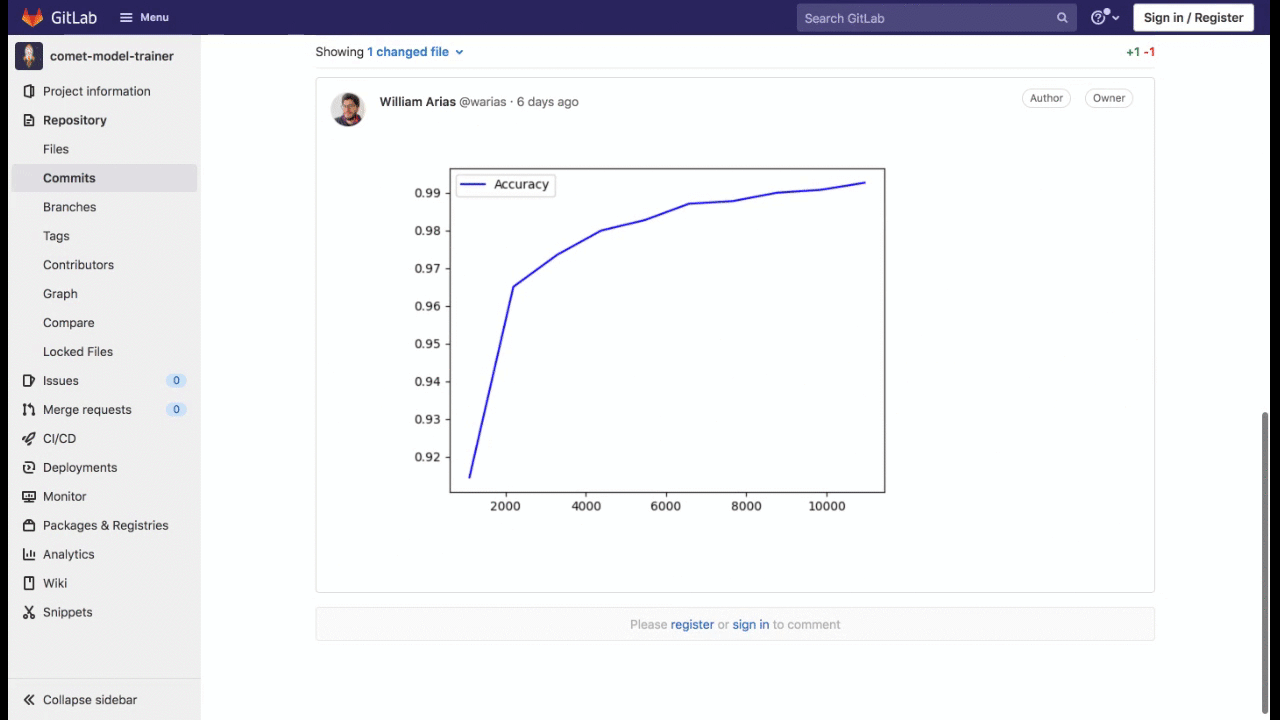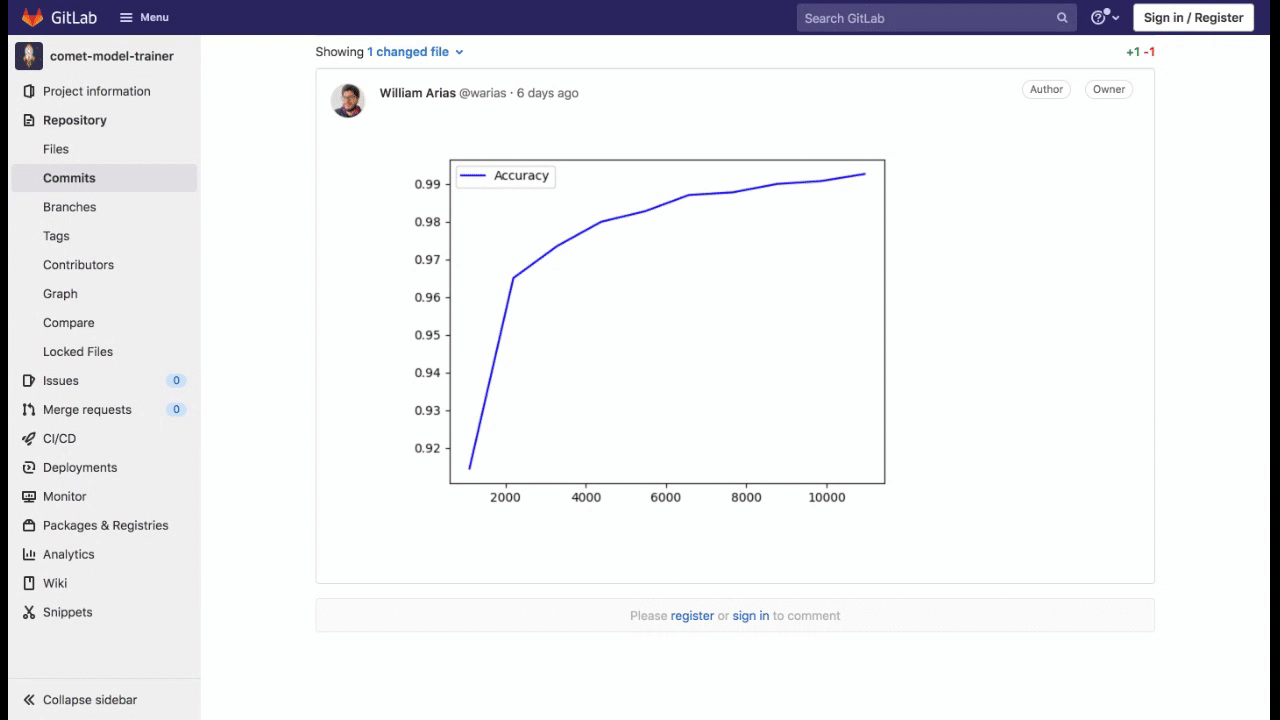
In our case, the average accuracy of the models in the Project is 97%. Our Candidate model achieved an accuracy of 99%, so it looks like it is a good fit to promote to production. The metrics displayed here are completely configurable and can be changed as necessary.
When the Merge Request is approved, the deployment pipeline is triggered and the model is pushed to Comet’s Model Registry. The Model Registry versions each model and links it back to the Comet Experiment that produced it.
Once the model is pushed to the Model Registry, it is available to the application code. When the Application Team wishes to deploy this new version of the model to their app, they simply have to trigger their specific deployment pipeline.
Running the Pipeline
We will run the process outlined below every time a team member creates a merge request to change code in the build-neural-network script.
Now, let’s take a look at the yaml config used to define our CI/CD pipelines depicted in the previous diagram:
image: python:3.8
include:
- template: 'Workflows/Branch-Pipelines.gitlab-ci.yml'
build-neural-network:
script:
- mkdir artifacts
- pip install -r requirements.txt
- python mnist-dnn-rich.py
artifacts:
paths:
- "./artifacts"
expire_in: 30 days
write-report-mr:
needs: [build-neural-network]
image: dvcorg/cml-py3:latest
script:
- cd artifacts
- echo > plots.md
- cml-publish model_accuracy.png --md --title 'Model Accuracy' >> plots.md
- cml-send-comment summary.md
- cml-send-comment plots.md
- echo "Published results to MR"
register-model:
needs: [write-report-mr]
script:
- pip install -r requirements.txt
- python register_model.py --workspace $COMET_WORKSPACE --project_name $COMET_PROJECT_NAME --model_name mnist-neural-net
- echo "model registered"
