Sharing Best Practices Learned from the Best Machine Learning Teams in the World
Developing machine learning models can quickly become a messy, complicated process. As a hobbyist or learner working on a side passion project you often don’t need to worry about tracking or recording your experiments, reproducing results, looking up previous model runs, or collaborating with others. You can get by perfectly fine with scratches of handwritten notes in your Moleskine or notes in the markdown cells of your Jupyter notebooks.
These practices, however, won’t cut it in an enterprise environment.
Whether you want to go pro, level up in your career, or start leading machine learning teams, you’ll need to develop some good habits and understand some best practices.
Developing machine learning models at scale for the enterprise is an iterative, experimental, collaborative process that can become messy and hard to manage.
As the first data scientist in an enterprise, I’ve experienced first hand the pain of not having guidelines and best practices in place for my model development process. I’ve had to go back to the drawing board after the model I deployed started degrading in production. I’ve had to traverse strings of code I wrote, thumb through (physical) notebooks, ctrl-f my way through text files, and go cell surfing through spreadsheets searching for a clues and trying to figure out what me from six months ago was thinking when building that model.
I don’t want you to go through that same headache.
“It’s said that a wise person learns from his mistakes. A wiser one learns from others’ mistakes. But the wisest person of all learns from others’s successes.” — John C. Maxwell
In this blog post, I’ll share some lessons that will help you standardize your experimental process so you can quickly formulate, test, and evaluate hypotheses for your problem statement so that you can build better models, faster.
A preview of what will be discussed in this post:
- An overview of the machine learning model development process.
- Managing your experimental runs like a professional.
- Iterating and experimenting with algorithms.
- Hyperparameter search and fine-tuning.
The machine learning model development process
If you’ve been following along in this series, then you’ve heard me say this at least 42 times: The machine learning lifecycle is iterative and continuous.
Implicit in this continuous process is a feedback loop that will help you improve. That’s because results from later stages in the pipeline are informed by decisions in the earlier stages. But what does that feedback loop look like?
Whether it’s CRISP-DM, OSEMN, or Microsoft’s TDSP, all machine learning lifecycle frames will involve six activities.
First is a process of understanding the business problem or research question and identifying data that is relevant to making progress against that problem.
Second is preparing data through some process of ingesting, integrating, and enriching it. This is usually some combination of data pipelines for ETL processes and feature engineering.
Third is representing the data generating phenomena using statistical and machine learning algorithms by finding a model of best fit.
Fourth is evaluating the model and testing it to make sure that it’s able to generalize to unseen data points.
Fifth is deploying the model as part of some application or larger system.
And sixth is monitoring the performance of that model by measuring and assessing its effectiveness as well as monitoring the statistical properties of the data that is coming into the model.
Then you get to repeat the whole process.
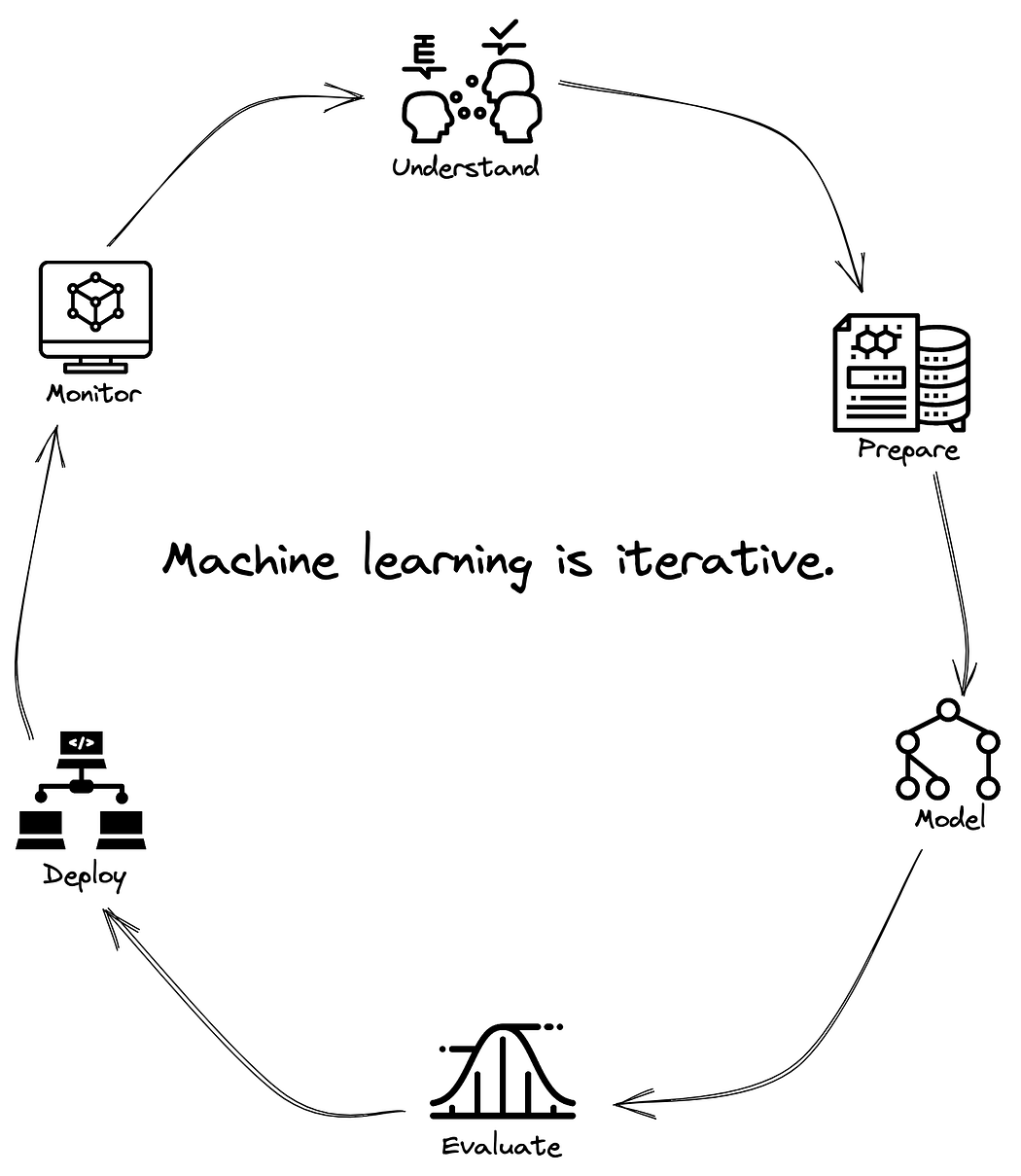
“Because machine learning is such an empirical process, being able to go through this loop many times very quickly is key to improving performance.” — Andrew Ng
I can’t recall exactly where I heard this, but…
If anything is true about the machine learning process, is that it abides by the CACE Principle.
