This article will comprehensively create, deploy, and execute machine learning application containers using the Docker tool. It will further explain the various containerization terms and the importance of this technology to the machine learning workflow. The article will contain hands-on sessions with practical coding examples as a use case. Lastly, it will discuss the best practices when working with Docker and the future of containerization.
What is Virtualization?
To understand the concept of containerization, we need first to understand virtualization. Virtualization is the process of creating a non-physical entity that is made to appear as physical; it is a concept that dates back to the 1960s. A good example is a metaverse, where aspects of the physical world are mimicked in a simulated digital environment. In computing, virtualization creates a virtual copy of a physical IT infrastructure and resources such as hardware, application storage, network, desktop/Operating system (OS), data, CPU/GPU, and simulates functionality. It’s more like distributing a physical machineʼs’s capacity among many users or virtual environments. Virtualization has enabled cloud providers to serve their existing physical infrastructure to users. There are two forms of virtualization:
- Virtual Machines (VMs)
- Containers
We need to ask what they virtualize to understand the difference between these two types of virtualization tools.
- Virtual Machines (VMs): VMs virtualize the underlying physical hardware/computer using a hypervisor, thus creating several virtual computers(machines). Each virtual machine runs its OS(also guest OS) required for the respective applications, libraries, and functions separately from the other VMs. Different VMs can be run on the same physical host; for example, a parallel physical host running Linux VM, macOS VM, and Microsoft VM. Some popular VM software are VMware, VirtualBox, QEMU, Microsoft Hyper-V, and Citrix Hypervisor.
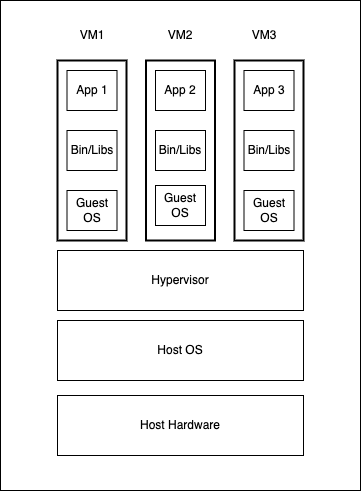
- Containers: Containers take an alternative approach, as they package just the application alongside its binaries, libraries, and dependencies and ship it all out as one package. Containers virtualize the host OS, whereas isolated containers see a virtual kernel. However, in reality, all the containers share the host kernel. So, one OS instance can run several isolated containers. This host kernel sharing makes containers lightweight, faster to boot, efficient resource management, and more accessible and faster to deliver applications than VMs.
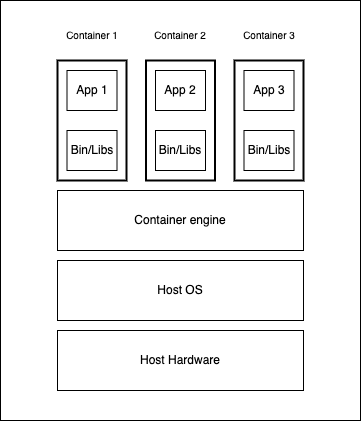
Containerization bundles an application with all its requirements, such as binaries, libraries, dependencies, and configuration files encapsulated in a single unit (executable) — called a container. Containerization yields portability as its containerized application is isolated and independent of the host hardware while utilizing its underlying resources like CPU and RAM. Containerization allows applications to be written once and run anywhere without concern about the machine or environment on which we run them. Despite containerization becoming a popular concept in the software industry, they have existed in different forms dating back to Unix V7, which added chroot in 1979. However, the emergence of the open-source Docker engine by Solomon Hykes in 2013 accelerated the adoption of the technology. Containerization is more portable, resource-efficient, and scalable than VMs.
What is Docker?
Docker is the most popular container technology. It is an open-source tool for building, deploying, and managing containerized applications. Docker has both the open-source variant and the commercial variant.
Docker’s container technology is powered by the Linux kernel, utilizing features such as control groups (cgroups) and kernel namespaces to create and manage loosely isolated environments. The cgroups are also known as process containers which monitor and manage resources such as CPU, disk IO, network, and memory for a collection of processes. At the same time, namespaces isolate the process groups and resources from each other. Each docker container has its set of processes and namespace; Docker also utilizes a network driver (libnetwork) for network isolation and communication between containers. Since Docker depends on the Linux kernel features, Windows and Mac systems can’t run the Linux containers directly. Docker tries to solve this compatibility issue with the Docker Desktop, where its internal working involves installing a micro Linux VM (Guest OS) on which it runs the containers. So rather than the VM using numerous Guest OS, this Docker Desktop install on a single VM (micro Linux VM) runs all containers and executes Docker commands. So, in general, Docker can’t run all operating systems. This Linux VM plugs into the Host OS and gives containers access to file systems and networking resources.
Why Use Docker for Machine Learning?
The machine learning (ML) lifecycle defines steps to derive values to meet business objectives using ML and artificial intelligence (AI). These steps include defining business and project objectives, acquiring and exploring data, modeling the data with various algorithms, interpreting and communicating the project outcome, and implementing and maintaining the project. In today’s agile environment, it is essential to perform multiple iterations and experiments, respond quickly to changes, and successfully deploy to deliver value and satisfy business requirements.
