Machine Learning Models are adding tremendous value to businesses in different sectors. For example, Zappos is able to save millions of dollars a year because of Machine Learning. Their machine learning model predicts a user’s correct shoe size based upon their previous purchases, this caused a 10% reduction in the number of returned shoes which allowed for significant cost savings for Zappos.
There are many ML teams like the one at Zappos whose goal is to eventually deploy a model in production. To support production grade ML models however requires great coordination at the team or organization level involving stakeholders with varying skill sets. Unlike software deployments , Machine Learning Model deployments in Production are rarely “set and forget”. They need to be continuously monitored and when they start to under-perform or cause issues, teams have to be alerted so they can start debugging and root cause the issue and this might even involve re-training the models..
At Comet we interact with organizations that come in with varying levels of ML maturity. As a result we see some common traits of high performing production focused machine learning teams. These teams often exhibit high levels of maturity in areas around model reproducibility, debugging, visibility, and monitoring.
Reproducibility
Models in production are often stored as a simple file. These files store the weights and architecture of the model, but have almost zero information about the backstory or lineage of a model. When evaluating your organization’s ability to reproduce a model, ask the following questions
- What was the training code used for training this model?
- What specific configuration of hyper-parameters were chosen to train this model?
- What version of the data was used to train this model?
- How long did it take to train the model?
- What were the results of the training run for this model?
By storing all the information needed to re-produce models in a central location, Mature Machine Learning Teams are quickly able to see the entire training lineage of a model, regardless of when and who trained a model. Tracking all the information needed to reproduce a model sets the stage for debugging models.
Debugging
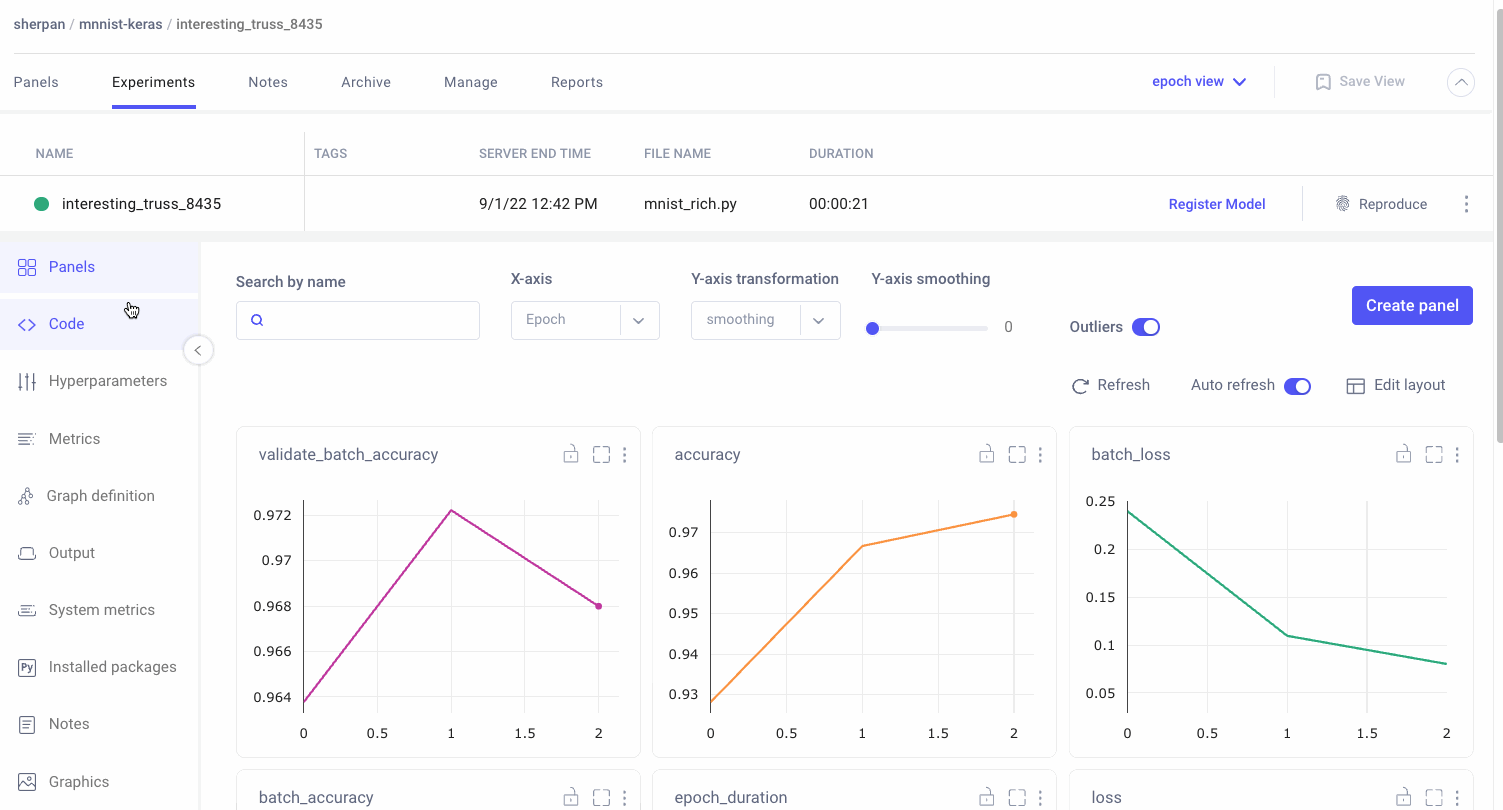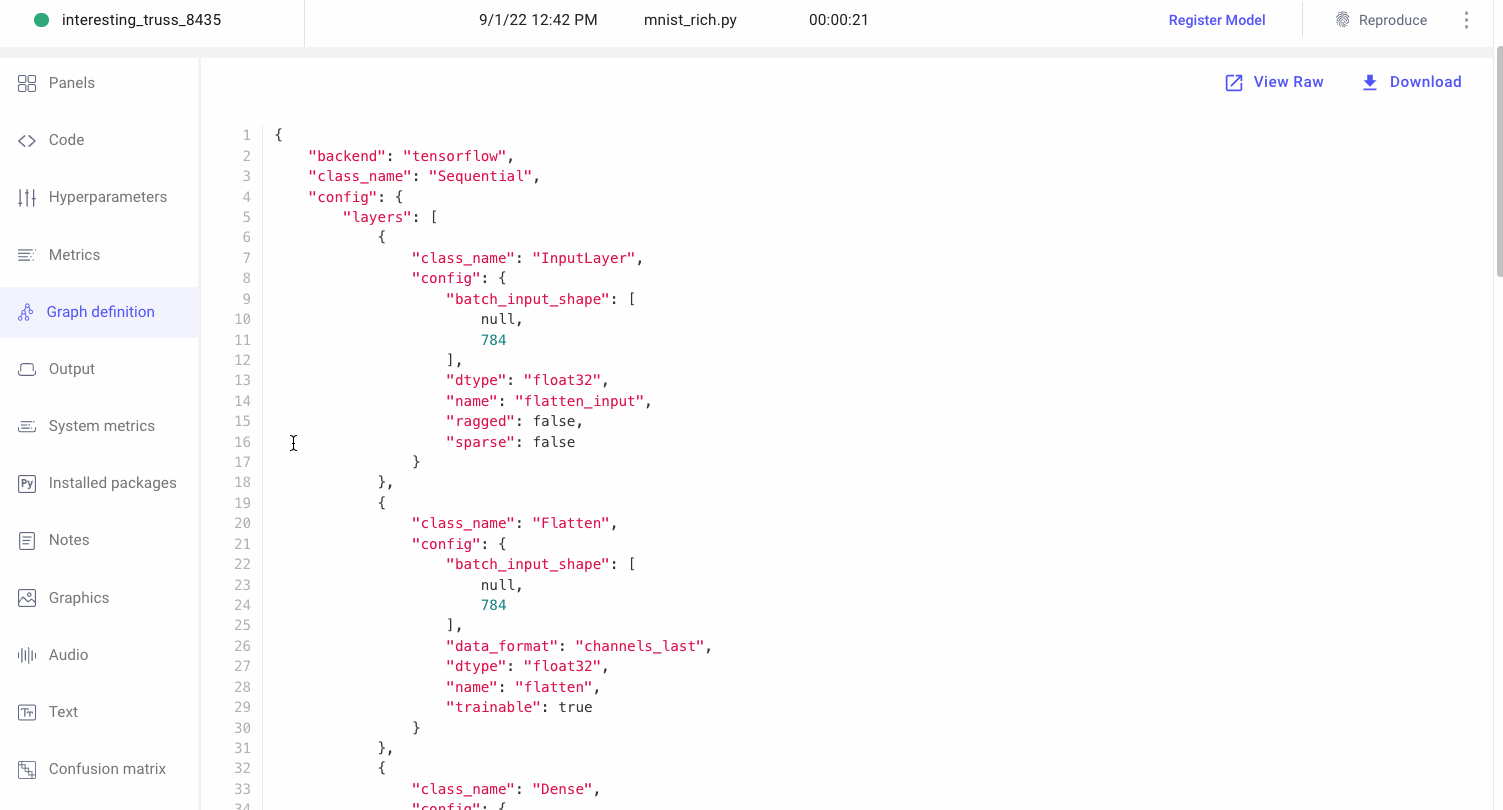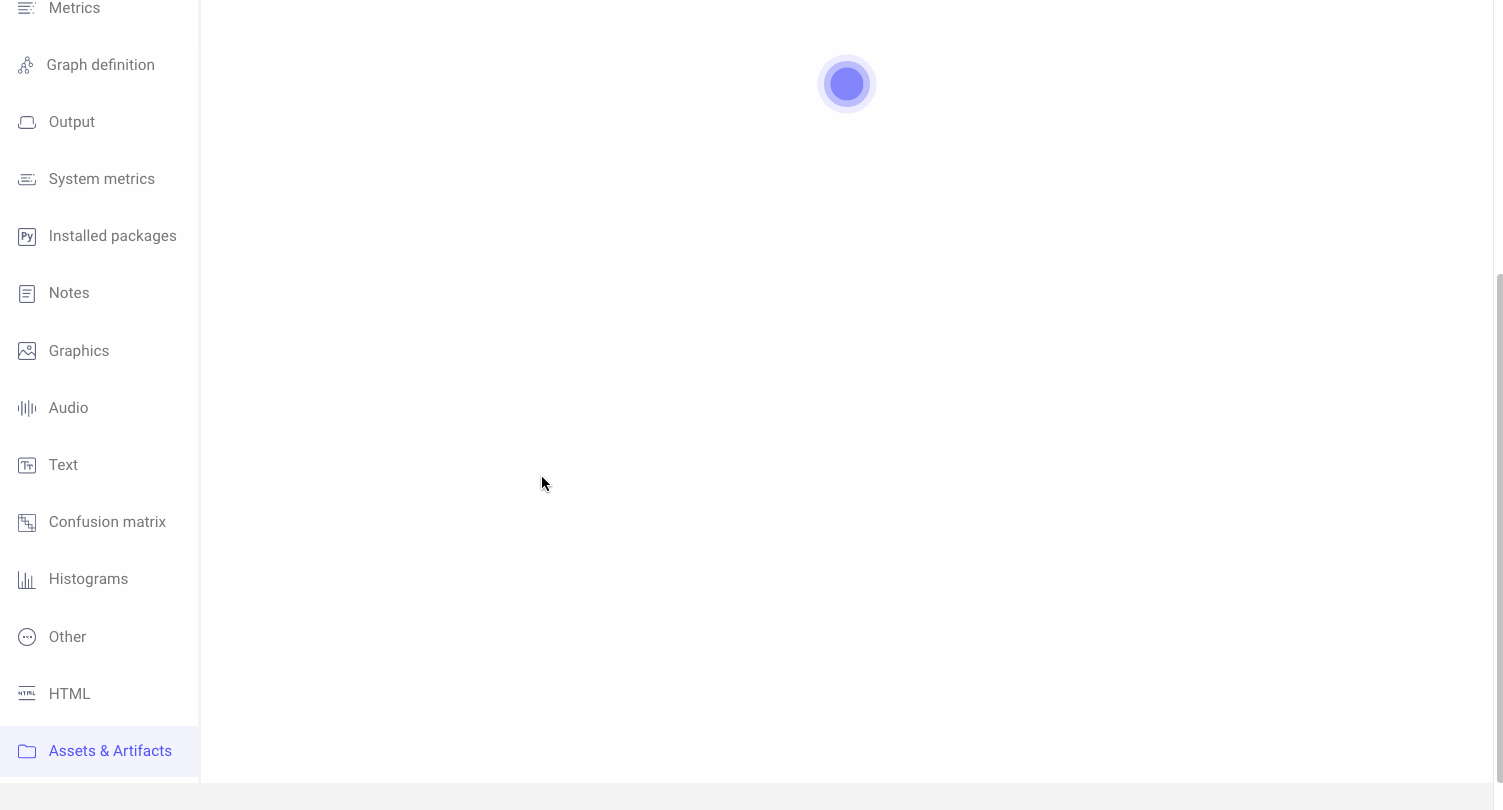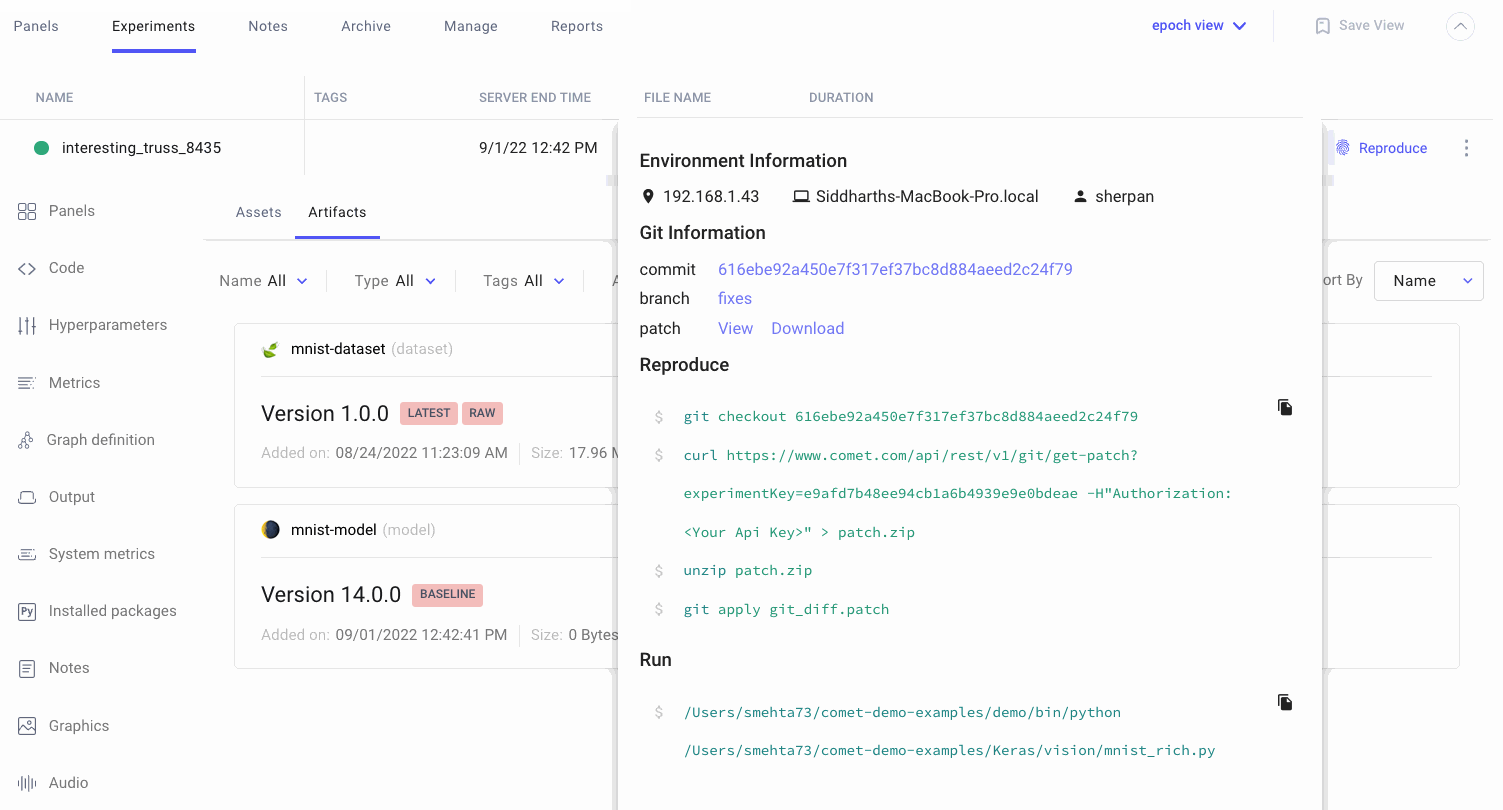
Model Training in an iterative process. Machine Learning Teams are trying out various strategies to improve model performance: different algorithms, model architectures, hyper-parameters, and data augmentation techniques. Teams need to be aware if these strategies are working or not. Since Mature Machine Learning teams are already tracking all the information needed to reproduce a model, they can very easily answer the question of “How does my current training run compare to previous training runs”?