The CACE Principle: Changing Anything Changes Everything. The phenomena by which change anywhere in the machine learning process — especially those changes furthest upstream — will have unanticipated impact on your experiment and results.
Which brings us to our next topic, experiment management.
How to manage your experimental runs like a professional
“When you’re running dozens, hundreds, or maybe even more experiments, it’s easy to forget what experiments you have already run. Having a system for tracking your experiments can help you be more efficient in making the decisions on the data, or the model, or hyperparameters to systematically improve your algorithm’s performance.”
A common saying about machine learning is that it’s when code meets data. A common saying about code is that it’s read more than it’s written. But in machine learning, reading only the code won’t give you the full picture.
Isn’t Git good enough for all that?
Yes, versioning the code is absolutely necessary.
But you’d only have access to the information you care most about if you ran the code from start to finish. That could take hours, days, or weeks.
When running machine learning experiments, you care about much more than just the code. It’s everything beyond the code that’s most interesting: hyperparameters, metrics, predictions, dependencies, system metrics, training artifacts, and more. All of this is what allows you to understand differences in model performance and iterate towards a better model.
What should I be tracking for my machine learning experiments?
Like anything in machine learning, the answer usually depends. I’ll share some advice I learned from the Godfather of Machine Learning himself, Andrew Ng. In his course, Introduction to Machine Learning in Production, Andrew recommends tracking four keys pieces of information.
First, keep track of the algorithm you’re using along with the code. Having this information handy will make it easier to replicate the experiments you ran in the past (and whose details you may have forgotten about). Second, keep track of the artifacts you used during training. Artifacts include: training data, testing data, other models (ex. which version of Word2vec did you use? Did you use a model to generate a feature for your larger model?). Third, track hyperparameters, random seeds, training duration, number of epochs, activation functions, etc. Fourth, save the results from your experiments. This includes metrics like MAE, MSE, F1, Log Loss, etc. That way you have visibility into how each experiment performed.
If you have all of this available along with your code, you don’t need to run the code to find out what happened. It’s all right there for you.
Want to see these concepts in action? Check out our Office Hours Working Sessions on YouTube.
How should I be tracking all of this?
You might start off manually writing everything on post-it notes, in your notebooks, to a text file, or logging all console output to a file.
That’s obviously not an efficient practice and doesn’t lend itself well to scalability and reproducibility. If you’re a little more disciplined, you might use a spreadsheet to track everything, like the one below (which honestly, isn’t that impressive or sophisticated). Keeping track of and managing all this extraneous metadata might seem too tedious, it might feel like it creates more overhead and cognitive overload. You probably feel like you don’t need many of these bits and pieces of information…until you do.
Because the time will come when you go back to that experiment after a week, or a month, or a year, or you want to bring on collaborators, or share your work with somebody else. And when that happens, how is that person (future you, or present day collaborator) supposed figure out the end-to-end process of how the experiment was run?
Checkout the Python quick start guide or the R quick start guide, both will get you set up fast.
Once you’ve got tooling to help track all of your experimental runs, you can start iterating and experimenting with algorithms.
Iterating and experimenting with algorithms
We talked about the importance of baseline models in a previous article.
