Using AI development tools at scale comes with real overhead for every engineer. It’s an additional cost layered on top of the team, and while the productivity gains usually make it worth it, the real question becomes how that spend maps to actual output.
In other words: if we spend X more on AI development, do we actually get K·X more productivity back?
Engineering productivity has always been hard to quantify at a high level. But you don’t need a perfect metric to debug specific problems in a workflow. If AI spend is climbing while issues are getting solved at roughly the same rate and code output isn’t really changing, it’s fair to ask whether that extra spend is doing anything useful.
We saw exactly this pattern over a three-month period. AI costs kept going up, but it didn’t feel like we were moving faster.
💡 The internal coding agent cost optimization exercise described in this post led us to create Cost Intelligence to help fellow engineers write more code and spend less. Cost Intelligence finds token waste and configuration inefficiencies in Claude Code and Codex and fixes them automatically at both the individual and team levels.
When we dug into the data, one thing stood out immediately: cache reads were by far our biggest expense. Normally, that’s a good sign—it means you’re reusing context efficiently—but the magnitude was a red flag.
So we went a level deeper and reviewed the transcripts themselves. What we found were contexts packed with rules, Model Context Protocol (MCP) configs, long conversation histories, and accumulated guidance that often had nothing to do with the task at hand anymore.
More broadly, it became obvious that AI development configuration starts to accumulate its own kind of tech debt.
Rules grow organically. Bits of intuition get encoded into prompts. A developer tells the IDE “Don’t make that mistake again,” and now that instruction lives forever. A useful tool gets enabled and never turned off. None of this is wrong—it’s how people naturally work—but over time, you end up paying (in latency, correctness, and tokens) for context that isn’t directly contributing to the work you’re trying to deliver.
Like any good engineering team would, we decided to refactor it.
The fixes were straightforward:
- Standardize AI development configuration so it stays DRY across IDEs
- Make rule loading deterministic and minimal, moving heavier guidance into on-demand skills
- Tighten the development loop so context stays clean
Agent Interoperability
One of the early mistakes it’s easy to make with AI development tools is treating your IDE configuration as something tied to a specific product. It works fine at first until different engineers prefer different tools, or a new “next big thing” comes along.
In practice, engineers should be able to choose the AI tooling that fits their workflow without the team having to maintain parallel configuration stacks. And when better tools show up (which they will), switching shouldn’t mean rewriting your entire AI development setup.
To make that possible, we refactored our AI editor configuration so .agents/ is the single source of truth, then added automation to sync it into editor-specific formats:
make cursorto keep Cursor alignedmake claudeto generate Claude Code–friendly versions (including format conversions)- Conversion scripts to handle frontmatter and MCP differences
- A single consolidated
.agents/mcp.jsonto keep tool configuration consistent across environments
None of this is flashy, but it matters. Once you have multiple IDEs in play, “almost the same rules in two places” becomes a constant tax on the team. Centralizing configuration made it simple for us to stay up to date with the industry without fragmenting our workflow or duplicating effort every time a new tool gained traction.
Rules to skills
Early on, most AI IDE setups start with a growing set of global rules. It makes sense: you discover things the model should always do (or never do), and you encode that knowledge so it doesn’t have to be relearned every session. Over time, though, that global ruleset becomes the dumping ground for everything: hard invariants, workflow preferences, domain knowledge, and one-off fixes.
Even with careful scoping using globs and file-level targeting, for a mature full-stack codebase the global ruleset still kept growing. Each addition was reasonable on its own, but once a rule made it into the always-on context, it almost never came back out.
Once we picked up rules, we couldn’t put them down.
We refactored that model into a clearer separation:
- Tiny always-on rules for true invariants only
skills that are loaded when relevant (backend, frontend, SDK, docs, local dev, E2E patterns) - Purpose-built subagents for common work modes (planner, test runner, code reviewer, build fixer, and similar tasks)
The measurable outcome was simple: the “always-loaded” ruleset essentially disappeared. What used to be a large, permanent block of context became a small set of hard constraints, while broader guidance moved into explicitly pullable skills and focused AI agents.
More importantly, agent behavior improved. With fewer always-available actions and less persistent instruction noise, tool selection became more reliable and outputs became tighter. In practice, smaller and more constrained context consistently outperformed broad, do-everything prompts.
