
Visual understanding of the real world is the primary goal of any computer vision system, which often requires the guidance of data modalities different from photos/videos, which can better depict the visual cues, for better understanding and interpretation.
In this regard, sketches provide what is perhaps the easiest mode of visually representing natural entities: all one has to do is to look at the photo (or recollect from memory) and draw a few strokes mimicking the relevant visual cues, not requiring any information related to color, texture or depth.
Despite its simplicity, a sketch can be very illustrative and possess minute, fine-grained detailings, and can even convey concepts that are hard to convey at all in words (an illustration of the same is shown in the figure below). Moreover, with the rapid proliferation of touch-screen devices, collecting simple sketches as well as the possibility of using sketches in practical settings have been greatly boosted, enabling sketches to be used for practical applications (such as sketch-based image retrieval for e-commerce applications) rather than merely being an “artistic luxury.”
These factors have led to sketches gaining considerable attention from the machine vision community, leading to their inception and subsequent adoption in several visual understanding tasks, which has led to sketch-vision works breaking the boundaries of being a “niche” research domain and establishing themselves as a high-impact area of interest among the general vision community, leading up to winning Best Science Paper Award at BMVC ’15 and Best Technical Paper Award at SIGGRAPH ‘22.

This article provides a holistic overview of sketch-based computer vision, starting from the unique characteristics of sketches that make them worthy of study, fundamental sketch representation learning approaches, followed by the application of sketches across various computer vision tasks which predominantly lie on the natural image domain. We’ll discuss several interesting works at the intersection of sketches, vision and graphics, as well as outline promising future directions of research. Let’s dive in!
Learning Sketch Representation
Motivation: What‘s unique about sketches?
Sketches have a very unique set of characteristics that set them apart as a modality from conventional photos.
- Dual-modality: Perhaps the most important feature of sketches is that they can be expressed either as a static 2D image or as a set of sequential strokes, represented by relative planar coordinates and a pen-state that determines the start/end of a stroke. In computer graphics, 2D sketches are commonly referred to as “rasterized sketches,” while stroke-wise sketches are stored as “vectorized sequences.” This dual modality existence is understandably unique to sketches, aiding both image level as well as coordinate level time-series representation learning.
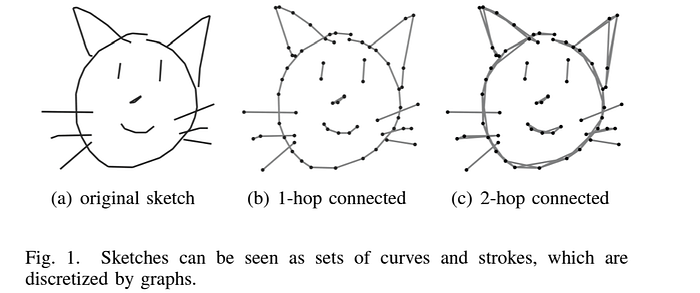
- Hierarchical structure: As mentioned above, vector sketches comprise coordinate-level stroke-wise information, which is essentially a time-series depiction of the drawn strokes. From a natural doodling experience (pretty sure everyone has doodled at least once!) it is very intuitive that one starts sketching from the boundary strokes, gradually moving into finer interior strokes, sketching up to varying extents of detail for each object. This inherently creates a coarse-to-fine hierarchy of strokes, which can be leveraged for a superior understanding of fine-grained sketches and the sketching process itself. For instance, this paper [BMVC ’20] fused sketch-specific hierarchies with those in images using a cross-modal attention scheme for fine-grained SBIR.
- Highly abstract, lacking in background: Sketches are highly abstract in nature, i.e. the stroke density in sketches is greater for objects in relevance/focus rather than the background jargon. This once again follows from the intuitive sketching process- one draws in detail the foreground objects of more importance and keeps the background relatively simpler. Further, objects that are uniquely identified by their shape can be sketched in a very abstract manner(e.g. a pyramid expressed as a triangle). This helps in applications such as object sketching and shape retrieval, where simple doodles depicting the object/structure can be synthesized/used for the respective tasks.
- Low computational storage: Raster sketches are typically binarized (i.e. background with foreground strokes), while vector sketches are stored as temporal coordinates, both requiring very low memory for storage.

