
LLM training shapes everything from what a model knows to how it reasons and responds. So, understanding how models are trained is essential for understanding how and why they behave the way they do.
But clearly defining modern LLM training is increasingly difficult. As models have evolved from early autoregressive architectures into today’s multimodal systems with advanced reasoning and alignment capabilities, their training pipelines have become more nuanced and less standardized. This makes it challenging to pinpoint what a typical training process looks like.
This complexity is worsened by inconsistent terminology. Researchers frequently introduce informal terms without clear definitions. These inconsistencies, while perhaps inevitable due to rapid progress, complicate the task of comparing, reproducing, or clearly understanding LLM training approaches.
And, without a rough map of the process, interpreting model behavior becomes guesswork.
The following few articles will attempt to provide that map. They’re based on my own notes, compiled while trying to make sense of the ecosystem. I hope they’re useful to others facing the same challenge.
Pretraining 101
A logical starting point is pretraining, the earliest stage in the training pipeline.
Most guides to LLM training skip over pretraining entirely and begin directly with fine-tuning. This makes sense in practice: pretraining is exorbitantly expensive, and with many high-quality foundation models readily available, you’re unlikely to pretrain a model yourself. Still, it’s crucial to understand pretraining, since it fundamentally shapes a model’s capabilities and influences its behavior.
Like many terms in the LLM ecosystem, “pretraining” is used inconsistently. For example, “pretraining” might narrowly refer to basic next-token prediction on raw text, or it could include multi-stage training with synthetic objectives and instruction tuning– steps that in other contexts might fall under “post-training.” These variations make it difficult to settle on a single, consistent definition. And as new techniques emerge, the boundaries around pretraining continue to shift.
Rather than starting with an abstract definition, I’ve found it more useful to examine pretraining through the lens of concrete examples. First, I’ll discuss how the concept of a distinct pre-training phased originated with ULMFiT, then explore how InstructGPT formalized and extended the approach into a widely adopted standard. From there, we can better understand how modern techniques have diverged or expanded from this foundation.
The goal is not to define pretraining once and for all, but to build a practical and evolving understanding of how it works in practice.
We’ll start with the model that introduced the core structure for pre-training and fine-tuning in NLP, ULMFiT.
The Roots of Pretraining: ULMFiT and InstructGPT
Before 2018, most NLP models were trained from scratch on small, task-specific datasets. This process was slow, required substantial labeled data, and often delivered poor results, especially for low-resource tasks. In contrast, transfer learning was already standard in computer vision, where models pretrained on large datasets such as ImageNet or MS-COC were routinely fine-tuned for specific tasks.
Why ULMFiT was a turning point
ULMFiT (Universal Language Model Fine-tuning for Text Classification) changed that. Written by Jeremy Howard and Sebastian Ruder, it introduced a general-purposed language model that could be pretrained on extensive text corpora and then fine-tuned efficiently with minimal labeled data. This showed that a single pretrained model could be adapted to a wide range of downstream tasks, effectively establishing inductive transfer learning as a practical and beneficial method for NLP.

This set the stage for subsequent breakthroughs such as BERT, GPT, and other transformer-based models. These models all follow the same core principle: large-scale pretraining followed by task-specific fine-tuning.
Transfer learning types
As compared with other types of transfer learning, inductive transfer learning, in particular, proved critical due to its capacity to:
- Significantly reduce the amount of labeled data required
- Improve generalization, especially for tasks with limited or expensive annotations
- Speed up training and improve final performance
| Inductive | Transductive | Unsupervised | |
| Definition | Transfers knowledge acquired from labeled data in a source domain to help solve a related but distinct target task | Applies knowledge from labeled source data directly to unlabeled target data without generalized to new tasks | Finds shared structures or representations between unlabeled source and target data without labels |
| Source Data | Labeled | Labeled | Unlabeled |
| Target Data | Labeled (typically fewer samples) | Unlabeled | Unlabeled |
| Objective | Enhance learning on a related task | Infer labels or predictions directly on target domain | Lear common representations useful for multiple tasks or domains |
| Examples | ImageNet pretraining –> medical image classification; next-token prediction –> instruction following | Sentiment analysis in English –> Sentiment analysis in French | Embedding transfer for document clustering |
Although small by today’s standards, ULMFiT marked a pivotal turning point. It introduced the pre-train fine-tune approach that has since become a cornerstone of modern NLP.