Fewer tools and targeted guidance turned out to be smarter than throwing everything at the model at once.
Changing How We Work
The repo changes reduced baseline overhead. The workflow changes reduced prompt drift. We learned pretty quickly that if you keep working the same way, the agent will happily absorb whatever context you give it, and long sessions naturally turn into a junk drawer of half-relevant state.
So we got more deliberate about the loop.
Rapid Loop: Plan → Execute → Commit/Compact
We switched to a cadence that’s boring on purpose:
- Plan a bounded chunk of work with concrete acceptance criteria
- Execute with minimal intervention
- Evaluate with tests when possible
- Commit + compact/reset and move on
The biggest shift wasn’t in execution; it was in planning. We started iterating on the plan more than we iterated on the code produced from the plan. If the plan is vague, the agent will wander. If the plan is tight and scoped properly, execution becomes almost mechanical.
A good plan should make follow-through obvious. When we got that right, the agent didn’t need constant steering and the diffs got smaller and cleaner.
Long, continuous sessions are where context poisoning shows up: stale intent, partially relevant rules, tool sprawl, and “helpful” history that keeps getting dragged forward even when it no longer applies. Compaction should be something you run intentionally. If you take one thing away from this workflow, it’s commit and compact.
Tests as the Default Evaluation Language
We also pushed hard on LLM evaluation. Agents perform better when success is machine-checkable. While test-driven development can be controversial for humans, it turns out to be extremely effective for AI-assisted development, not as a design philosophy, but as a communication protocol.
Writing tests up front gives the agent concrete acceptance criteria instead of vague intent. That one shift, treating tests as the primary evaluation mechanism, made outputs tighter, reduced back-and-forth, and took the human further out of the loop when it isn’t necessary.
Results: Before vs. After the Refactor
We compared behavior before and after the configuration and workflow changes, focusing on output efficiency rather than raw spend. Output here is a proxy for delivered work—normalizing by it lets us separate productivity from overhead.
To understand what was actually driving the numbers, we paired usage data with direct analysis of agent transcripts in Opik, tracing cost patterns back to specific prompt structures, context buildup, and workflow behaviors.
Each Unit of Generated Work Became Cheaper
We normalized cost by output volume to isolate efficiency from usage. After the refactor, producing the same amount of useful work required materially fewer tokens.
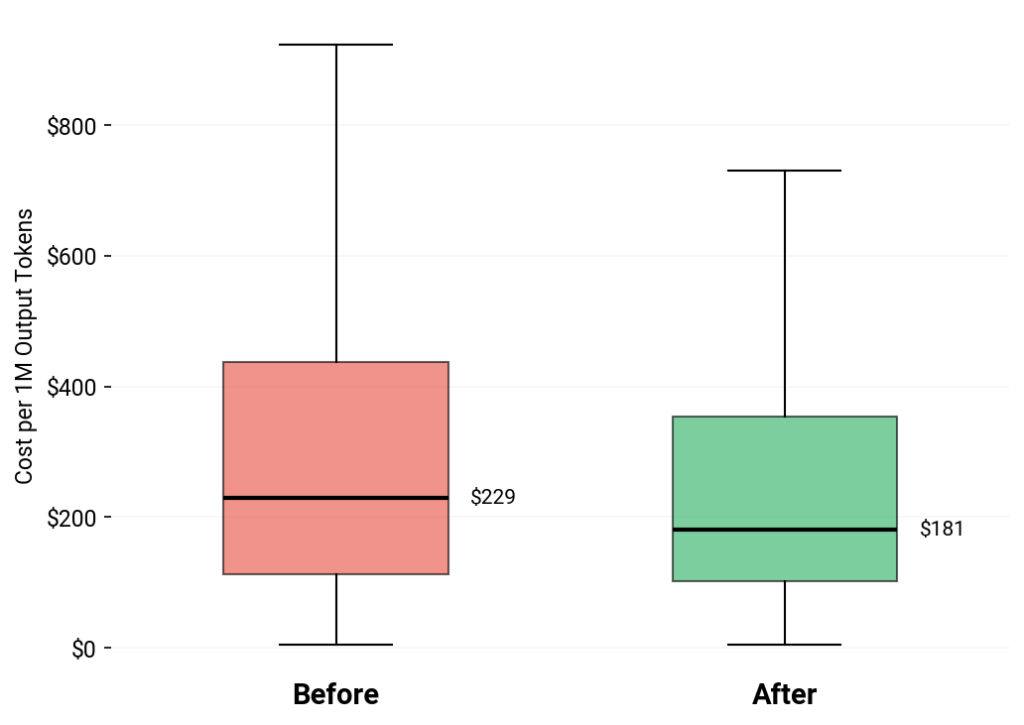
Median output cost dropped from $229 to $181 per million output tokens (roughly a 21% decrease) while the overall distribution tightened as well.