Classical sketch representation learning
The two most prominent conventional sketch representation learning tasks include (i) sketch recognition and (ii) sketch generation. It is noteworthy that while recognition is primarily done on raster (or offline) sketches, sketch generation models work on vector (or online) sketches i.e. learning coordinate-wise time-series representations.
Sketch recognition involves the most fundamental task of computer vision — predicting the class label of a given sketch. One of the first works leveraging deep learning includes Sketch-a-Net [BMVC ‘15], which presented a multi-scale CNN architecture designed specifically for sketches, especially at different levels of abstraction. Their architecture is shown below.
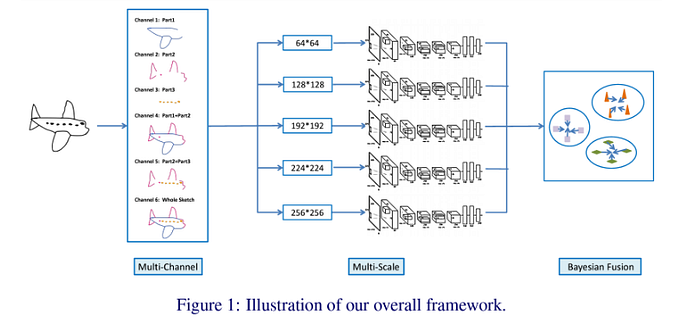
Among several other works, Deep-SSZSL [ICIP ‘19] attempted a scene sketch recognition under a zero-shot learning setup. More recently, Xu et al. proposed MGT which sought to model sketches as sparsely connected graphs, leveraging a graph transformer network for geometric representation learning of sketches, which could model spatial semantics as well as stroke-level temporal information.
For an extensive review of sketch recognition literature, readers are advised to read this survey paper.
Coming to sketch generation, the first work in this domain was the seminal Sketch-RNN [ICLR ‘18] which proposed a sequence-to-sequence Variational Autoencoder (VAE) model, with a bi-directional RNN encoder that takes in a sketch sequence and its reverse as the bi-directional inputs, the decoder being an autoregressive RNN that samples coordinates from a bivariate Gaussian mixture model to reconstruct the sketch sequence from the latent vector obtained at the bottleneck of the VAE. The architecture of Sketch-RNN is shown below.
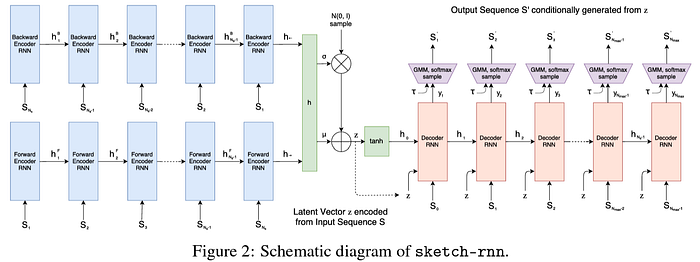
A very recent work, SketchODE [ICLR ’22] for the first time introduced the theory of neural ordinary differential equations for representation learning of vector sketches in continuous time.
Recently, there have been a few attempts at introducing self-supervised learning (SSL) to sketch representation learning, so as to reduce the annotation requirements. This paper proposed a hybrid of existing SSL pretext tasks such as rotation and deformation prediction for learning from unlabelled sketches. More recently, Bhunia et al.’s Vector2Raster [CVPR ‘21] proposed cross-modal translation between the vector (temporal) and raster (spatial) forms of sketches as a pretext task, so that it can exploit both spatial and sequential attributes of sketches.

Leveraging sketches for different vision tasks
In this section, we explore a variety of computer vision tasks involving sketches. Since the domain gap between sparse sketches and other forms of multimedia (RGB photos/videos/3D shapes) is considerably high, each of these tasks typically involves cross-modal representation learning at its core.
Sketch-based Image Retrieval (SBIR)
This is the most popular and well-explored sketch-vision research area, where sketches serve as a query medium to retrieve photos from a gallery. The primary motivation for SBIR is that it is a lot easier to express shape, pose and style features by drawing sketches rather than writing a query text. Moreover, words often fail to adequately describe the exact search query, especially at instance level, where the entire gallery constitutes the same category and one needs to retrieve a particular distinct object only.