only:
- main
deploy-ml-ui:
trigger: tech-marketing/devops-platform/canara-review-apps-testing
rules:
- if: '$CI_COMMIT_BRANCH == "main"'
when: manual
Let’s break down the CI/CD pipeline by describing the gitlab-ci.yml file so you can use it and customize it to your needs
We start by instructing our GitLab runners to utilize python:3.8 to run the jobs specified in the pipeline:
Image: python:3.8
Then, we define the job where we want to build and train the neural network:
build-neural-network
In this step, we start by creating a folder where we will store the artifacts generated by this job, install dependencies using the requirements.txt file, and finally execute the corresponding Python script that will be in charge of training the neural network. The training runs in the GitLab runner using the Python image defined above, along with its dependencies.
Once the build-neural-network job has finalized successfully, we move to the next job: write-report-mr
Here, we use another image created by DVC that will allow us to publish a report right in the merge request opened by the contributor who changed code in the neural network script — in this way, we’ve brought software development workflows to the development of ML applications. With the report provided by this job, code and model review can be executed within the Merge Request view, enabling teams to collaborate not only around the code but also the model performance.
From the Merge Request Page, we get access to loss curves and other relevant performance metrics from the model we are training, along with a link to the Comet Experiment UI, where richer details are provided to evaluate the model performance. These details include interactive charts for model metrics, the model hyperparameters, and Confusion Matrices of the test set performance, to name a few.