The InstructGPT Training Pipeline
In 2022, InstructGPT scaled the ideas introduced by ULMFiT and formalized a multi-stage training pipeline that has since become standard in modern language models. It marked a key shift from generic next-token prediction to producing models capable of following complex instructions and aligning more closely with human preferences.
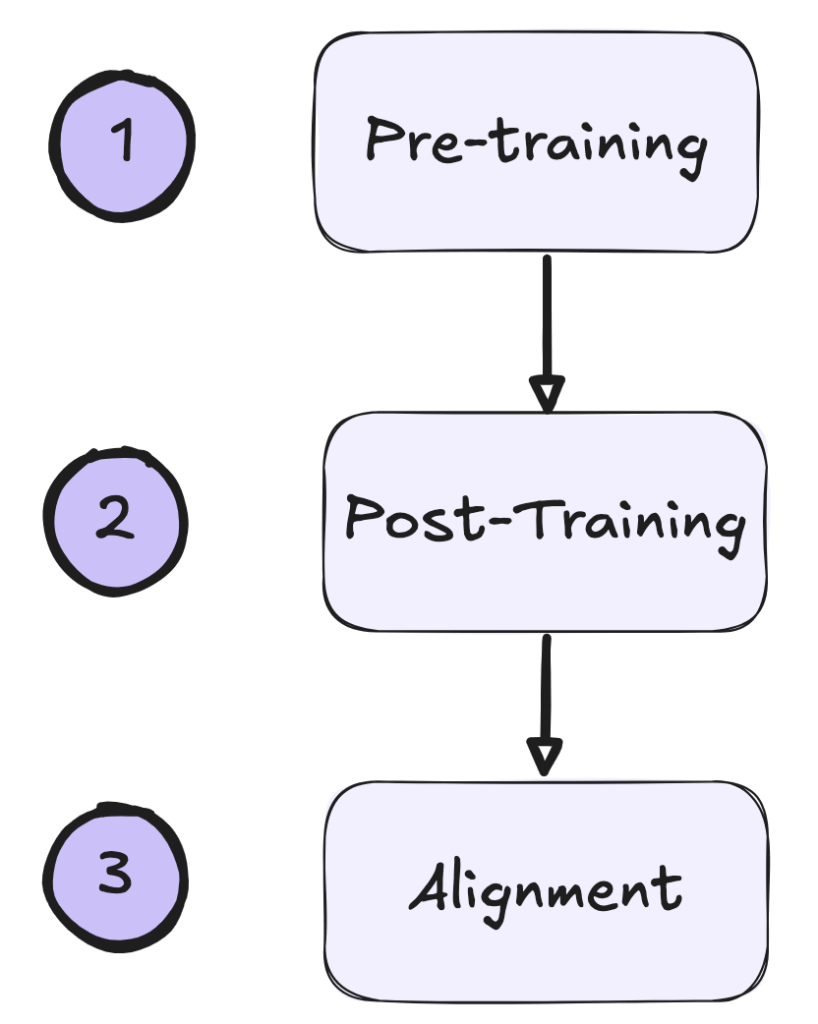
While not the first or largest model of its kind, InstructGPT established the three-stage framework that underpins many modern LLMs: (1) pretraining on raw data, (2) supervised fine-tuning on task-specific examples, and (3) reinforcement learning from human-in-the-loop feedback (RLHF). This approach laid the foundation for ChatGPT and many successors.

As training methods have evolved, however, it’s often more practical to describe LLM development in two broad phases: pretraining, which builds general-purpose language capabilities, and post-training, to refine and align these capabilities. This broader view encompasses a variety of post-training techniques, including but not limited to supervised fine-tuning and RLHF.