One of the earliest works on deep SBIR was this paper [ICIP ‘16], where the authors introduced Siamese networks for learning correspondences between a sketch and the edge map generated from a photo. The reason behind using edge maps is that they somewhat resemble sketches in terms of depicting the outline (and thereby the shape) of an object, whereas RGB photos are very different from sketches. However, more recent works directly learn a sketch-photo joint embedding space, such that all photos resembling a sketch are ideally clustered around that sketch embedding.
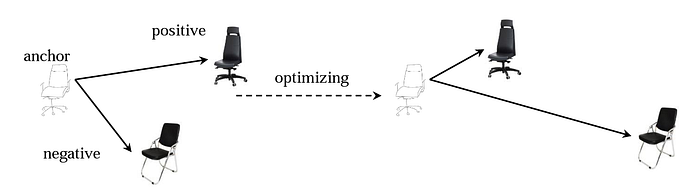
With the ability of sketches to provide visually fine-grained details, the focus on the retrieval task gradually shifted from mere categorical to instance-level — where all objects belong to the same class but are unique entities having subtle differences among them. This is a practical scenario for commercial applications, where one intends to retrieve a specific instance of a given category (say, a specific styled shoe out of a gallery of shoe photos).
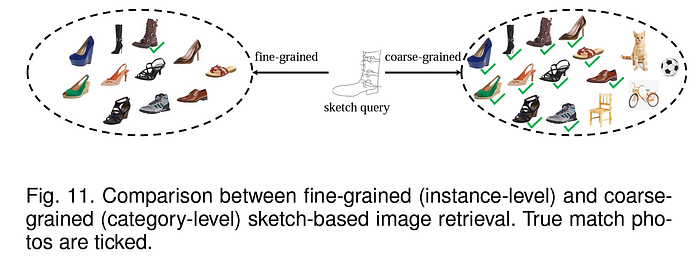
This paper by Song et al. leveraged a spatial attention mechanism that enables the CNN model to focus on fine-grained regions rather than the entire image, along with a skip connection block from the input itself to ensure the feature representations are context-aware and do not get misaligned due to imprecise attention masks. Their model is shown in the figure below.
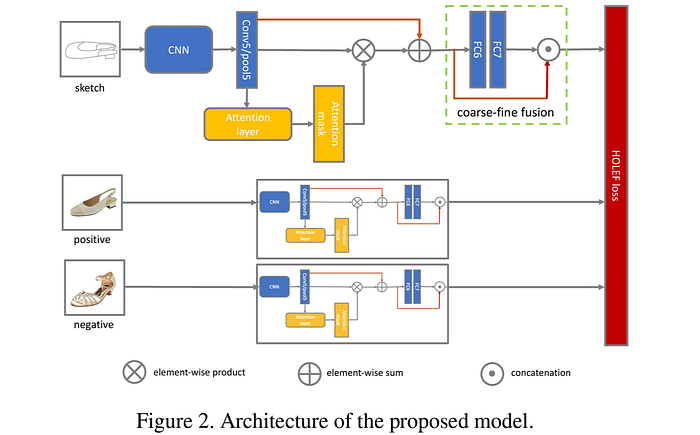
This paper proposed a hybrid cross-domain discriminative-generative learning framework that performs sketch generation from the paired photo as well as the anchor sketch, together with category-level classification loss and metric learning objective for fine-grained SBIR. The authors hypothesize that adding a reconstruction module aids the learning of semantically consistent cross-domain visual representations, which otherwise become domain-specific in naive FG-SBIR models. Their architecture is shown below.

Although sketches have shown great promise as a query medium for content retrieval, there are some inherent challenges they bring to the table, which we shall discuss next:
Style diversity among users drawing sketches: It is practical that sketches drawn by different users will vary considerably in terms of style, due to differences in subjective interpretation and sketching expertise. Since all such sketches ideally represent the same photo, it is essential to design a framework that is invariant with style variations among sketches. Sain et al.’s StyleMeUp [CVPR ‘21] sought to tackle this challenge by devising a framework that disentangles a sketch into a style part, which is unique to the sketches, and a content part that semantically resembles the photo it is paired with. The authors leverage meta-learning to make their model dynamically adaptable to newer user styles, thus making it style-agnostic.