The Debugging Model workflow also extends to the data side of machine learning training. Metrics like loss and accuracy are great for quantifying model performance at a high level. But Mature ML teams also need to know on which specific data samples the model underperforms on. By understanding model failures at the sample level, teams can brainstorm workarounds for when models encounter similar data in production.
Visibility
The Model Training Process is dispersed around a multitude of systems. Data lives on the cloud. The cloud needs to talk to a server which has an army of GPUs for model training. Results are rendered on local laptops for team members. It’s difficult for teams to answer ““who has tried what” for a particular project.
ML teams who are mature in the areas of Reproducibility and Debugging are able to make the Model Training Process transparent and communal. Teams are able to work more efficiently as they aren’t duplicating training runs and are able to communicate results easily. Stakeholders such as engineering managers and project managers can also have insight as to how much the team is spending on training. Compute Resources are not cheap so it’s important to know if teams are going above budget that model performance is improving.
Monitoring
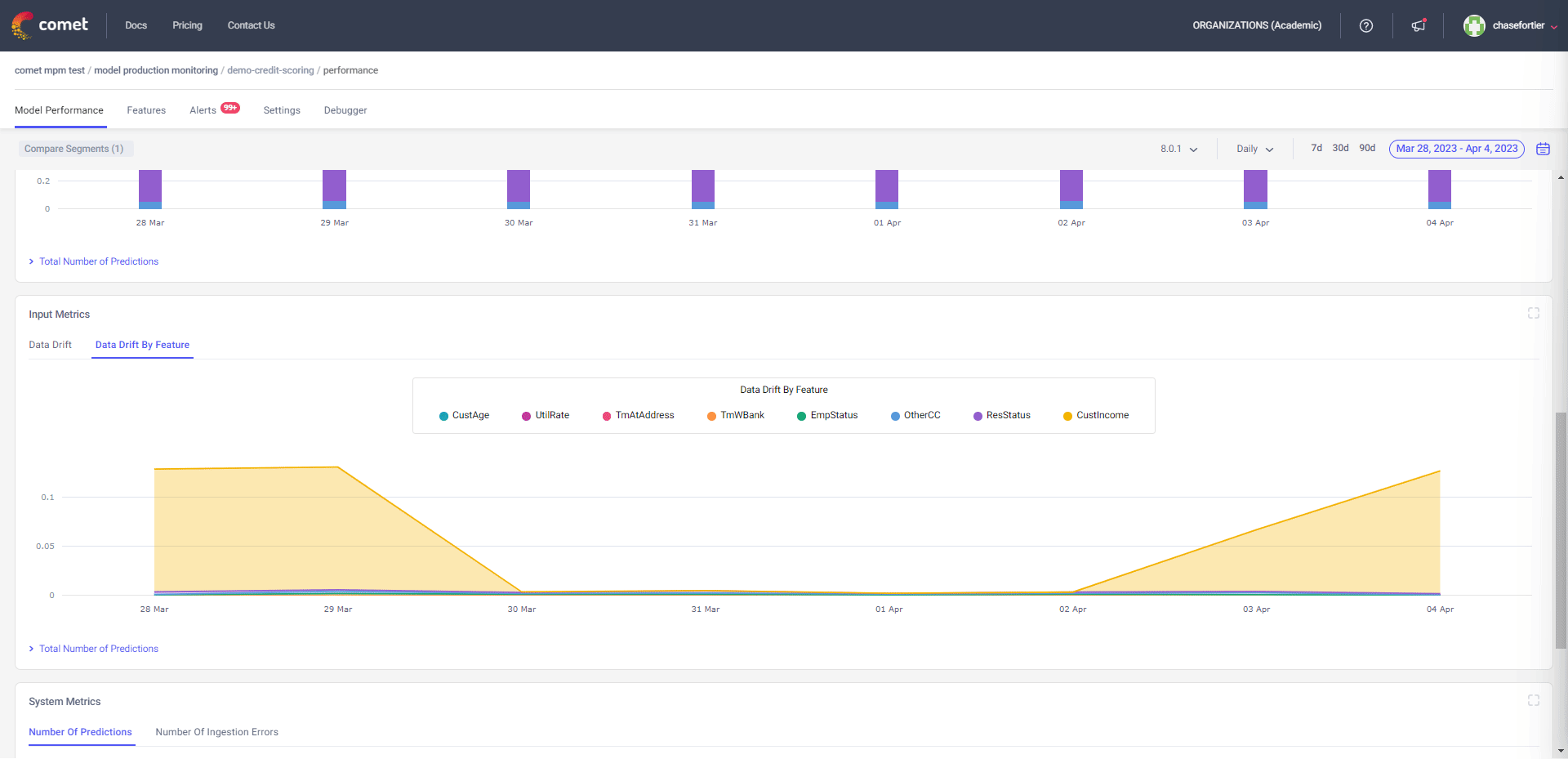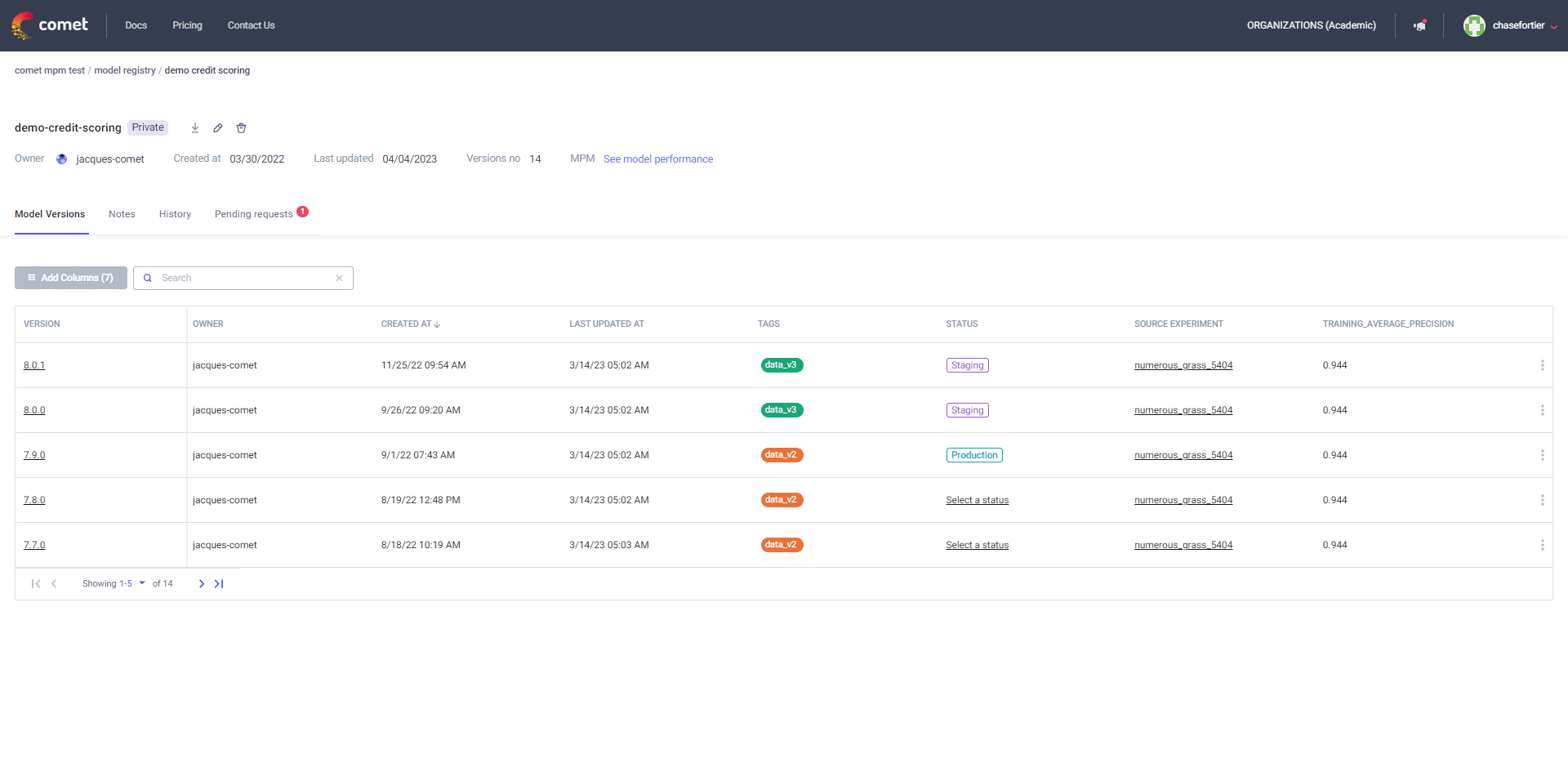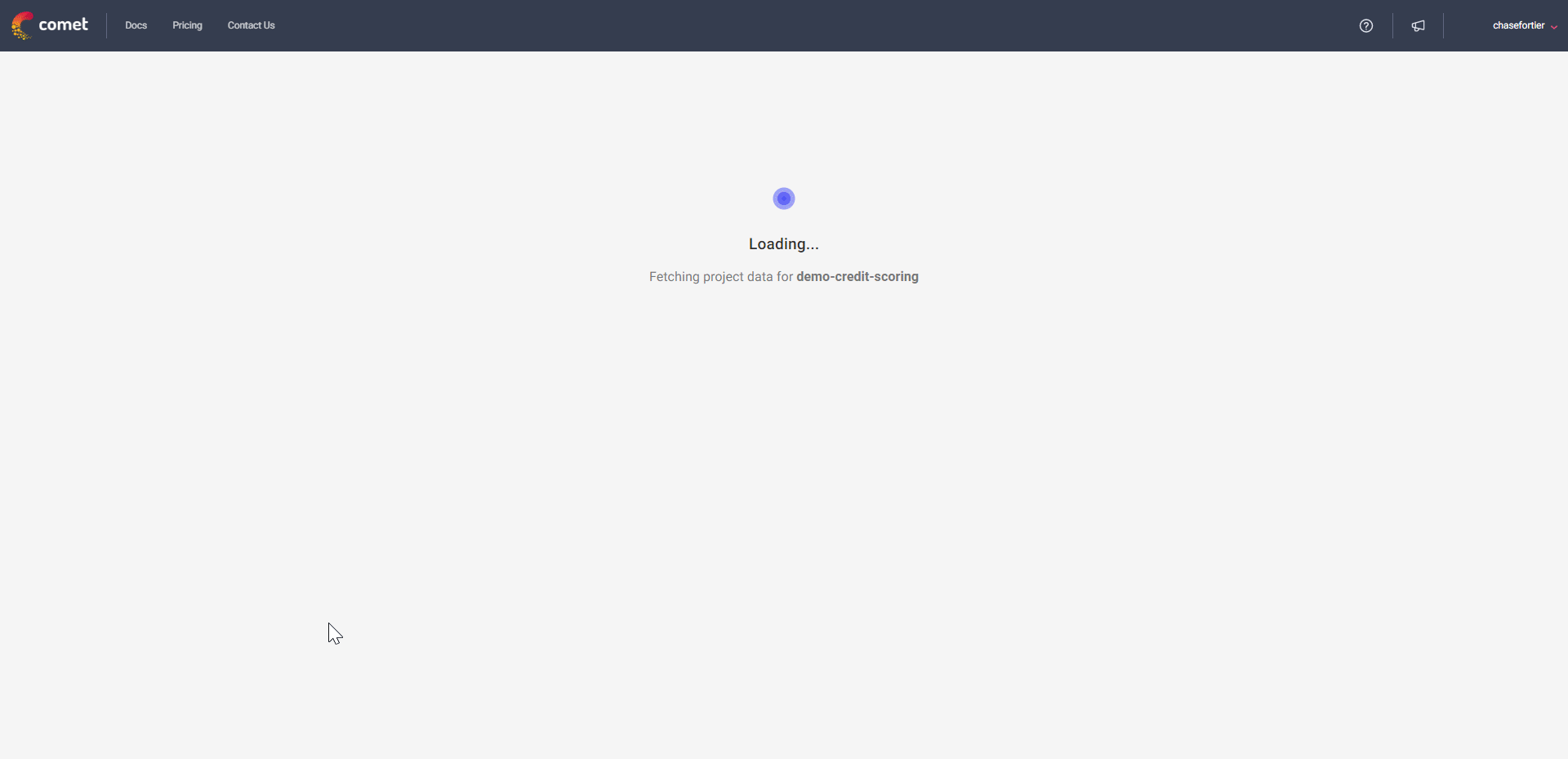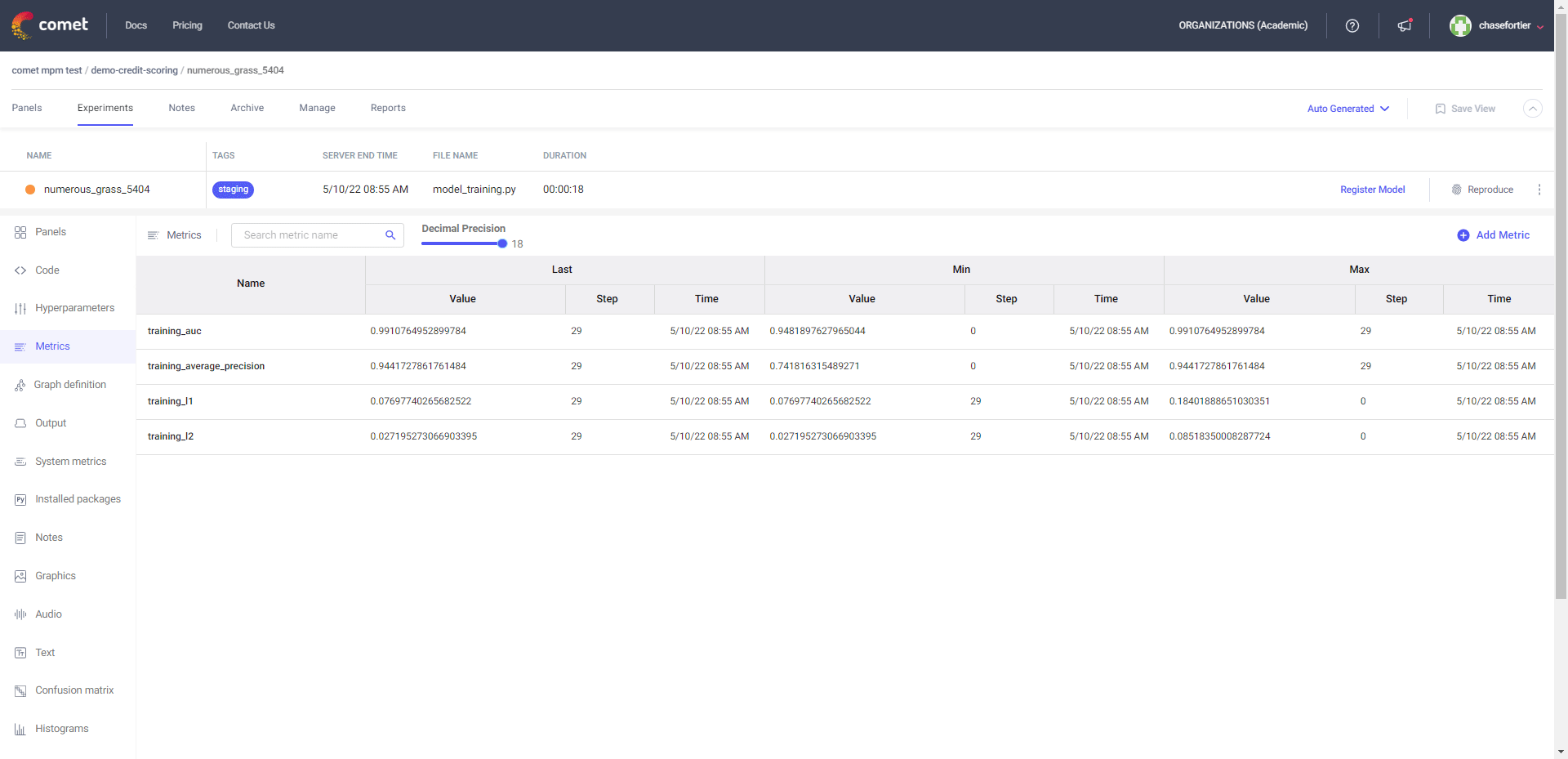
ML Systems in production are dynamic. It’s quite possible that a model in production starts underperforming. This is termed as “model drift” and can happen for a variety reasons. Mature Machine Learning teams are able to detect model drift by monitoring
- Model Output
- Model Output Data Drift
- Input Data Drift
- Input Data Drift By Feature
- Drift Within Subsets of Data
- Distribution
- Missing Values
A Model that is “drifting” in production can have huge consequences and therefore ML Teams must be alerted as soon as possible when incidents like this occur. Mature ML teams are able to quickly hot-fix an updated model into production since they have all the information needed to reproduce and therefore re-train the original model.