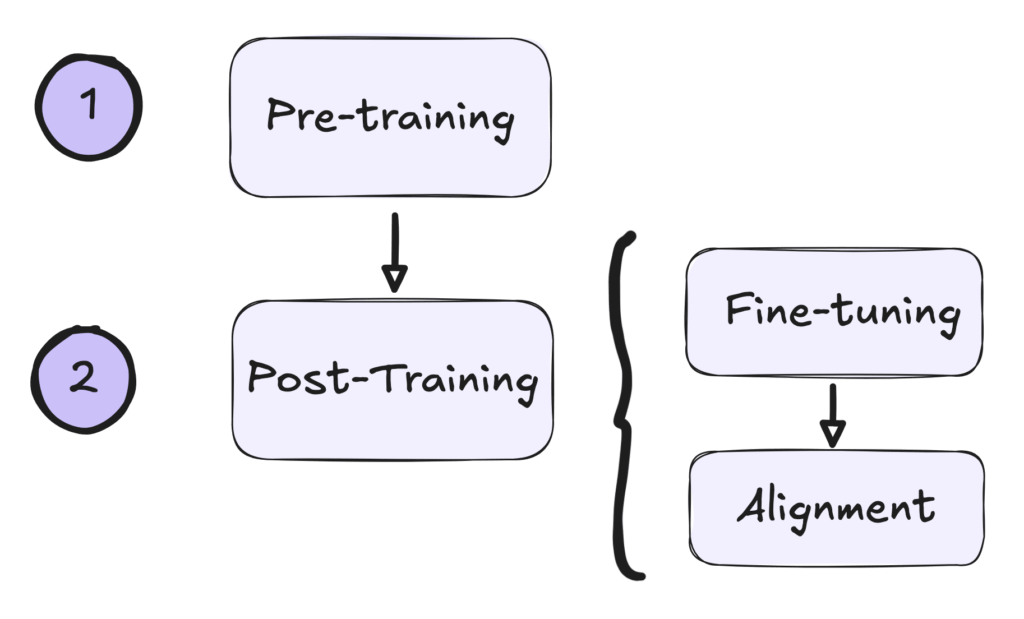
Both the three-stage and two-stage representations of the pipeline appear frequently in literature. The three-stage approach remains widely referenced due to its clear historical and practical significance. Meanwhile, the two-phase representations can provide greater flexibility and inclusivity for capturing modern innovations in model training and alignment techniques.
Why these frameworks still matter
Though they both describe roughly the same process, I’ve included them both here because of their role in the history of pretaining as a concept. ULMFiT introduced the pre/post-training paradigm from a research perspective, while InstructGPT formalized it into the standard training pipeline many teams use today. I’ll dive deeper into the subsequent training stages, like fine-tuning and alignment, in a future article. In. this article, we’ll start by unpacking pretraining as defined in the original InstructGPT pipeline, then examine how contemporary systems have evolved from that blueprint.
How Did InstructGPT Pretraining Work?
It’s important to keep in mind here that “pretraining” as a distinct phase of training emerges as an idea well after the techniques used in pretraining were already established. InstructGPT’s pretraining phase, in essence, is just the normal training phase used to train GPT-3. By applying a post-training phase to GPT-3, and tuning it to follow instructions, OpenAI codified distinct pre and post-training phases for their models. So, what does pretraining look like, generally speaking?
What happens during pretraining
In most pretraining phases, the model learns general language patterns and representations by predicting the next token in a sequence. Because pretraining involves the majority of the training data the model will ever see, it is also where it acquires most of its factual and commonsense knowledge (also referred to as “world knowledge”).
Pretraining is typically done using causal language modeling (CLM), a self-supervised objective where the model is trained to predict the next word, given previous context. It’s worth noting that different model families sometimes use different pretraining objectives. For instance, masked language model (MLM), where the model fills in blanks in text, is used in BERT. Some recent models even combine objectives. However, for large generative models that produce free-form text, the autoregressive next-token approach has become the standard.
Much of the massive pretraining corpus consists of raw, unlabeled web data. The internet’s vast supply of text has made it possible to collect the large-scale datasets required for pretraining language models. Since the object is next-token prediction, explicit labels are unnecessary– the next word is already part of the sequence. This is why the process is called self-supervised learning.
The output of pretraining is a base model (or foundation model) that predicts the next token in a sequence. A base model has absorbed a broad distribution of facts, language patterns, and coding styles, but has not yet been aligned or fine-tuned for specific tasks.
Why pretraining isn’t enough
At scale, pretraining often leads to emergent capabilities such as summarization or question answering, even without explicit supervision. These abilities, however, are typically unrefined and unreliable. Inconsistencies, odd writing styles, and even biases naturally emerge, reflecting patterns in the underlying training data. That’s why modern language models don’t stop at pretraining: they undergo additional fine-tuning and alignment to improve task performance and make their behavior more consistent with human expectations. I’ll cover these stages in a later article.