Noisy strokes in sketches: It is a common feeling among people, especially those who do not have an artistic background, that they cannot sketch properly. This often leads to users drawing irrelevant and often noisy strokes, which they mistakenly feel “would yield a better sketch.” It is intuitive that this problem is more prominent in fine-grained sketches where the system itself demands minute detailings, and thus users are prone to go astray with their strokes, thereby hurting retrieval performance.
A very recent work, NoiseTolerant-SBIR [CVPR ‘22] proposed a way to alleviate this issue by a reinforcement learning (RL)-based stroke subset selector that detects noisy strokes by means of quantifying the importance of each stroke constituting the sketch with respect to the retrieval performance. Retrieval results are shown below.

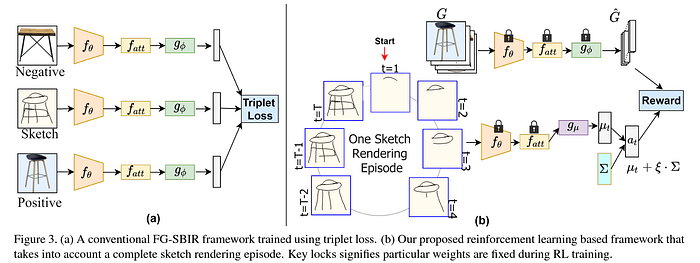
Another recent work, OnTheFly-FGSBIR [CVPR ‘20] brought forward a new paradigm — to retrieve photos on-the-fly as soon as the user begins sketching. The authors proposed an RL-based cross-modal retrieval framework that can handle partial sketches for the retrieval task, along with a novel RL reward scheme that takes care of noisy strokes drawn by the user at any given instant. Their architecture is shown below.
Deep learning models in almost every domain face the bottleneck of data scarcity, and SBIR is no exception. Further, it is noteworthy that collecting fine-grained sketches that pair with photos demand skilled sketchers, which is costly and time-consuming.
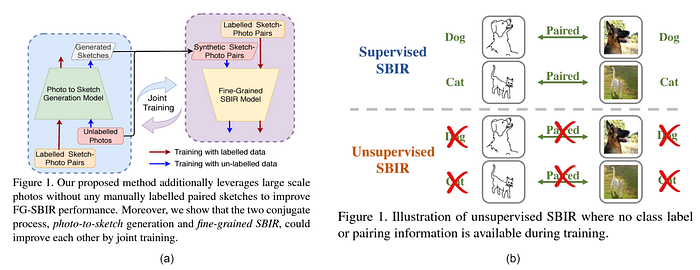
Bhunia et al.’s SemiSup-FGSBIR [CVPR ’21] was one of the first works that aimed at tackling this bottleneck by proposing a pipeline that generates sketches from unlabelled photos and then leverages them for SBIR training, with a conjugate training paradigm such that learning of one model benefits the other. More recently, this work presented a fully unsupervised SBIR framework that leverages optimal transport for sketch-photo domain alignment, along with unsupervised representation learning for individual modalities.
Sketch-Photo Generation
Sketch and photo mutual generation has been an active line of sketch research, the underlying task being to learn effective cross-modal translation between two very different modalities — sketches and photos. Generating sketches from photos would immediately remind one of edge detector filters and thus might seem straightforward, but it is important to note that free-hand sketches are very different from edge/contour maps, primarily due to the two previously mentioned characteristics of sketches — abstract nature and lacking in background.
