Teams cannot ship dependable LLM systems with prompt templates alone. Model outputs depend on the full set of instructions, facts, tools, and policies surrounding each generation — the “context.” Context engineering is the discipline of designing, governing, and optimizing that surrounding information so models consistently do the right work with the right data.
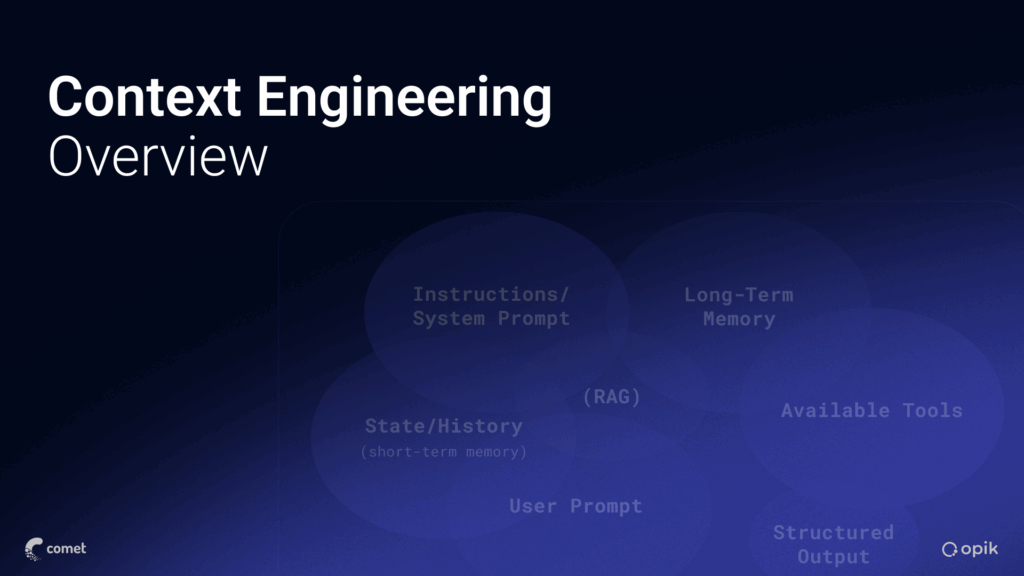
This overview covers what context engineering is, why it matters, and a few examples of how developers can make clever, impactful decisions for better AI applications.
What Is Context Engineering, and Why Does It Matter?
Any request sent to an LLM could include nearly-infinite information: a customer’s full purchase history, the entire customer service manual, and (why not?) a seven-day weather forecast for the customer’s location.
That approach would strain both budgets (each token costs money) and the LLM’s capabilities.
Each LLM’s context window dictates how many tokens (word-parts and punctuation) the model can process in its combined input and output. Few AI applications reach this “hard” limit when using modern models — though long-horizon tasks like AI coding agents can exceed even Claude Sonnet 4.5’s one million token context window.
All applications, however, encounter “softer” context limits. Due to how LLMs weight attention, each token added to a prompt, on average, reduces the influence of earlier tokens — especially when new text semantically overlaps with prior content. As a result, information near the start and end of a prompt tends to carry more weight, while mid-section content can get “lost in the middle.”
For example, in a long customer-service chat, the model may confuse details about prices or shipping dates across different orders.
Components of LLM Context
To understand how to engineer context, first understand its components.
- System prompt: The root-level instruction that defines the agent’s role, tone, and boundaries.
- User input: The incoming instructions or request from the user or orchestrating agent.
- Conversation history: The running record of the dialogue.
- Retrieved knowledge: Text or structured data pulled from a database, vector store, or web search.
- Tool descriptions: Definitions of available actions, APIs or external tools the agent can use.
- Task metadata: Information such as user attributes, file-type definitions, and performance constraints that guides the model toward more correct outcomes.
- Examples: Individual or few-shot examples that show the model the desired input/output pattern.
- Hidden content: Non-visible guardrails or moderation prompts provided by the LLM service.