As a quick recap: you establish a baseline by trying a simple model for your task (it could be simple heuristics, a dummy model, linear or logistic regression) so you can get a sense of whether the problem you’re working on is tractable or not. Once your baseline results are established, it’s time to conduct an initial set of experiments with more complex models.
How complex you get is going to depend on the problem you’re trying to solve, but you might want to try boosted trees, Gaussian Processes, Neural Nets, or any algorithm you think would be applicable. Whichever ones you choose, start with off the shelf configurations for those algorithms. Don’t worry about tuning hyperparameters or applying regularization at this stage.
It may sound counterintuitive, but see if you can build a model that can overfit your training data.
For example, imagine you sampled 1000 examples from your dataset (which is 10% of the total data). First, run your feature engineering pipeline on those samples and try to overfit your model on them. Then, iterate over the different combinations of features and try to identify which are most impactful for driving model performance. Finally, compare training metrics across model types and features to verify which types of models have the capacity to learn from the data at all.
You’re doing this to verify that your training and evaluation setup is working as expected, specifically:
- Is the data being loaded in the correct way for the model to consume?
- Are all the relevant metrics for this modeling task being logged? Do new ones have to be defined?
- Are the splits in the datasets valid? Is there any leakage between the training and validation sets?
- Can the results be reproduced when rerunning the same experiment? Are there any discrepancies caused by incorrectly setting the random seed somewhere?
- Do the label and prediction match up perfectly? Once you’re confident that the training and evaluation framework is trustworthy, you can start slowly ramping up the complexity of the model.
Why does all this matter?
Let’s say you’re working with a Neural Network.
You may want to try to train on a single datapoint, or a single batch. See if you’re able to get an error as close to 0 as possible, then check if the prediction and labels align perfectly. If this isn’t the case, that indicates something’s wrong with your model architecture. You would debug this by logging the weights, gradients, and activations in the model and inspecting whether or not these are changing over the training process.
Once you’re able to find a set of models that are able overfit the training data, you can try regularization approaches to improve the model’s ability to generalize.
For your regularization experiments, investigate the effects of scaling the amount of data on your model. Track how the training and validation metrics for each model type change as more samples are added to the training set. Some examples of regularization include:
- L1 and L2 regularization
- Early Stopping
- Dropout
After this initial set of experiments you should have enough information to identify the most promising algorithms and feature combinations. These initial set of algorithms that will now move onto further development. At this stage, you should have an idea of the types of models that are able to fit your data, the features that work best for each model type, and the effects of scaling the data on each candidate model type.
You’re now ready to start tuning some hyperparameters.
Hyperparameter search and fine-tuning
You don’t want to spend unnecessary time tuning hyperparameters.
A good way to start is by using the sampled dataset to quickly iterate over different hyperparameters configurations. Your results here are highly dependent on whether you can get a representative sample of your dataset. If the data is complex, this can be much harder.
One workaround is to investigate the effects adding more data has on performance of the top N number of hyperparameters (with just the sampled data). You can use the heuristic of compute resources available as a way to determine what the threshold for N should be. To avoid overfitting the sampled dataset, build multiple validation sets by sampling with replacement from the full validation set.
The average of the results from each set is an indicator of the performance of the hyperparameters on the entire validation set.
You want to be methodical when searching your hyperparameter space.
Start simple, using a search algorithm like Random Search. Random Search serves as a solid baseline optimization technique. Depending on the problem you’re working on you may opt to use Bayesian Optimization methods to really fine tune and narrow down your search space. The most efficient search strategy is an iterative approach.
Start with a wide range of values for each hyperparameter, sweeping across a wide search space. You can use discrete values for the parameter options — even if your hyperparameter is a continuous variable (i.e. learning rate, momentum, etc.). It’s much more efficient to narrow down the range of values before trying to search a continuous parameter space.
Once you have a set of hyperparameters that work well with your data, you can fine tune your approach by trying ensembling models together using the top performing models, letting your model train for an extended period of time, or further optimize your feature engineering pipeline.
If you want to see hyperparameter tuning in action using Comet, check out this post:

Conclusion
Machine learning is an iterative process with a lot of moving parts.
Manually tracking the entire process is not only unnecessary — it’s an unreasonably error prone burden. People talk a lot about technical debt in machine learning, and a lot of that high interest comes from tracking. Everything from metrics, dataset distributions, hardware details, etc. It’s in our best interest to automate this process as much as possible.
The machine learning community can benefit from best practices used in traditional software engineering. Leveraging automated tools such as Github, and CI. Making good use of version control pull requests, CI tools and containers to run your experiments are all great lessons we can learn from software engineering.
But that’s not enough for machine learning.
Machine learning is not just when code meets data. It’s when code meets data plus hyperparameters, model architectures, random seeds, compute environments, evaluation metrics, and a whole host of important considerations. But still we can adopt best practices designed to facilitate collaboration and automation of the process.
And my hope with this article is that we’ve done just that: shared best practices that we’ve learned from some of the best machine learning teams in the world.