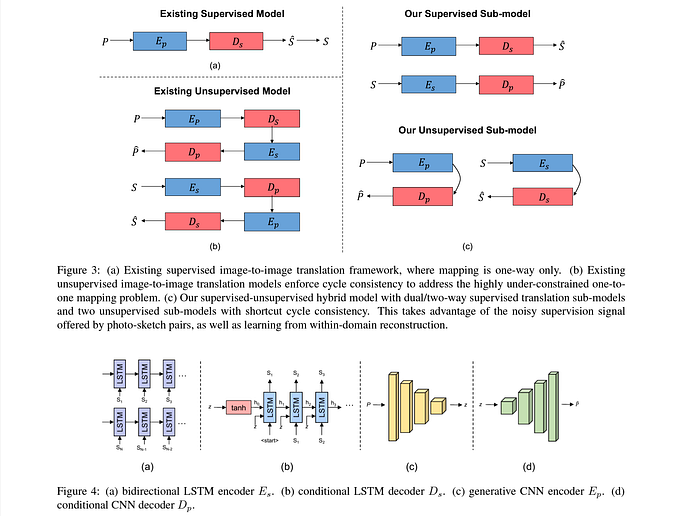
This paper [CVPR ‘18] improved upon the previously discussed Sketch-RNNto propose a photo-to-sketch generative model, where a CNN encoder encodes the input photo, which is decoded into a sequential sketch by the Sketch-RNN decoder. For this, they devised four encoder-decoder sub-models — two for supervised cross-modal translation (i.e. sketch-to-photo and vice-versa) and two for unsupervised intra-modal reconstruction. The authors argue that mere photo-sketch pairing provides noisy and weak supervision due to the large domain gap, which is improved by introducing within-domain reconstruction.
Coming to the reverse process, synthesizing photos from free-hand sketches is a much more challenging task, primarily due to the abstract nature of sketches which do not have much of a background context, something essential to realistic photos. Furthermore, that a sketch can be colorized in several non-trivial color combinations to yield an image makes the synthesis process highly challenging, and often prone to unrealistic results.
Chen et al.’s SketchyGAN [CVPR ‘18] leveraged edge maps along with sketch-photo pairs for training a conditional GAN model. The reason for using edge maps was to incorporate context supervision for the translation task, which is absent in sketches. However, since the ultimate objective was to generate photos from free-hand sketches only, the authors suitably processed the edge maps to make them resemble sketches. Some outputs obtained by SketchyGAN are shown below.

However, despite SketchyGAN obtaining promising results, one limitation the authors pointed out was that their generated images were not visually realistic enough to match real-world photos.
Prompt engineering plus Comet plus Gradio? What comes out is amazing AI-generated art! Take a closer look at our public logging project to see some of the amazing creations that have come out of this fun experiment.
Among other approaches for sketch-to-photo synthesis, Unsupervised-S2P[ECCV ‘20] involves a two-stage image-to-image translation, namely first converting a sketch image to greyscale, followed by colorization of the latter, which is boosted by self-supervised denoising and an attention module, which aids the model to generate images that resemble the original sketches and are also photo-realistic.
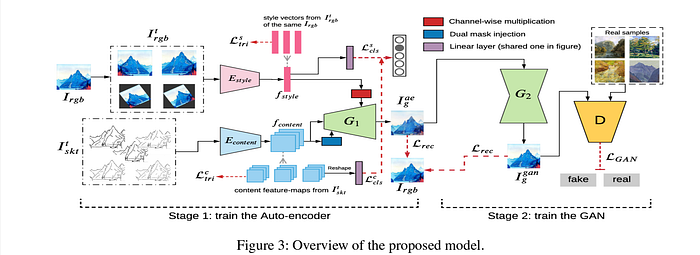
Another work, Self-Supervised-S2I [AAAI ‘21] proposes an autoencoder-based style decoupling the content features of sketches and style features of images, followed by synthesis of photos that bear content resemblance with sketches and conform to the style of the original RGB images. To alleviate expensive sketch-photo pairing, the authors generate synthetic sketches from RGB-image datasets in an unsupervised manner. Further, they apply adversarial loss terms to ensure high-quality image generation at higher resolutions. Their model has been shown below.
A recent paper Sketch Your Own GAN [ICCV ‘21] came up with a very interesting paradigm — to customize the outputs of a pre-trained GAN based on a few sketch inputs. Essentially, they used a cross-domain adversarial loss to match the model outputs with the user sketches, along with regularization losses to preserve the background cues of the original image. During few-shot adaptation with input sketches, the original weights of the GAN model weights change in order to generate images bearing the style of the sketches passed through it. The framework has been shown below.

Some of their outputs have been shown in the figure below. As can be seen, sketches render a distinctive style according to which the GAN outputs are modulated. Another noteworthy observation is that only the image style changes, while the background context and other visual cues (texture, colour etc) are preserved. This can be attributed to the background-lacking nature of sketches, enabling sole focus on the style adaptation of the model on the object(s) in context.