With these components understood, the next challenge is designing how they interact — what to include, in what form, and under what rules.
Design Principles for Context Engineering
Context engineering operates on a simple premise: LLMs perform best when given only the most relevant, accurate, and structured information for the task at hand.
Effective design follows a set of principles that balance precision, scalability, and control:
- Relevance first: Every token in context should serve a clear purpose.
- Provenance and trust: All injected information should be traceable to a verified source.
- Compression over completeness: Concise representations outperform exhaustive ones.
- Hierarchical control: Structure instructions in layers: system-level for policy and tone, task-level for logic and objectives, and user-level for immediate requests.
- Adaptivity: Context should adjust dynamically to task conditions, user role, and session state.
- Observability by design: Capture logs of prompts, retrieved snippets, and generated outputs.
- Efficiency as a constraint: Treat token cost and latency as design variables, not afterthoughts.
- Safety and alignment: Integrate redaction, policy enforcement, and toxicity filters before data enters the context window.
Together, these principles establish a discipline where context becomes a governed interface between human intent, enterprise data, and model reasoning.
Context Engineering and Retrieved Knowledge
Context engineering often starts with deciding how to handle retrieved knowledge. This could come from internal knowledge bases, SQL databases, or the internet.
Consider a single-turn retrieval augmented generation (RAG) application. When the user asks a question, the system first seeks relevant documents that may contain the answer to include in the prompt. The prompt template includes places for the retrieved content, the user’s request, and instructions for how the LLM should use the supplied context to respond.
Outside of the prompt, the developer must choose:
- How to prepare and “chunk” the documents.
- How many document “chunks” to return in its search.
- How to filter and rank the retrieved chunks.
- How many chunks to include in the final prompt.
As applications mature, developers face increasingly nuanced trade-offs. Do you want your copilot chatbot to retrieve information in response to each prompt? If not, what triggers information retrieval? Should retrieved information remain in-context for the entire conversation? If not, when and how should it be cleared?
There’s no single right answer to any of these questions. They all depend on the application, and choices grow more complex as developers include more sources of context.
Context Engineering and Conversation History
Conversation history often dominates context windows. While a user’s interaction with a chatbot can quickly sprawl when working over a long document, many AI agents have conversations with themselves, invisibly filling context in the background.
Developers have worked out several solutions to sprawling conversation histories:
- Compaction: Compaction asks an LLM to summarize the oldest portion of the conversation, and is often used to prevent context window overflow in long-horizon applications.
- Structured note taking: In this approach, the application keeps notes in a document that lives outside of the conversation history. This allows it to retain important information after the conversational turn it originated from rotates out.
LLM applications don’t always need a conversation history. In some use cases, omitting it can simplify reasoning and reduce error propagation.
Context Engineering for Tools and Agentic subtasks
AI agents excite developers with their ability to use tools to complete tasks. This can include calling APIs, querying SQL databases, searching file directories, and more.
Each of these actions, however, adds to the context in ways that developers should carefully consider.
Tool Definitions
Tool definitions pose a special challenge for agent developers. For an LLM to use a tool, it must know what the tool does and how to use it. Describing the tool consumes tokens, raising costs and straining reliability.
To improve AI application reliability:
- CamelCase tool names: Punctuation such as periods and underscores often count as separate tokens.
- Ensure that each tool is unique: Tools with overlapping functions confuse LLMs. If an average person struggles to differentiate tools, the LLM will as well.
- Include only the tools needed: More sophisticated projects may call for more tools, but be judicious, and consider dynamically surfacing tools if possible.
- Consider making tools “discoverable”: An application may benefit from giving the model access to a tool that describes API endpoints rather than describing each endpoint up-front.
API and Agent Subtask Interactions
APIs predate LLMs and were designed primarily for interactions with deterministic systems. As a result, they often return excessive information that can confuse LLMs. Agentic subtasks create similar challenges, as they can act like APIs that exchange intermediate results.