The Data Behind LLM Pretraining
Pretraining is by far the most resource-intensive stage in the training pipeline. Modern LLMs are pretrained on massive, diverse corpora. These may include web data, books, code, and– in the case of multimodal models– images, audio, or other modalities. Depending on the model’s size and intended use, the training data can range from hundreds of billions to over 10 trillion tokens. For many proprietary models, the exact token count is undisclosed, but the scale continues to grow.
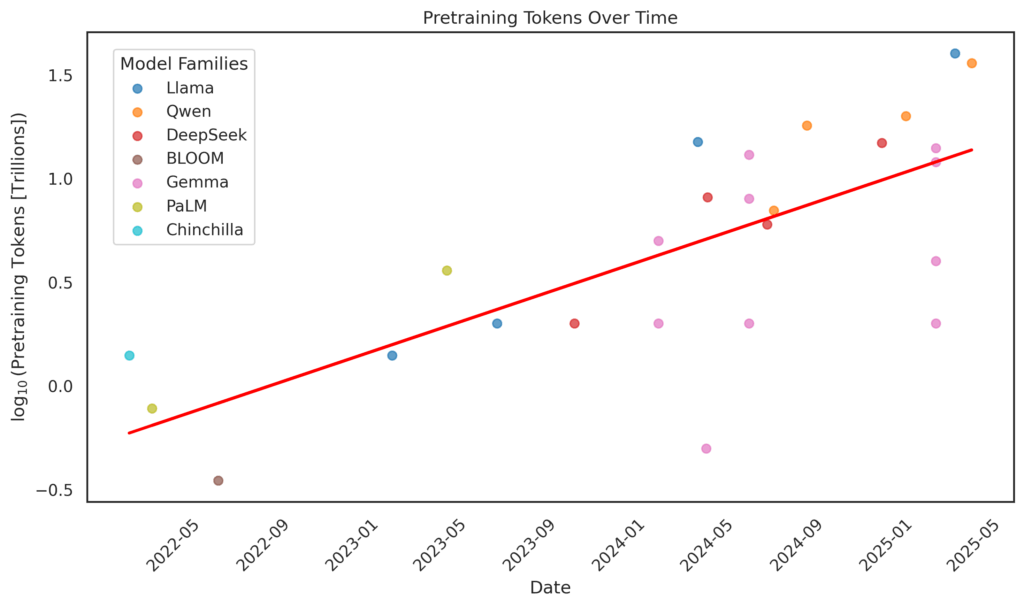
Bigger models aren’t always better
This trend towards larger datasets is not arbitrary. In 2022, DeepMind demonstrated that more data can yield better results than simply scaling model size. Their 70B parameter model, Chinchilla, was trained on 1.4 trillion tokens–over four times more than the 280B parameter Gopher model. Despite being smaller, Chinchilla outperformed Gopher by optimizing the ration of data to parameters and using compute more efficiently, challenging the belief that bigger models always perform better.
The messy reality
The abundance of internet data is both an advantage and a liability. While scaling laws suggest that more data improved model performance, large-scale scraping introduces serious issues including copyright violations, inclusion of proprietary or harmful content, and inconsistent data quality.
![In an episode of Lex Fridman’s podcast, AI2’s Nathan Lambert described how the unusual structure of r/microwavegang’s posts caused huge loss spikes that “blew up [their] earlier models.” This anecdote emphasizes the wide variety of data quality available on the internet and the importance of data curation.](https://www.comet.com/site/wp-content/uploads/2025/07/Screenshot-2025-06-25-at-8.13.59-AM-1024x771.png)
As a result, cleaning and filtering pretraining data has become a key focus of research. Common strategies include deduplication, domain balancing, and selecting data that mimics high-quality corpora, though these methods remain largely heuristic.
With mounting legal and ethical scrutiny, there is also increasing interest in ethically-sourced pretraining data, especially as some datasets are removed over legal concerns, making previous research difficult or impossible to reproduce.
Curation, curriculum, and cost
Recent work also suggests that organizing training data by difficulty–using curriculum learning rather than random sampling– can improve training stability and convergence speed.