Sketch-guided Image Editing

Sketch-photo joint learning has also led to sketch-based image manipulation, an interactive task where the user draws contour curves (i.e. sketches) over an image to mark the specific changes they intend to incorporate in the photo, and the model adapts itself to reflect the drawn edits in its output.
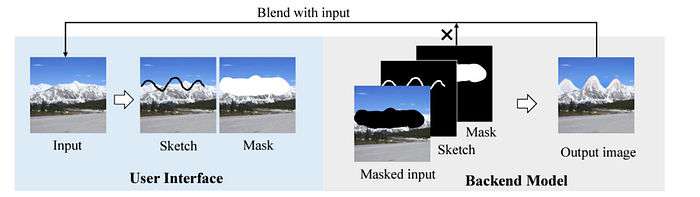
Traditionally speaking, such frameworks would take the drawn contour as well as a mask from the user to specifically indicate the modification region, after which the masked regions would be deemed as “cavities” in an image which needed to be filled in based on the input sketch conditioning. For this cavity filling, they would combine principles of style transfer, image inpainting and image-to-image translation, among others. An illustration of this process is shown below.
However, a major drawback of this framework is that drawing a sketch as well as a mask region is tedious and often redundant too. Moreover, an inpainting pipeline requires dropped-off pixels, which discards context information that can lead to noisy outputs. The paper SketchEdit [CVPR ‘22] sought to address this by proposing a model that can work solely on sketch inputs, removing the need to draw masks as well. The authors used a mask estimator network to predict the modifiable region from the full image based on the drawn sketch, followed by generating new pixels within that region using a generator and blending it with the original image via a style encoder. Their architecture is shown in the figure below.

Sketches for 3D Vision
Free-hand sketches have been particularly useful for 3D shape modelling and retrieval, thanks to their cheap availability as well as being a simple yet effective way of representing shapes.
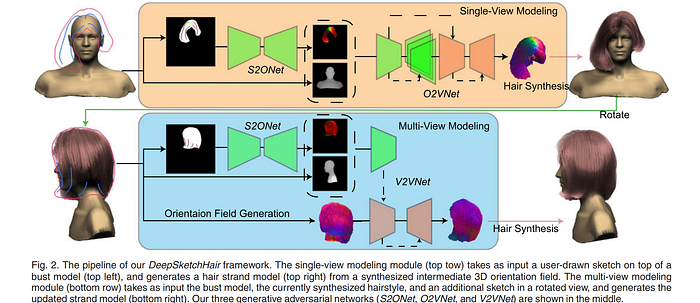
Shen et al.’s DeepSketchHair [TVCG ‘20] presented a GAN-based strand-level 3D hairstyle modeling framework from 2D hair strokes. The pipeline starts with a sketched hair contour along with rough strokes depicting hair growing direction, from which a mask is obtained that is translated into a dense 2D orientation field, which is then converted into a 3D vector field. To enable multi-view hair modeling, a voxel-to-voxel conversion network is used that updates the 3D vector field based on user edits under a novel view. Their overall architecture is shown below.
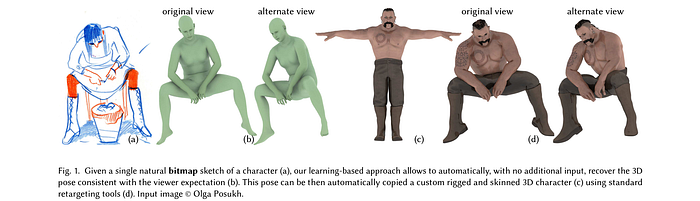
Among more recent works, this paper [3DV ‘20] discussed various challenges for sketch-based modelling along with a comprehensive evaluation of solutions to tackle the same, while Sketch2Pose [SIGGRAPH ‘22] presented a framework to estimate 3D character pose from a single bitmap sketch, by predicting the key points of the image relevant for pose estimation.