This is the core result: the same level of development output, with meaningfully less overhead per unit of work.
Less Context, More Work
Before the refactor, a large portion of the token budget went to replayed context. Rules, tool schemas, and accumulated history being carried forward on every request.
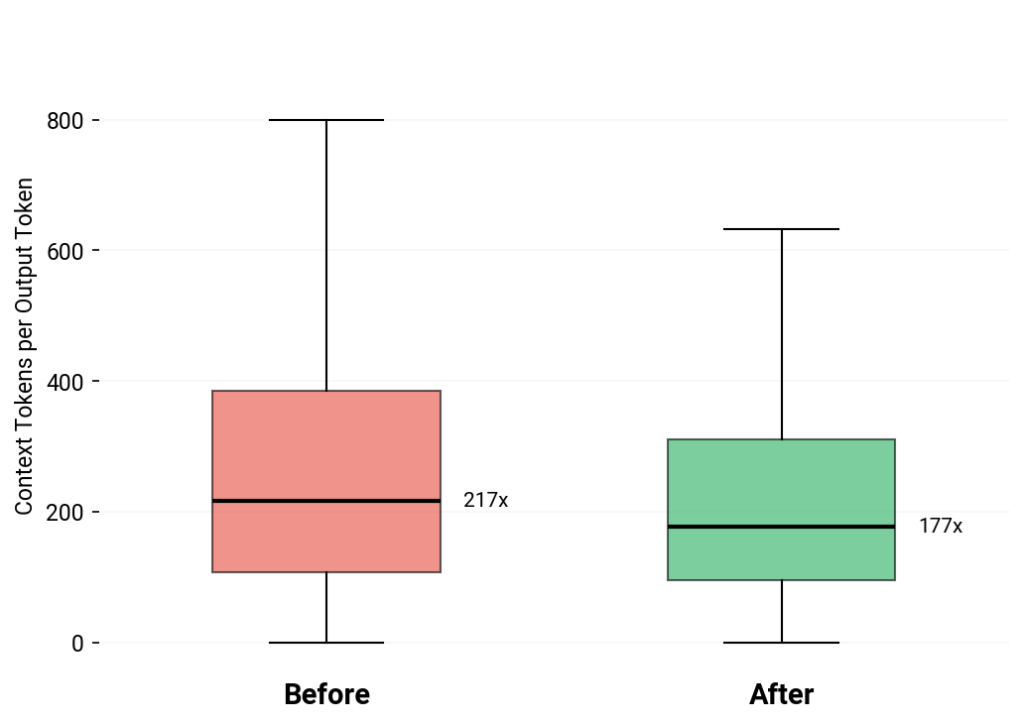
Afterward, a larger share went directly to output.
That shift explains the efficiency gains. We didn’t slow development or generate less work. We removed the prompt overhead that had been quietly compounding over time.
Takeaways
- Smaller always-on context leads directly to less drift and lower cost per unit of work. The gains didn’t come from using AI less—they came from removing entropy from the system.
- Treat AI IDE configuration like real code. Centralize it, refactor it as it grows, and automate synchronization across tools to avoid drift and hidden overhead.
- Keep global rules brutally small. Move domain knowledge, workflows, and guidance into explicit on-demand skills instead of permanent context.
- Prefer purpose-built subagents over a single agent with every tool enabled. Fewer actions consistently produce more reliable behavior.
- Spend more time tightening the plan than iterating on the code that comes out of it. A good plan makes execution almost mechanical.
- Use tests as the default evaluation mechanism for agents. Machine-checkable success shortens loops and reduces unnecessary output.
- Run short, bounded cycles: plan, execute, evaluate, then commit and compact intentionally. Long-running sessions are where drift and context bloat appear.