Despite, or perhaps because of, these challenges, data curation is widely viewed as one of the most critical factors in pretraining and has become one of the primary non-compute costs in LLM training, especially for organizations building models from scratch.
Before examining how modern LLMs diverge from the InstructGPT training blueprint, it’s helpful to briefly recap that baseline:
- Pretraining is the first stage in which the model is exposed to data.
- The training objective is next-token prediction, a self-supervised tasks that does not require labeled data.
- The data consists of large-scale, unlabeled corpora— typically billions to trillions of tokens drawn from the web, books, and other sources.
- The model learns general language patterns, syntax, semantics, and factual knowledge through statistical correlation in text.
- The output is a base (foundation) model trained solely to predict the next token, without explicit conditioning or alignment.
- In practice, large-scale pre-training can produce some emergent behaviors (e.g., instruction following), but these are typically fragile, inconsistent, and require further fine-tuning and alignment to be reliable.
A Survey of New Pretraining Approaches
As noted at the beginning, the boundaries between training stages are increasingly blurred. The research landscape is highly dynamic, and in recent years, numerous pretraining methods have emerged that go well beyond simple next-token prediction on raw, scraped text.
In the following sections, I’ll highlight a few notable approaches. However, there are dozens–if not hundreds– of additional techniques worth exploring for those interested
Pretraining on Instruction-response Pairs
Traditional LLM pretraining feeds the model a large corpus of raw text without any explicit instruction/answer structure.
Instruction-response augmented pretraining takes a different approach by enriching the training corpus with instruction-response pairs, often generated synthetically using stronger models. These pairs are inserted alongside the original text to simulate task demonstrations such as Q&A, summarization, or classification. While instruction-style pretraining remains relatively uncommon, synthetic examples (rather than human-curated ones) have become the norm due to their scalability.
[
{
"instruction": "Write a limerick about a
pelican.”,
"input": "",
"output": "There once was a pelican so fine,
\nHis beak was as colorful as
sunshine,\nHe would fish all day,\nIn
a very unique way,\nThis pelican was
truly divine!\n\n\n"
},
{
"instruction": "Identify the odd one out from
the group.",
"input": "Carrot, Apple, Banana, Grape",
"output": "Carrot\n\n"
},
]Importantly, instruction-style pretraining retrains the same next-token prediction objective. The model is simply trained on sequences where the instructions and their responses are part of the text stream, allowing it to learn prompt-following behavior in a self-supervised manner. This setup introduces a form of multitask supervision during pretraining without requiring new objectives or labeling schemes.
This instruction-augmented phase typically occurs after the initial base model pretraining and is sometimes referred to as “intermediate pretraining” or “pre-finetuning.” It blends instruction-style data with standard corpora before later stages such as supervised fine-tuning or alignment.
Models pretrained in this way often demonstrate imrpoved zero-shot task performance and better alignment with user intent. In experiments, a 500M parameter model trained on an instruction-augmented corpus (100B tokens) matched the performance of a 1B model trained on three times more plan text (300B tokens). Thee models not only outperform their vanilla-pretrained counterparts on benchmarks but also exhibit higher data efficiency and respond more effectively to downstream instruction tuning.
Pretraining in Multiple Phases
LLMs can also be pre-trained in multiple sequential phases, rather than on a single static data mix. In a multi-phase setup, each phase uses a different portion or distribution of training data, often arranged by quality or difficulty. Research suggests that as an LLM learns, its data needs evolve, making it beneficial to feed different data at different stages. This phase-wise curriculum approach aims to progressively refine the model’s abilities (analogous to curriculum learning) without introducing any supervised fine-tuning or alignment steps.
One strategy is to order training data from easier to harder (or vice versa) across phases, for example, based on data perplexity. A simpler approach is to use a broad, diverse data mix in an early phase, then switch to high-quality or domain-specific data in a later phase. Multi-phase pretraining is also used to adapt LLMs to specific domains. After general pretraining, a model can be further pretrained on in-domain corpora (e.g., biomedical text or legal documents) as a second phase. This domain-adaptive pretraining consistently yields better downstream results on domain-specific tasks.
Continual Pretraining
Continual pretraining is a specific subset of multi-phase pretraining. While all continual pretraining is multi-phase, not all multi-phase setups qualify as continual– some are planned in advance as part of a single, contiguous training curriculum.