Bridging The Gap
It’s quite possible for organizations to be mature in some areas like reproducibility and debugging, but be novices in terms of model visibility and monitoring. So what’s the best and quickest way for ML teams to elevate their ML maturity across the board? Try out a MLOps tool that specializes in all the above in Comet.
Reproducing Models
Comet logs everything you need to reproduce a model such as code, hyperparameters, dataset version. Be-able to reproduce a model training run even if you didn’t commit it to git.
Debugging Models
Create a customizable dashboard to view your model’s performance and compare it to previous runs. Also use Comet to figure out where in your data a model is failing and be able understand why model runs are behaving differently. 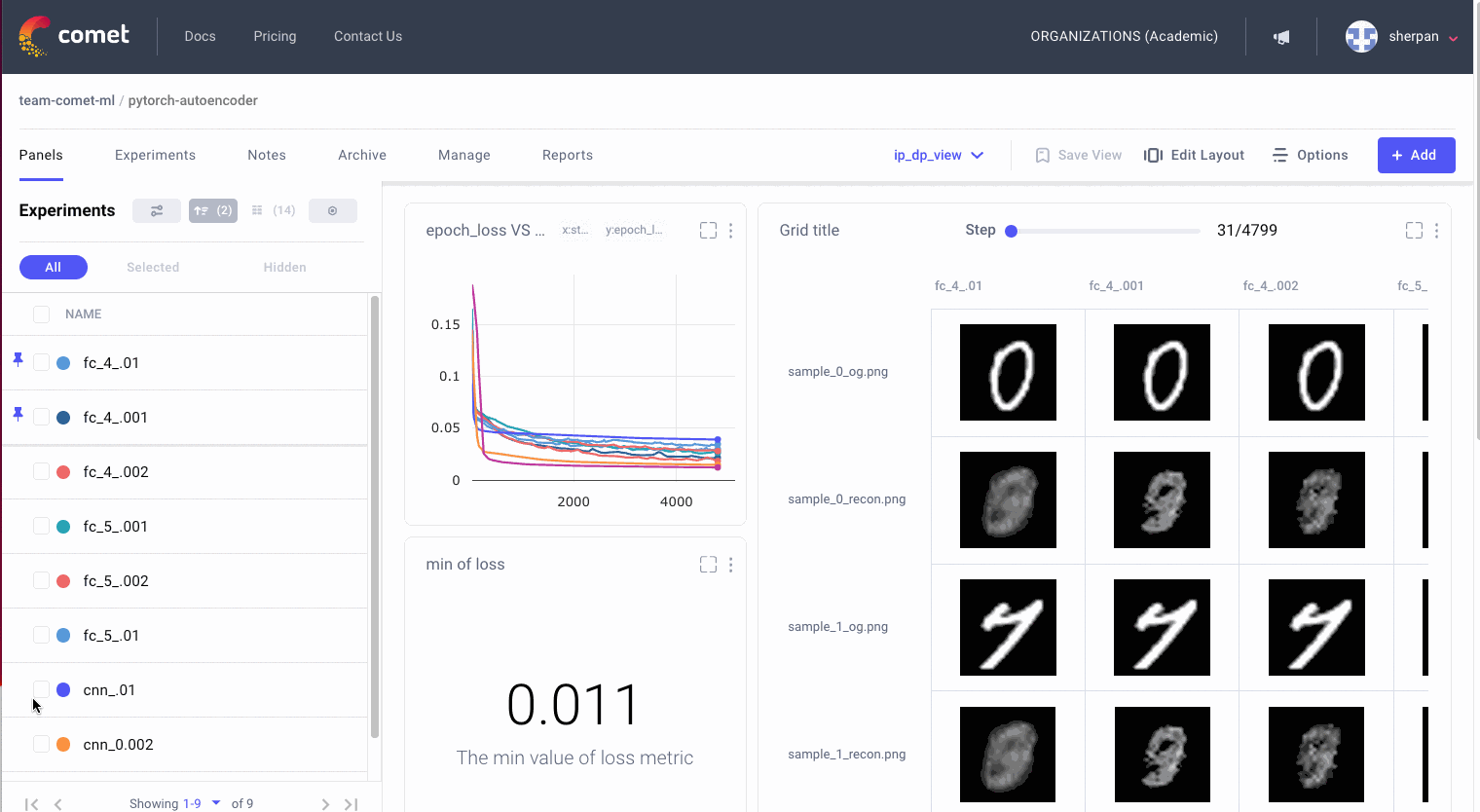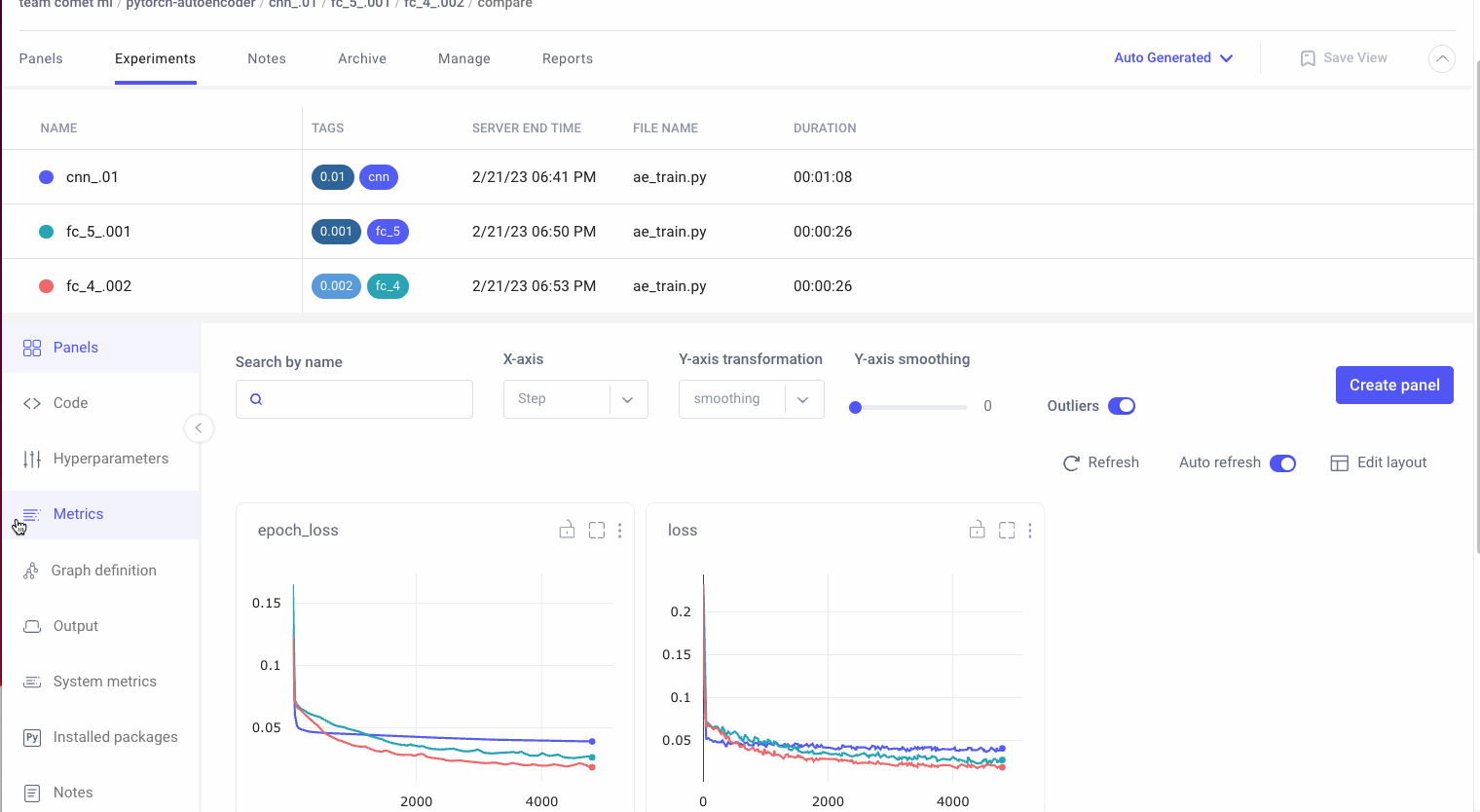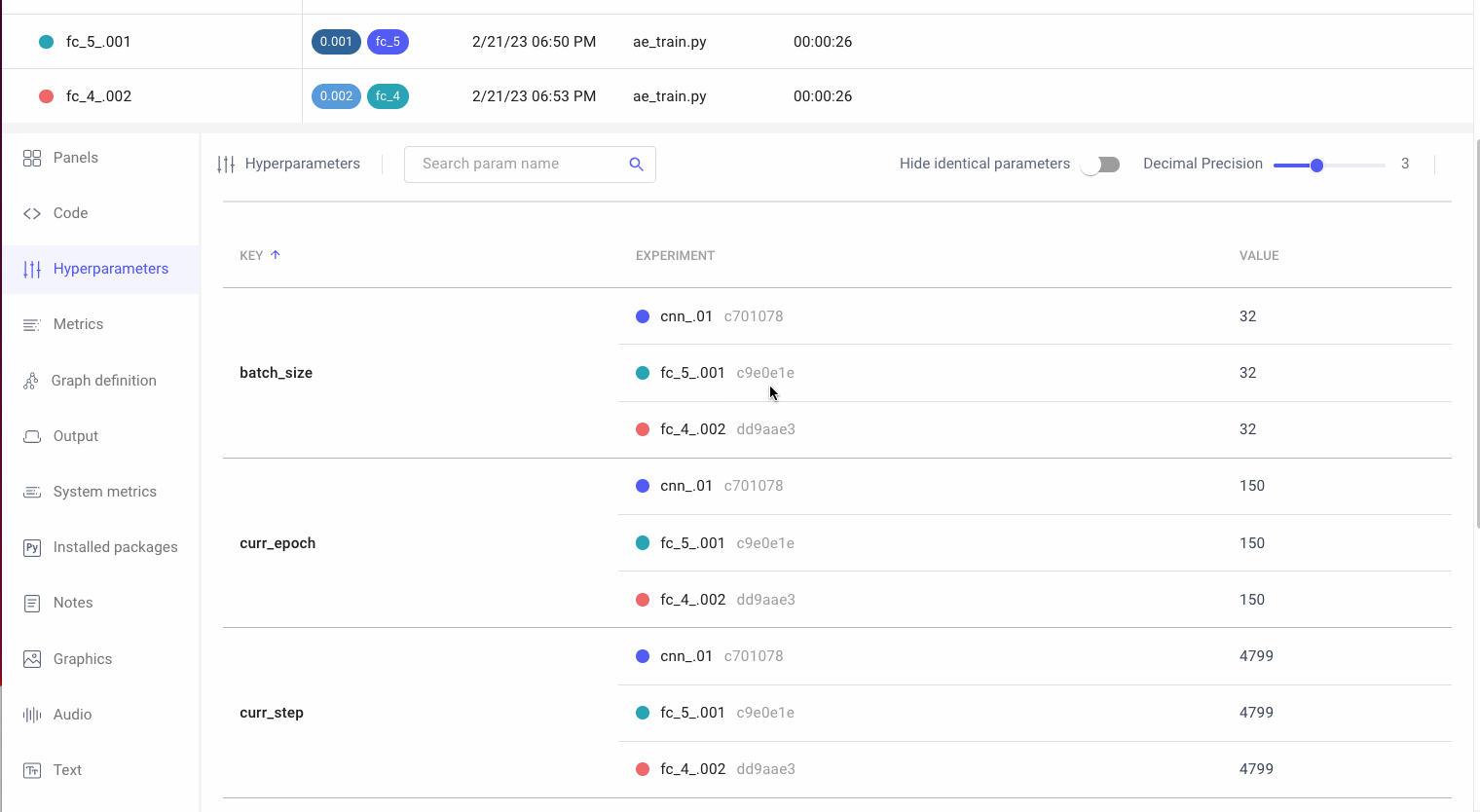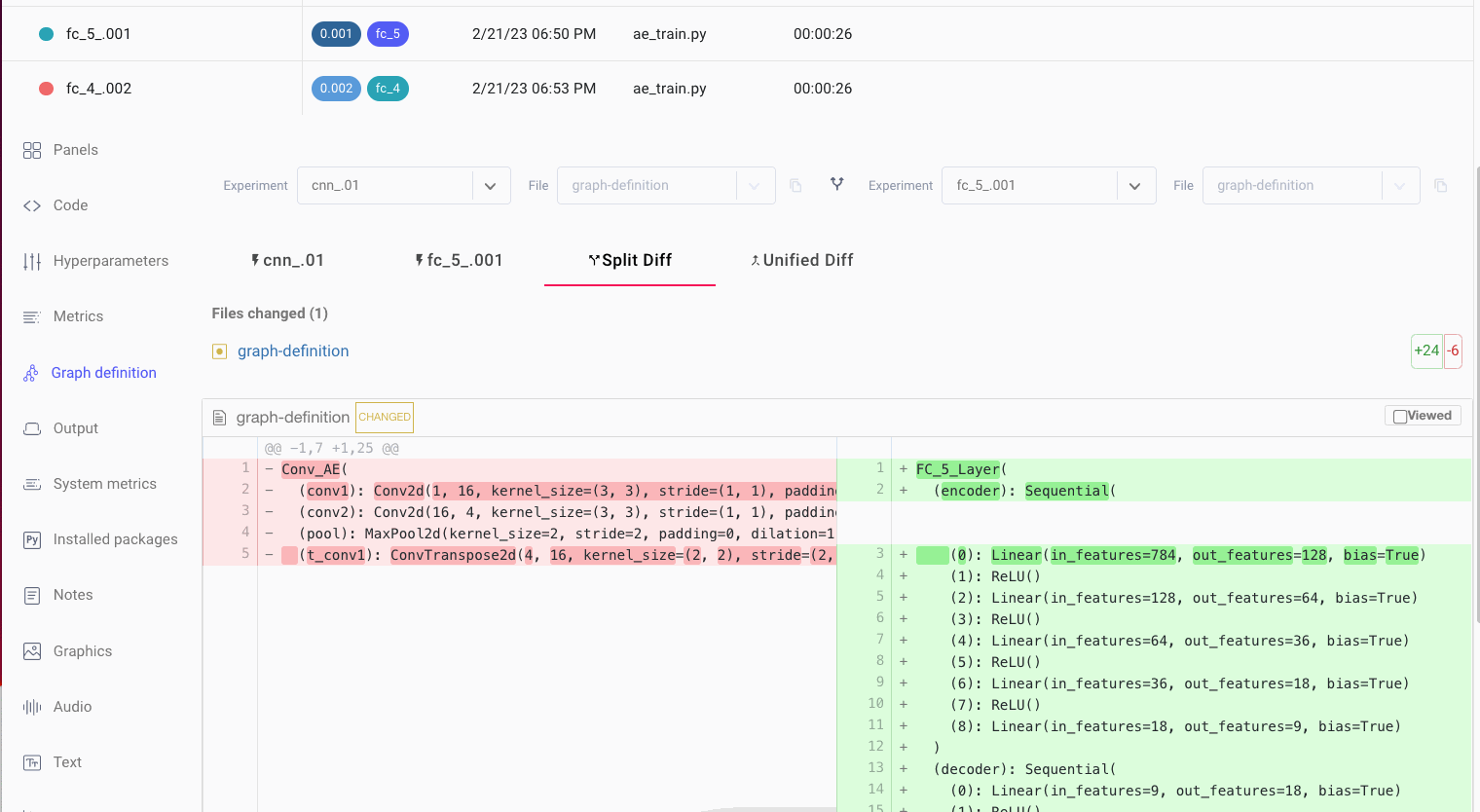
Model Visibility
Comet is the de-facto communication method for many ML teams. Team uses Comet’s dashboards and reports to showcase the current state