Reinforcement learning in AI is a fascinating area of study that has garnered considerable interest in recent years. It simulates human-like learning processes to help the agent understand and adapt to its surroundings, making it a valuable tool in AI. Reinforcement learning has numerous applications in AI, including developing autonomous robots, self-driving cars, gaming, and more. Let’s learn more about reinforcement learning, how it works, and ways to implement it.
What is Reinforcement Learning in AI?
Reinforcement learning is a machine learning technique that enables an algorithm or agent to learn and improve its performance over time by receiving feedback as rewards or punishments. It is based on trial and error, where the agent learns by interacting with its environment and receiving feedback on its actions. The agent’s objective is to maximize its long-term rewards by taking the optimal course of action in each situation.
To achieve this objective, designers assign positive and negative values to desired and undesired behaviors. The agent then learns to avoid the negative and seek the positive, which trains it to make better decisions over time.
How Does Reinforcement Learning in AI Work?
The reinforcement learning process can be broken down into the following steps, as illustrated in Figure-1:
- The agent observes the current state of the environment.
- The agent selects an action to perform based on the current state.
- The environment transitions to a new state based on the action performed by the agent.
- The agent receives a reward or punishment based on the new state of the environment.
- The agent updates its knowledge about the optimal action in a similar future state based on the reward or punishment received.
- The agent repeats the above steps until it has learned how to behave optimally in the environment.
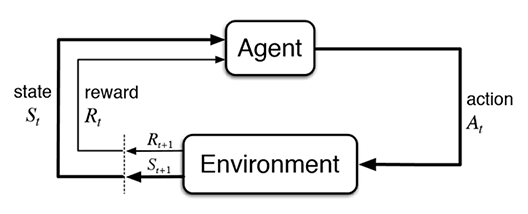
Figure: Reinforcement learning block diagram
In reinforcement learning, the goal is not to explicitly tell the agent what actions to take in every situation but to allow it to learn from experience. Using trial and error, the agent can learn how to behave optimally in an environment, even in complex and dynamic situations.
The Bellman equation is a fundamental concept in reinforcement learning crucial in calculating the expected long-term rewards for each action the agent takes. The Bellman equation represents a recursive relationship between the expected reward of the current state-action pair and the expected reward of the next state-action pair. It is used to estimate the optimal action-value function, which is the expected long-term reward of taking a particular action in a specific state and following the optimal policy afterward.
The Bellman equation can be expressed as follows:
Q(s, a) = R(s, a) + γ * Σp(s’,r) * max Q(s’,a’)
Where:
- Q(s, a) is the expected long-term reward of taking action a in state s.
- R(s, a) is the immediate reward for taking action a in state s.
- γ is the discount factor that determines the importance of future rewards relative to immediate rewards.
- Σp(s’,r) is the probability of transitioning to the next state s’ and receiving reward r.
- max Q(s’,a’) is the maximum expected long-term reward of all possible actions in the next state s’.
The agent uses this equation to estimate the optimal Q-value for each state-action pair based on the current estimates and new experiences gained through interactions with the environment.
Ways to Implement Reinforcement Learning in AI
There are different ways to implement reinforcement learning, including value-based, policy-based, and model-based approaches.
- Value-based: In this approach, the agent learns to optimize an arbitrary value function involved in learning.
- Policy-based: This approach aims to maximize the system reward by employing deterministic policies, strategies, and techniques.
- Model-based: This technique involves creating a virtual model that the agent explores to learn its environment.
Common Reinforcement Learning Algorithms
Standard reinforcement learning algorithms include Q-learning, SARSA, and Deep Q-networks (DQN).
1. Q-learning
Q-learning is an algorithm that learns from random actions (greedy policy). It tries to find the next best action to maximize the reward randomly. The “Q” in Q-learning refers to the quality of activities throughout the process.
- Pros:
- Simple to implement and understand
- Guarantees to converge to an optimal policy under certain conditions
- Can handle large state-action spaces
- Cons:
- It can take a long time to converge, especially in large state-action spaces
- It requires a lot of exploration to learn optimal policy, which can be time-consuming
- It may overestimate Q-values in certain situations, which can lead to suboptimal policies
2. SARSA
SARSA means State-Action-Reward-State-Action. Unlike Q-learning, the maximum reward for the next state is not necessarily used for updating the Q-values. Instead, a new action, and therefore reward, is selected using the same policy that determined the original action.
- Pros:
- It works well for environments with stochastic transitions or uncertain rewards
- It can learn policies that are optimal for a specific exploration strategy
- It can handle large state-action spaces
- Cons:
- It can be slow to converge, especially in large state-action spaces
- It can be sensitive to the exploration strategy used
- It may not converge to an optimal policy in all cases
3. Deep Q-networks
As the name suggests, DQN is Q-learning using neural networks. This algorithm combines neural networks with reinforcement learning techniques to achieve improved performance.
- Pros:
- It can learn good policies in complex, high-dimensional environments
- It can handle large state-action spaces
- It can learn from raw sensory input without requiring feature engineering
- Cons:
- It can be computationally expensive to train, especially for large state-action spaces
- It can suffer from instability during training due to the correlations between samples
- It can be sensitive to the choice of hyperparameters and network architecture.
Reinforcement learning is an exciting study area with enormous potential for advancing AI technology. Its ability to simulate human-like learning processes opens up new possibilities for developing intelligent systems that can learn and adapt to their environments. Understanding the fundamentals of reinforcement learning and its applications can unlock new possibilities for building more innovative and efficient AI systems.
You can try training your own RL Agents using Comet’s integration with Gymnasium, a standard API for single-agent reinforcement learning environments.