Continual pretraining in LLMs refers to the practice of extending an already pretrained model by further training it on new, unlabeled data. Unlike traditional pretraining, which occurs in a single, extensive phase on a fixed dataset, continual pretraining resumes training from an existing checkpoint using additional data collected at later points in time or from previously unerrepresented domains.
| Feature | Multi-phase pretraining | Continual pretraining |
| Timing | Planned before training begins | Resumes after training has concluded |
| Motivation | Curriculum learning, efficiency improvements, quality control | Domain adaptation, knowledge update |
| Continuity | Part of the initial training design | Often an external update or an extension |
| Examples | Chinchilla, Qwen-2, PALM 2, DeepSeek-V2 | BioBERT, LLaMA-2 building on LLaMA-1 |
The primary objective is to integrate new knowledge or adapt the model to different contexts without discarding previously learned information or training an entirely new model. In other words, continual pretraining lets an LLM “keep learning” from fresh data without having to train an entirely new model from scratch.
When and why to use continual pretraining
One key motivation for the continual pretraining is to adapt models to new domains that were underrepresented in the original training data. If an LLM needs to operate in a specialized domain (e.g., biomedical or legal text), simply fine-tuning on a small task-specific dataset may not capture the domain’s jargon or nuances. Continual pretraining on a large corpus from that domain can markedly improve the model’s performance.
For example, BioBERT— a variant of BERT continually pretrained on biomedical literature– achieved substantial performance gains over its generic conterpart on tasks such as biomedical named entity recognition (NER), relation extraction, and question-answering.
What’s more, studies have found that adding an extra phase of unsupervised pretraining on in-domain data also yields substantial gains on downstream tasks.
Another motivation is keeping the model’s knowledge current. As language and information constantly evolve, an LLM’s static pretrained knowledge gradually becomes outdated. Periodically retraining the model with reccewnt data ensures its knowledge base remains relevant.

But efficiency remains the primary advantage of continual pretraining. Models converge faster starting from pretrained checkpoints, requiring substantially few tokens compared to training from scratch. Meta reported considerable benchmark improvements with relatively modest additional training for LLaMA-2. DeepSeek similarly achieved notable gains in reasoning tasks by continuing training with math-focused instruction datasets.
This approach is widely used in practice For instance, OpenAI’s GPT-3.5 has likely undergone updates beyond its initial training period. Similarly, Meta’s LLaMA-2 built on LLaMA-1 checkpoints, continuing training on a broader and more recent corpus. Open models like DeepSeek and Mistral also incorporate continual pretraining to enhance their reasoning, code, or instruction-following capabilities.
This process typically resumes from an existing checkpoint of the base mode, using the same tokenizer and architecture. The original loss function (e.g., cross-entropy) is also preserved. However, significant domain shifts (like transitioning from general web text to specialized domains such as biomedical or legal text) can require careful data selection and sometimes tokenizer adjustments.
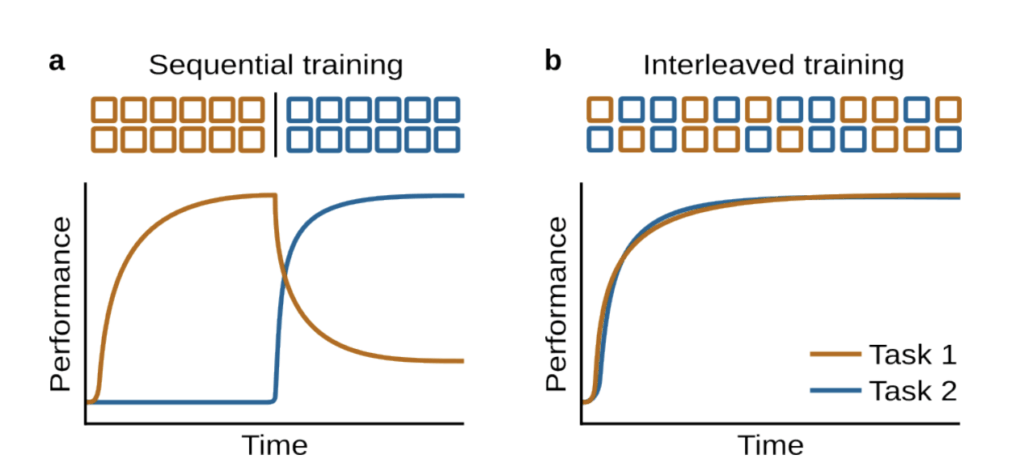
Common pitfalls and mitigations
Continual pretraining introduces challenges, notably distributional drift, catastrophic forgetting, and an increased risk of repetitive outputs (e.g., token or phrase repetition). Training exclusively on new, distributionally distinct data may also degrade performance on previously learned tasks.