of a modeling task to a variety of stakeholders. The Model Registry is where production-ready models are stored. The Registry allows for comprehensive Model Governance: see who downloads what version of a model and create a formal approval process from moving a model from “staging” to “production”
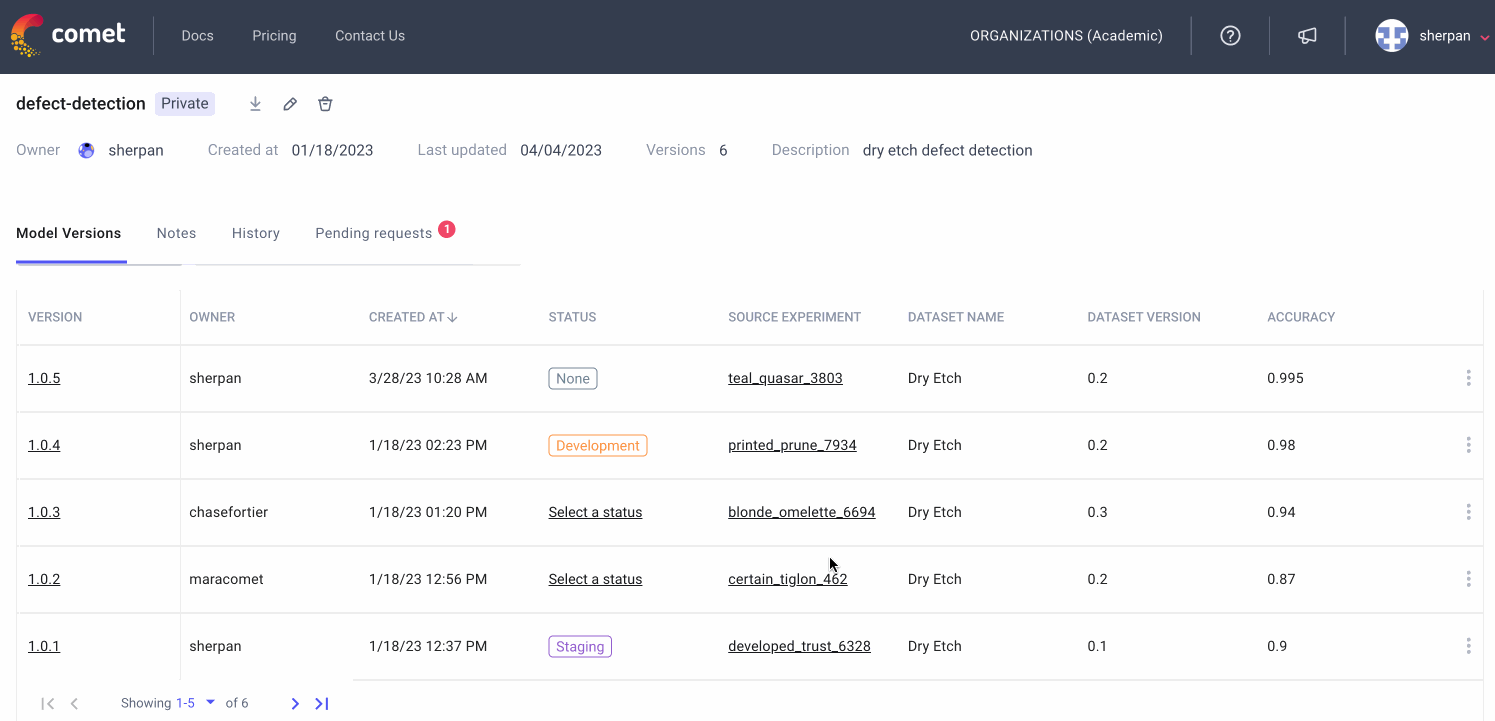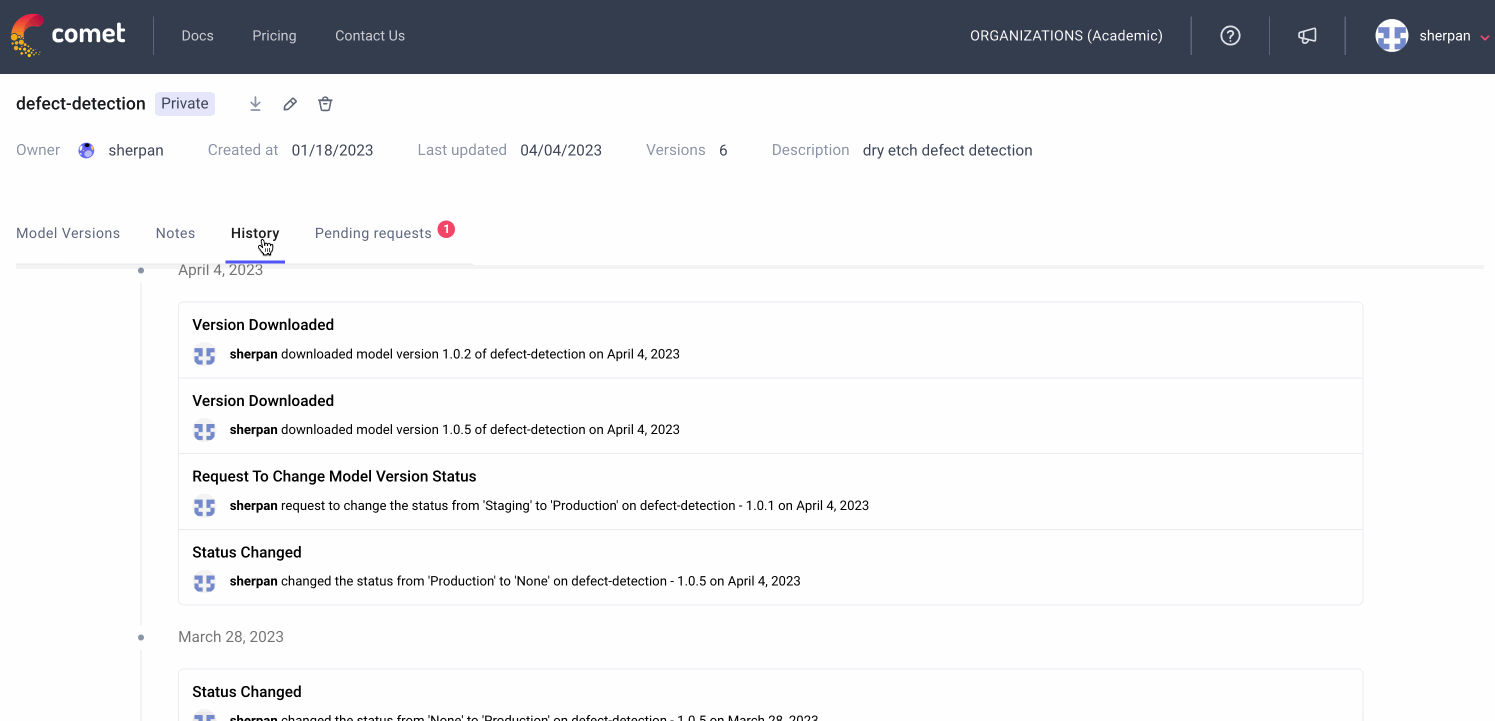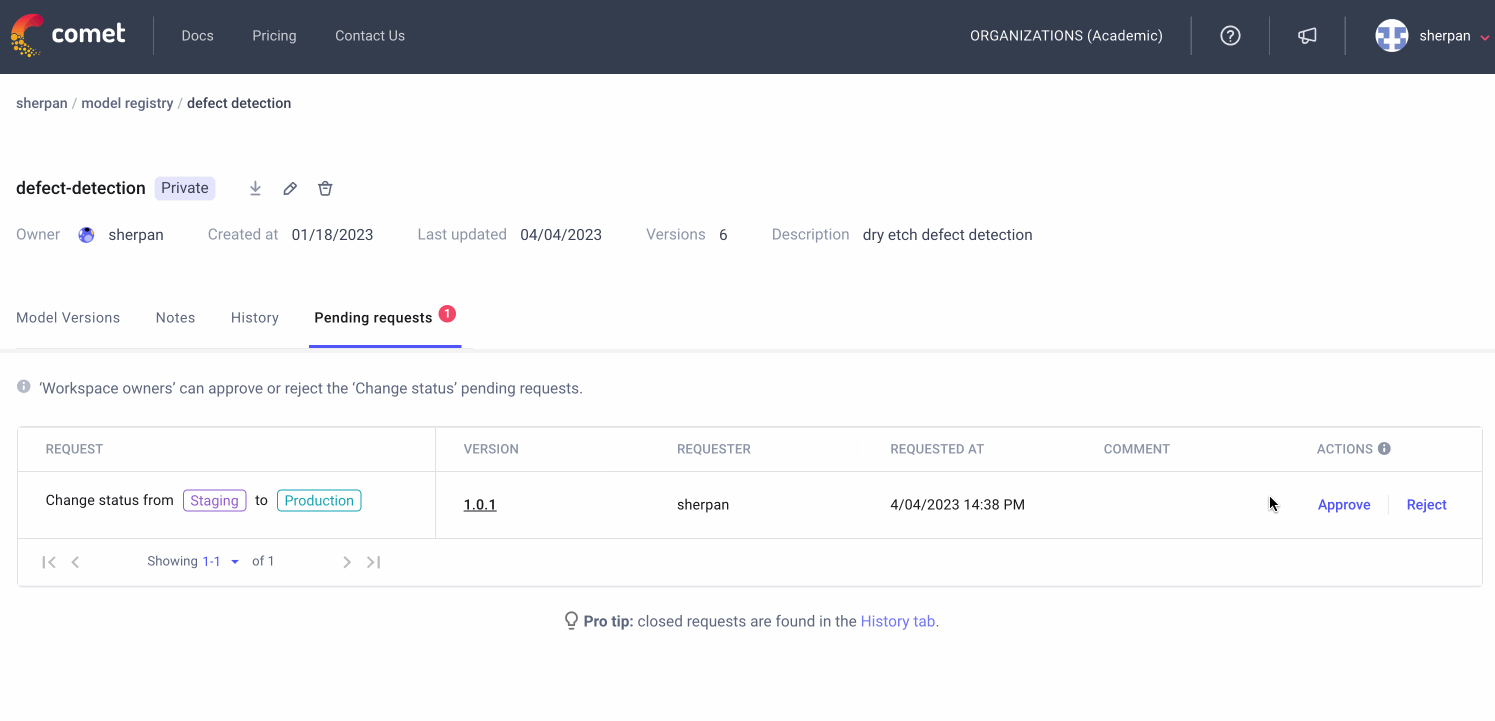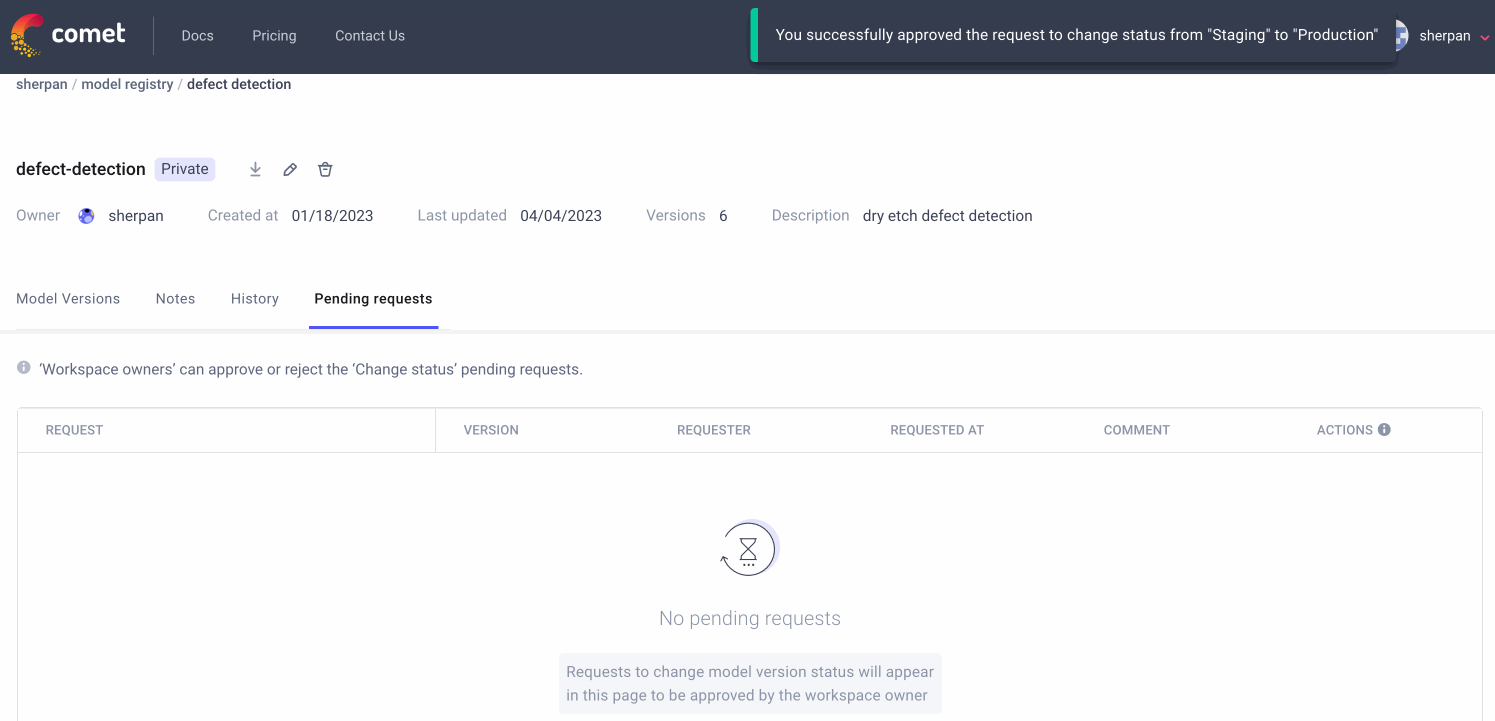
Model Monitoring
Comet monitors models in production to make sure they are behaving as expected. The platform can detect accuracy drift, missing values, and data drift at the feature level. When a model in production does fail, users can go back to the Model Registry and to see how a production model was trained and start to strategize the re-training process.
Improve ML Maturity with Comet
Comet is a flexible platform that can be easily integrated into a ML team’s current tooling with just a couple lines of code. Try out a free version of Comet today to get a feel for how it can optimize your ML maturity and team efficiency!