The following practices help APIs and sub-agents manage context more efficiently:
- Summarize, don’t stream: For agents, collapse intermediate outputs into concise summaries before forwarding. For APIs, wrap services in companion processes to filter out unnecessary information. In either case, include only data essential for the next step.
- Craft descriptive error messages: Many APIs return minimal feedback on errors, preventing “self healing” agents from adjusting their approach. Adding informative error messages and recovery guidance improves reliability.
- Compress accumulated context: As multi-agent workflows grow, periodically distill the shared memory to maintain relevance and stay within context limits.
These and other approaches help ensure that your context includes only the most-needed information from your tool ecosystem.
Context Engineering for Better Few-Shot Examples
Few-shot prompting transformed early prompt engineering, and context engineering can further strengthen it.
Instead of hard-coding examples into a prompt template, you can use context engineering to inject examples more likely to be helpful at inference time.
To implement this, developers should:
- Collect a corpus of appropriate examples.
- Store the examples in a retrievable format (typically a vector database).
- Add a retrieval step to select relevant examples at inference time.
- Add the chosen examples into the prompt
Early experiments with this approach found that it could make models like GPT-2 and GPT-3 as much as 30% more accurate. Modern systems may see smaller absolute gains, but dynamically serving examples—such as how to format outputs for specific tools or return retrieved data to users—can materially improve application alignment and consistency.
Once context systems are designed, they must be managed like other production systems—governed, versioned, and continuously evaluated.
Governance and Evaluation in Context Engineering
Effective context engineering depends not only on design but on oversight. Governance and evaluation ensure that every prompt, retrieval rule, and tool definition contributes to reliable, auditable, and compliant system behavior.
Governance Fundamentals
Enterprises should treat context inputs as governed assets similar to production data and code.
Key practices include:
- Version control: Track changes to prompts, templates, retrieval pipelines, and tool definitions in source control.
- Access and provenance management: Maintain clear ownership of each context element, including the retrieved data’s origins, and version histories for system prompts.
- Policy enforcement: Integrate automated checks for data sensitivity, role-based access, and prompt-injection prevention. Guardrails should execute before any context is sent to a model.
- Change approval: Route major context updates through a review workflow, combining product, legal, and security perspectives.
Evaluation Methods
Because context directly shapes model behavior, it must be tested with the same rigor as model outputs through quantitative metrics and human inspection.
- Context coverage: Use metrics like context-precision and context-recall to measure whether retrieved or injected context contains the facts required to complete representative tasks.
- Context relevance: Evaluate how much of the supplied context contributes meaningfully to the final answer; automated similarity scoring and “LLM-as-judge” grading can identify waste.
- Prompt-performance regression tests: Run standard test suites after any context change to verify that downstream performance remains stable.
- Token efficiency: Track cost and latency against accuracy or satisfaction metrics.
- Human evaluation: Periodically audit generated outputs and their originating contexts for hallucination detection, and to identify policy violations or outdated knowledge sources.
Operational Visibility
Modern LLM observability platforms such as Opik can log every LLM call, including system prompts, retrieved chunks, and intermediate results. Analyzing this metadata enables developers to detect prompt drift, performance degradation, and policy breaches early.
Together, governance and evaluation convert context engineering from an experimental art into a managed discipline—one where every context element is versioned, measurable, and continuously improved.
Context Engineering: The Key to Highly Effective AI Applications
Context engineering challenges developers to make nuanced decisions in a confined space. The central idea boils down to this: aim to give the LLM the minimum necessary information it needs to complete the task.
Over time, context engineering rewards those who run well-crafted and well-monitored experiments—which is something Opik can help with.
With Opik, users can capture every LLM call, including system prompts, few-shot examples, retrieved context and metadata. The platform also includes built-in “LLM-as-judge” evaluations with context-precision and recall metrics, prompt versioning, and experimentation. This visibility enables clear tracing of what context was provided and how the LLM responded, allowing faster diagnosis of context-engineering issues.