Researchers often mitigate these issues by carefully blending new and old data during training (so-called “data mixing“) or employing weight regularization techniques to anchor the model to its prior knowledge.
In short, continual pretraining enables language models to remain up-to-date or become domain-specialized, bridging the gap between static pretrained checkpoints and evolving data distributions.
A quick note on terminology
Continual pretraining is often conflated with continual learning, but the two serve different purposes. Continual learning, in the broader machine learning literature, refers to training a model across a sequence of tasks or data distributions in a way that prevents catastrophic forgetting of previously learned tasks or information. In contrast, continual pretraining, simply extends the pretraining phase using the same objective as the original pretraining on new datasets.
| Aspect | Continual Pretraining | Continual Learning |
| Goal | Update a language model with new or domain-specific data | Learn new tasks without forgetting old ones |
| Objective | Same as original | Varies by task |
| Data | Unlabeled text | Labeled, task-specific datasets |
| Structure | No task boundaries | Sequence of distinct tasks |
| Catastrophic Forgetting | Possible with domain shift | Core challenge |
| Examples | BioBERT, GPT-3.5 updates, LLaMA-2 | Multi-task NLP systems, lifelong QA models |
Additionally, the boundary between continual pretraining and fine-tuning can get blurry. Again, the main differentiator here is that continual learning extends the original pretraining objective on large-scale unlabeled data and is a much longer process than fine-tuning.
| Technique | Typical Input | Purpose | Scope |
| Continual Pretraining | Unlabeled corpora | Expand model knowledge or adapt to domain | Broad/general |
| Fine-tuning | Labeled or formatted text | Specialize behavior or align to preference | Task or domain-specific |
Reinforcement Pretraining
Historically, reinforcement learning (RL) in language modeling was primarily reserved for post-training alignment phases. However, recent work explores incorporating RL directly into the pretraining stage itself, replacing the traditional maximum log likelihood (MLL) approach.
In 2025, researchers from Microsoft introduced Reinforcement Pre-Training (RPT), which reframes the conventional next-token prediction task as a sequential decision-making problem. Under RPT, the language model functions as an RL agent interacting with a textual environment, learning through explicit reward-based feedback. Instead of prediction the next token solely by mimicking static training data (as in traditional maximum likelihood approaches), the model makes predictions and receives rewards directly based on the correctness of these predictions.
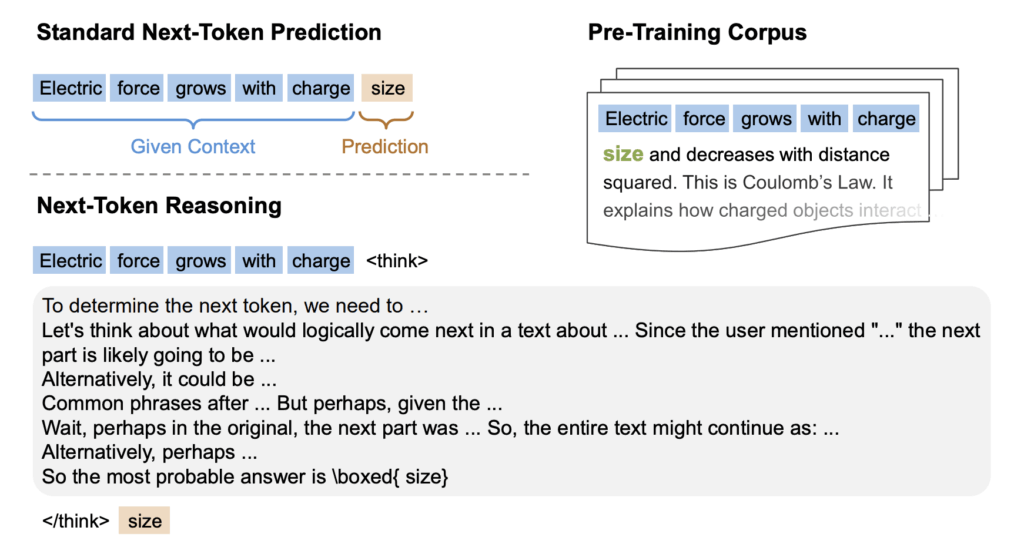
A critical advantage of RPT is that is remains entirely self-supervised. It leverages unlabeled text directly as its reward signal, assigning positive rewards when the model’s predictions match the actual tokens in the training corpus. This transforms massive unlabeled datasets into large-scale RL environments without requiring costly human annotations or demonstrations typically associated with reinforcement learning.