When the team is done with the code and model review, the Merge Request gets approved, and the script that generated the model is merged into the main codebase, along with its respective commit and CI pipeline associated to it, taking us to the next job:
Register-Model
This job uses an integration between GitLab and Comet to upload the reviewed and accepted version of the model to the Comet Model Registry. If you recall, the Model Registry is where models intended for production can be logged and versioned. In order to run the commands that will register the model, we need to set up these variables:
COMET_WORKSPACE
COMET_PROJECT_NAME
In order to do that, follow the steps described here.
It is worth noting that the register-model job only runs when the Merge Request gets reviewed and approved, and this behavior is obtained by setting only:mainat the end of the job.
Finally, we decide to let a team member have final control of the deployment; therefore we define a manual job:
When triggered, this job will import the model from Comet’s Model Registry and automatically create the necessary containers to build the user interface and deploy to a Kubernetes cluster.
This job triggers a downstream pipeline, which means that the UI for this MNIST application resides in a different project. This keeps the codebase for the UI and model training separated but integrated and connected at the moment of deploying the model to a production environment
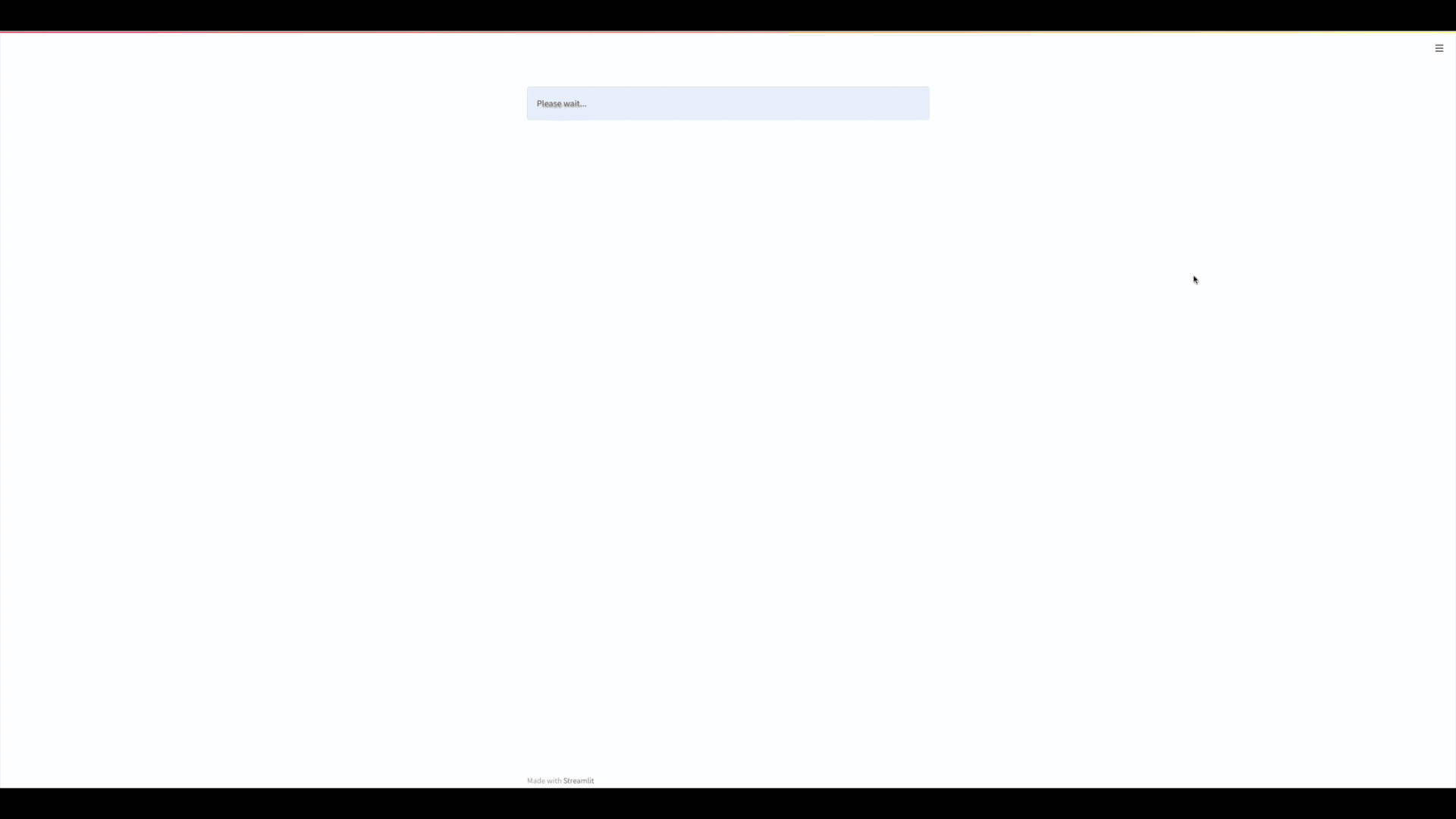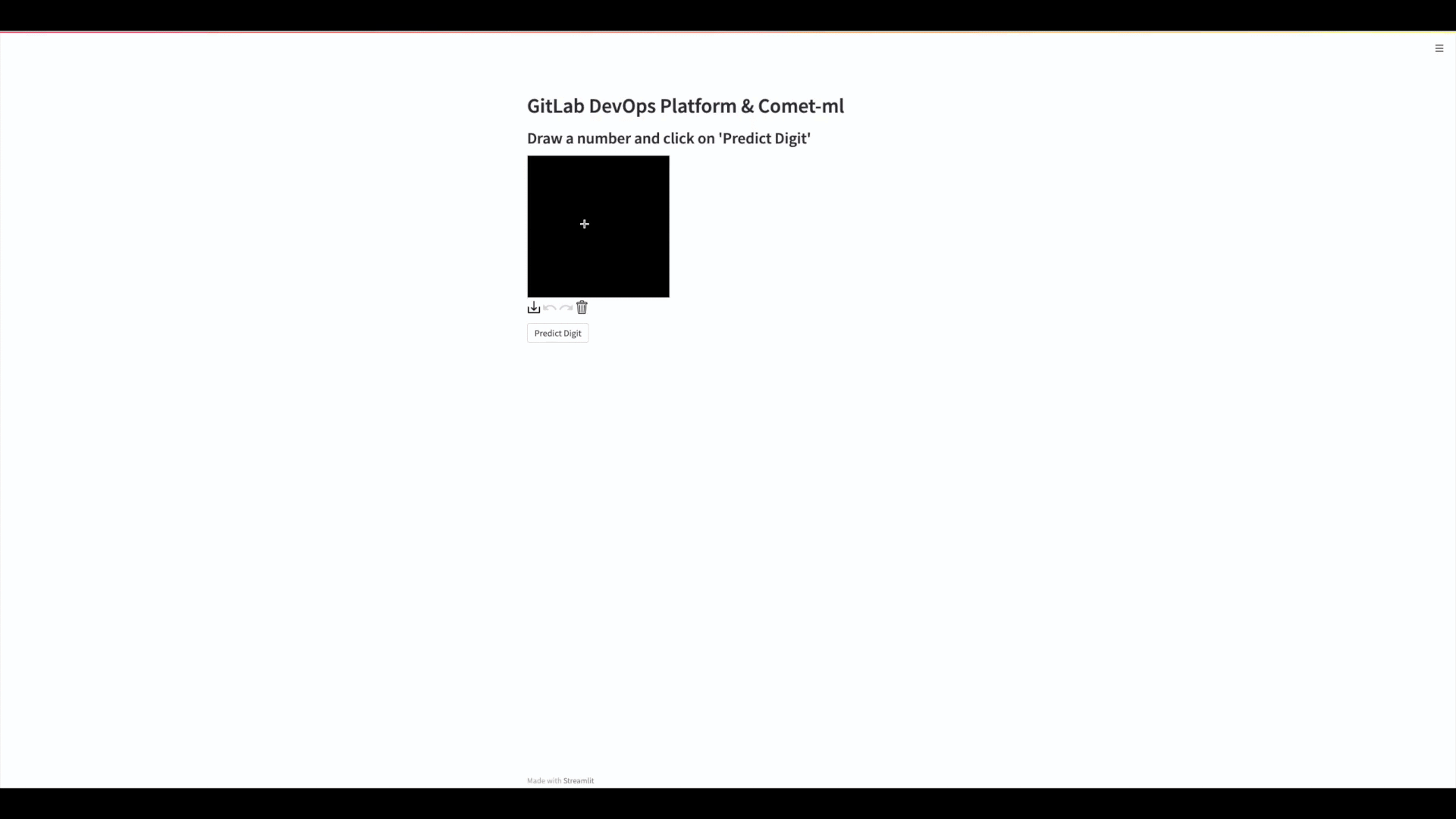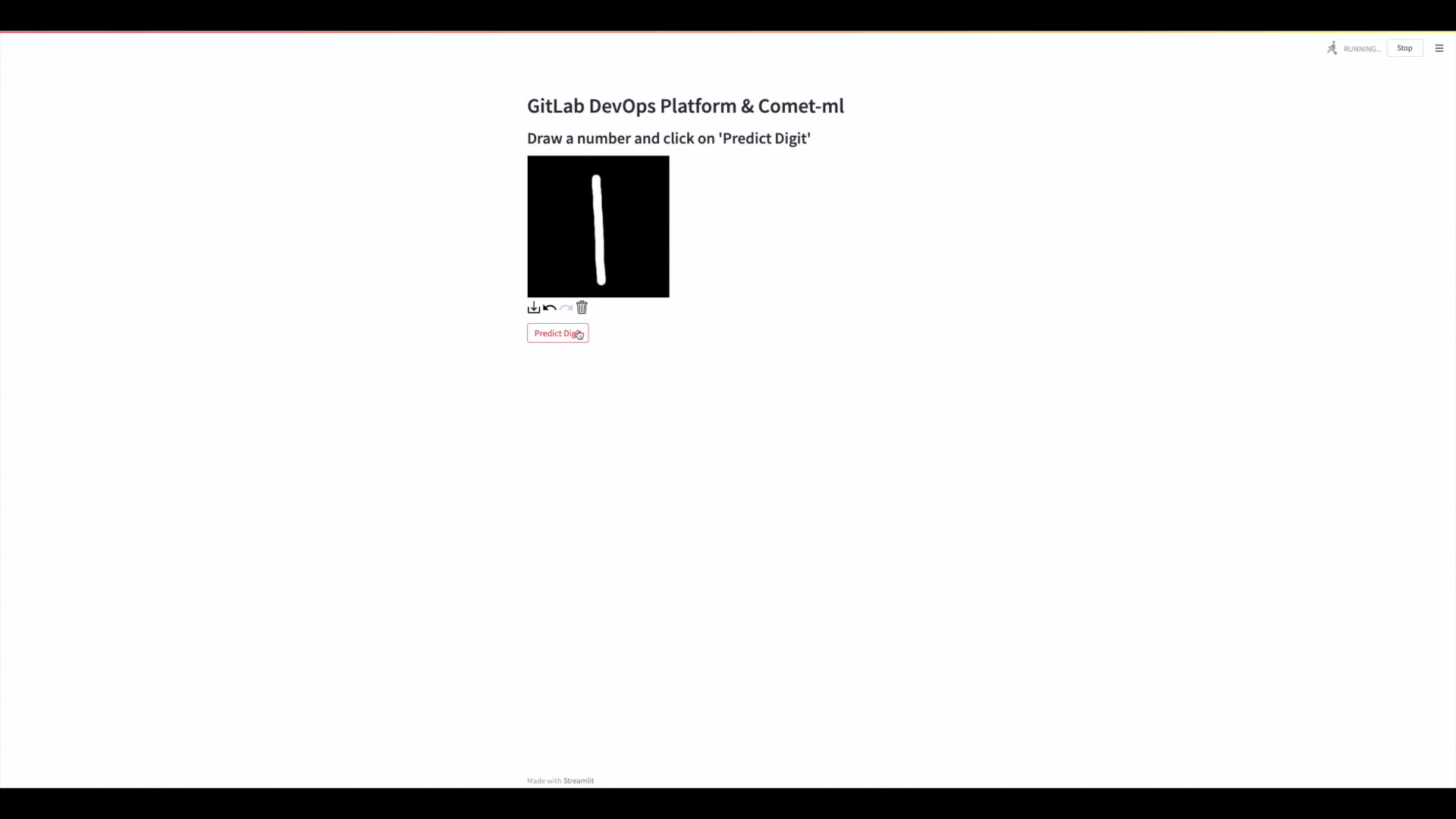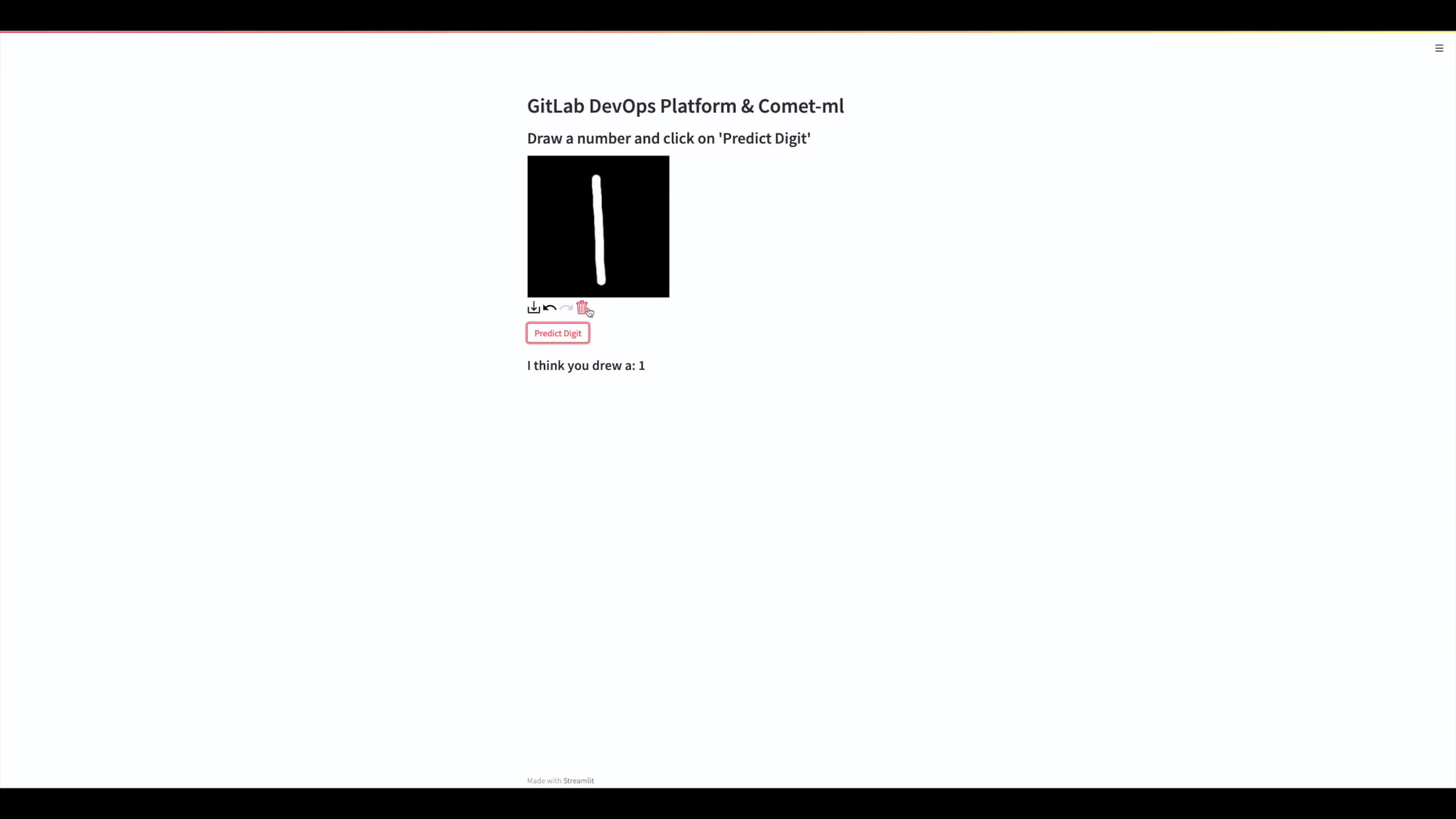
Final Application
Let’s take a quick look at the model that been deployed to our application.
Our application is a simple input box, where you can draw in a digit and have the model predict what it thinks the digit is.
Conclusion/Takeaways
In this post, we addressed some of the challenges faced by ML and Software Teams when it comes to collaborating on delivering ML powered applications. Some of these challenges include
- The discrepancy in the frequency with which each of these teams need to iterate on their codebases and CI/CD pipelines
- The fact that only a single set of experiment assets from an ML experimentation pipeline is relevant to the application
- The challenge of syncing a model or other experiment assets across independent codebases.
Using the GitLab DevOps platform and Comet, we can start bridging the gap between ML and Software Engineering teams over the course of a project.
By having model performance metrics adopted into software development workflows like the one we saw in the issue and Merge Request, we can keep track of the code changes, discussions, experiments, and models created in the process. All the operations executed by the team are recorded, can be audited, are end-to end-traceable, and (most importantly) reproducible.