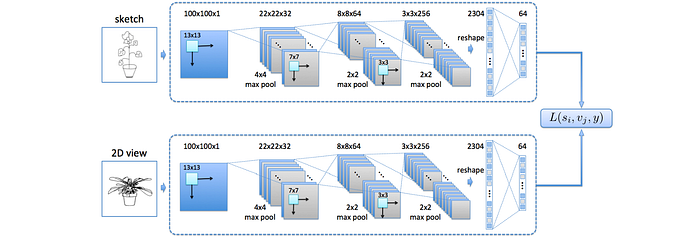
Another popular sketch-based 3D vision task is sketch-based 3D shape retrieval (SBSR), which can be intuitively considered equivalent to the SBIR task (discussed above), except that the domain gap between 2D sketch and 3D shape is significantly greater than that between 2D sketch and 2D photo. Likewise, it has seen the use of end-to-end metric learning-based Siamese networks for learning cross-domain correspondences, such as the framework proposed in this CVPR ’15 paper.
Recently, Qi et al. proposed fine-grained SBSR [TIP ‘21] as an extension of categorical SBSR to instance-level, where fine-grained sketches are provided as queries to retrieve a particular 3D shape among a gallery of shapes of the same class. Their work leveraged a novel cross-modal view attention mechanism to compute the best combination of planar projections of a 3D shape, given a query sketch.
Sketch-modulated Image Classifier
Few works have tried incorporating sketches to modulate the behaviour of classification models, such as converting a sketch classifier into a photo classifier, extending the ambit of a photo classifier so as to include fine-grained classes within a single class, and so on. The reason why sketches can be useful in these areas can be attributed to the cheap availability of free-hand sketches compared to exemplar class photos, as well as the fine-grained nature of sketches which can help partition the latent representation of a coarse class into finer ones. Typically, the mechanism involves perturbation of model weights by passing a few sketch samples through it and re-training the model to adapt to the new conditions, i.e. in a few-shot manner.
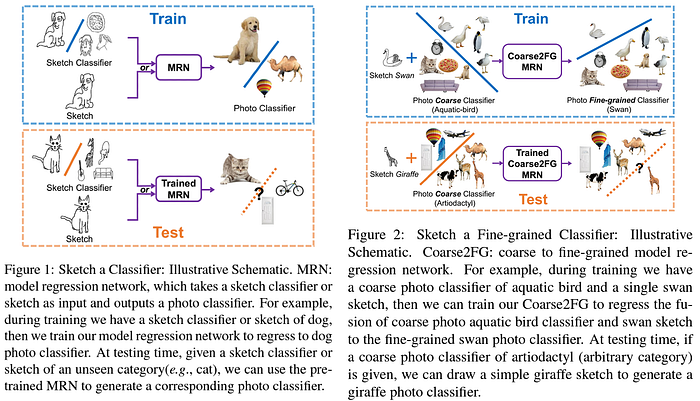
The paper Sketch-a-classifier [CVPR ‘18] was the first work in this area, which proposed a model regression network to map from free-hand sketch space to the photo classifier embedding space. Their framework alleviated the use of labelled sketch-photo pairs and showed that such a cross-modal mapping can be done in a class-agnostic manner, i.e. new classes could be synthesized by users based on sketch inputs. Further, the authors also demonstrated a coarse-to-fine setup, where a photo classifier trained on coarse labels could be extended to accommodate fine-grained labels, the sketches serving as a guiding signal to determine the fine-grained category. Their pipeline is shown in the figure below.
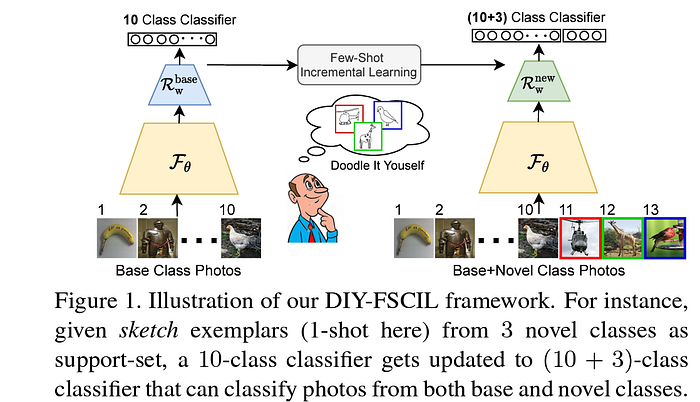
A more recent paper DIY-FSCIL [CVPR ‘22] explored class incremental learning (CIL) to extend a previously trained N-class photo classifier to an (N+k)-class classifier, where representative sketch exemplars (typically 1) provided by the user serve as a support set for the new k classes. This work leveraged cross-domain gradient consensus to ensure gradient space sketch-photo domain alignment, thereby generating a domain-agnostic feature extractor. However, one of the prominent challenges CIL faces is the preservation of knowledge of previous classes while learning the new ones (the effect commonly termed “catastrophic forgetting”). To ensure this, the authors infused in their framework knowledge distillation and graph attention network-based message passing between old and new classes.