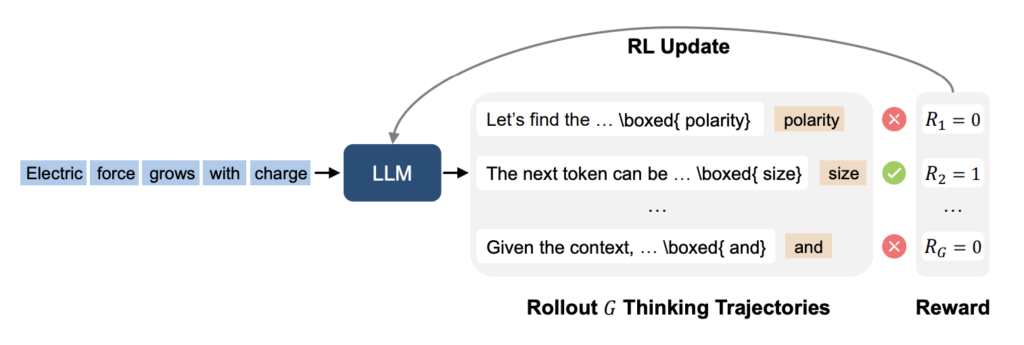
What sets RPT apart from conventional methods is its integration of internal deliberation before token prediction. Rather than directly outputting a token, the model first generates a latent “chain-of-thought prompting” rationale to justify its token choice. The pair of the rationale and the final token serves as the model’s “action.” While only the token prediction receives a direct reward based on accuracy, the rationale conditions and guides the this prediction and thus is optimized indirectly through reward maximization. This latent action optimization approach nudges the model towards more systematic reasoning and coherent internal decision-making. Empirically, RPT-trained models exhibit enhanced zero-shot performance on various tasks compared to traditionally pretrained models.
Compared to conventional MLL pretraining, RPT fundamentally shifts the training dynamic. Traditional methods, which use teacher forcing, treat each token prediction independently, creating a passive, offline learning environment.
RPT, in contrast, employs an on-policy reinforcement learning strategy. Here, the model’s previous predictions and internal rationales directly shape subsequent training experiences, promoting active exploration and more effective credit assignment. This active learning loop enables the model to learn dynamically from its own correct and incorrect predictions rather than solely imitating patterns in static datasets.
Ultimately, RPT represents a significant innovation in scalable LLM training. By integrating RL directly into pretraining, RPT enhances language modeling performance, particularly on challenging, high-entropy tokens, and creates a training framework inherently aligned with desired reasoning and prediction behaviors.
The Future of Pretraining
Understanding pretraining is fundamental to grasping how modern LLMs achieve their remarkable capabilities, from general language understanding to emergent behaviors like reasoning and instruction-following. As we’ve explored, what began with straightforward next-token prediction on raw textual data has evolved into a diverse landscape of methods, including instruction-augmented pretraining, multi-phase curricula, continual training approaches, and innovative frameworks such as reinforcement pretraining.
Each new technique addresses unique challenges– improving alignment, refining performance, adapting to evolving knowledge, and enhancing generalizability across tasks and domains. Yet, despite rapid innovation, the foundational principle remains consistent: pretraining shapes the core language competencies and world knowledge of the model.
Looking ahead, the pretraining stage is likely to continue diversifying and adapting. As researchers further understand the nuanced interplay between data selection, model architecture, training objectives, and computational efficiency, new paradigms will inevitably emerge. Nevertheless, the practical guideposts established by ULMFiT, InstructGPT, and their successors will remain crucial reference points for navigating this complex, dynamic landscape.