Other Works
Having discussed several sub-domains of sketch-based computer vision, we now explore a few uniquely exciting works in recent times involving sketches:
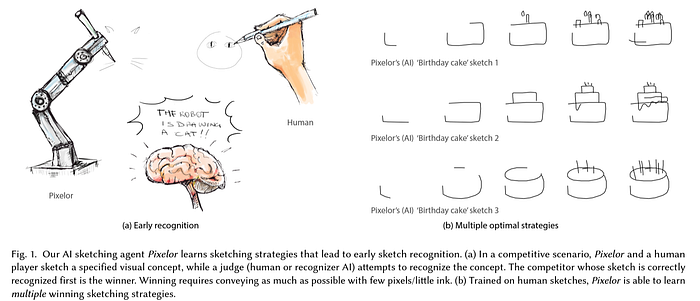
Bhunia et al.’s Pixelor (SIGGRAPH ’20; figure shown above) presented a competitive AI sketching agent that exhibited human-level performance at generating recognizable sketches of objects. The recipe to their framework was at finding the most optimal sequence of strokes that can lead to an “early” recognizable sketch. The authors employed neural sorting for the ordering of strokes, along with an improved Sketch-RNN network by fusing the principles of Wasserstein autoencoder, that leverages an optimal transport loss for aligning multi-modal optimal stroke sequence strategies.

Vinker et al.’s CLIPasso [SIGGRAPH ‘22] sought to leverage geometric and semantic simplifications for object sketching at various levels of abstraction. They considered sketches to be sets of Bézier curves and proposed an optimization mechanism on the curve parameters with respect to a CLIPencoder-based perceptual loss. In order to enforce geometrical consistency between the generated sketch and the original object, the authors used L2 regularization between the intermediate layer outputs of the CLIP encoder from the image and sketch. Further, for a better initialization of the parametric curves constituting the sketch, a pre-trained saliency detection network was used to generate the saliency heatmap of the image, which is used as the distribution to sample the initial locations of the strokes. Their framework is shown below.

Conclusion
As fast-growing as it has been, sketch research has brought up several interesting applications and solutions to existing problems in computer graphics and vision. From sketch-based image retrieval to leveraging sketches for few-shot model adaptation, the efficacy of sketches across cross-domain tasks looks really promising for further research.
This article first discussed the motivation behind using sketches for vision tasks along with the unique set of characteristics and challenges they bring to the table, followed by a holistic dive into sketch representation learning and its current trends. We also explored several applications of sketches in computer vision, typically cross-modal tasks such as SBIR, sketch-photo synthesis and so on.
Looking ahead, future directions of sketch-based vision worth exploring would constitute extending object-level sketches to scene-level for visual understanding, sketches for 3D vision (especially AR/VR) applications, and so on. Thus, to conclude, the potential of sketches in commercial, artistic and multimedia applications is to be realized to its fullest, something that the vision community looks forward to.
Notes:
- An up-to-date collection of sketch-based computer vision works can be found at: https://github.com/MarkMoHR/Awesome-Sketch-Based-Applications
- Readers interested in an extensive and in-depth survey of sketch-based computer vision can check out this survey paper: Deep Learning for Free-Hand Sketch: A Survey, IEEE TPAMI, 2022
- Readers looking for a practical dive into creative AI involving sketches can check this out: https://create.playform.io/explore
- For a live demo of Pixelor (discussed above), interested readers may visit: http://surrey.ac:9999/
- Some of the research groups that publish regularly on sketch-oriented vision are:
- SketchX Laboratory, University of Surrey, Led by Prof. Yi-Zhe Song
- Digital Creativity Lab, CVSSP, University of Surrey
- Smart Geometry Processing Group, University College London
- School of Creative Media, City University of Hong Kong
- PRIS-CV Group, School of Artificial Intelligence, BUPT
- GraphDeco, INRIA