Docker creates isolated environments, making the development and deployment setup seamless as it bundles applications in containers. Docker makes machine learning workloads portable and reproducible. Virtual environments created by conda and virtualenv addresses are portable and reproducible. Yes, they do, but partially. These Python virtual environments encapsulate and manage Python dependencies, while Docker encapsulates the project’s dependency stack down to the host OS. So, you are sharing your entire development environment rather than sharing packaged dependencies and source code. Docker creates isolated environments, making the development and deployment setup seamless as it bundles applications in containers. Docker makes machine learning workloads portable and reproducible. You can argue that virtual environments created by conda and virtualenv addresses are portable and reproducible. Yes, they do, but partially. These Python virtual environments encapsulate and manage Python dependencies.
In contrast, Docker encapsulates the project’s entire dependency stack down to the host OS (and avoids issues of projects working on your machine and crashing on other people’s machines). So, you are sharing your entire development environment rather than sharing packaged dependencies and source code. Docker enables collaboration across machine learning projects while keeping consistency, portability, and dependency management at its core. Creating a virtual environment inside a Docker container makes little sense, as Docker provides the required isolations.
Demystifying some terminologies:
- Dockerfile: This human-readable text file contains all the commands or instructions to build docker images. It can be seen as a recipe specifying the required ingredients for the application.
- Docker Images: This template contains the source code, installations, and dependencies required to set up a fully operational container environment. Docker images are layers (collections of files that bundle the source code, installations, and required dependencies). These image layers follow a hierarchy, as each layer depends on the layer immediately below it.
- Docker Containers: This is a running instance of the Docker image, which serves as the virtual isolation environment that packages the application and all the requirements to run the application. Docker registry: This repository stores and distributes Docker images with specific names and versions. They are public and private Docker registries; Docker Hub is a public registry, and Docker, by default, is configured to look for images in Docker Hub.
- Docker Engine: This is the core of the Docker containerization technology, which acts as a client-server application. The Docker daemon (dockerd) as the server and the client side have been accessed by the command line interface (CLI) client (Docker). The Docker Engine handles interactions with the kernel and makes system calls for managing and creating containers. Docker APIs interact with the Docker daemon through the CLI commands or scripting.
Use Case
To drive the understanding of the containerization of machine learning applications, we will build an end-to-end machine learning classification application. The sample data for this project is E-Commerce Shipping data found on Kaggle to predict whether product shipments were delivered on time. The dataset used for model building contained 10999 observations of 12 variables. The data includes the following information:
- ID: Customer ID number.
- Warehouse block: The company warehouse is segmented into blocks such as A, B, C, D, and F.
- Mode of shipment: Company modes of shipping are ship, flight, and road.
- Customer care calls: Number of customer calls for shipment inquiries.
- Customer rating: Customers’ rating for shipping. From lowest(1) to highest(5).
- Cost of the product: Shipped products cost (USD).
- Prior purchases: Customer number of previous purchases.
- Product importance: Company importance category of products(low, medium, and high).
- Gender: Customers’ gender.
- Discount offered: Discount offered on that specific product.
- Weight in gms: Weight of products being shipped (grams).
- Reached on time: This is the target variable that indicates whether the product arrived on time, as 0 and 1, respectively.
Prerequisite
- Python 3.8 or newer.
- The Anaconda distribution includes several valuable libraries for data science.
- Docker installation.
- Heroku Account / Heroku CLI installation
- Basic knowledge of Flask, HTML, and CSS.
- Basic understanding of building machine learning models.
Machine Learning Model Development
Let’s initialize the project by creating a directory and setting up a Python virtual environment for storing the various Python dependencies. We can make the directory for our project from our terminal as follows:
mkdir containerized-app
Next, after creating the containerized-app folder, we change the working directory to the created folder as follows:
cd containerized-app
Next, we create a Python virtual environment to manage the project’s Python dependencies as follows:
python3 -m venv venv
The code to activate the virtual environment depends on your local machine. For macOS and Linux, run:
source venv/bin/activate
If you are using a Windows computer, activate the environment as follows:
venv\Scripts\activate
These commands create and activate a virtual environment called env so that the project will use packages installed and loaded from this environment instead of system-level packages.
The file structure at the beginning of this project(inside the containerized-app folder, so go ahead and create the app and ml-dev directories) should look like this:
.
├── app
├── ml-dev
└── venv
The app directory will contain our flask application, the ml-dev directory will contain our dataset and Jupyter notebook, and the venv virtual environment directory that manages our project Python dependencies.
Install Required Packages
Next, you install all the packages needed for this project. In your new virtual environment, install the following packages (which include libraries and dependencies):
pip3 install jupyterlab==3.4.3 Flask==2.1.2 gunicorn==20.1.0
xgboost==1.6.1 scikit-learn==1.1.1 matplotlib==3.5.2 missingno==0.5.1
Here are some details about these packages:
- jupyterlab is for model building and data exploration.
- flask is used for creating the application server and pages.
- gunicorn is for serving a production-ready Flask application.
- catboost is the machine learning algorithm for model building.
- scikit-learn is a machine learning toolkit.
- matplotlib is for data visualization.
- missingno is for missing values visualization.
If you haven’t tried to create the app and ml-dev directories, we can do that from our terminal in the containerized-app directory as follows:
mkdir app ml-dev
Then, change the directory to the ml-dev for our machine learning development task as follows:
cd ml-dev
The content of the ml-dev folder should look somewhat like this:
.
├── data
│ └── shipping_data.csv
└── dev-notebook.ipynb
Where the data directory contains the download use case data from Kaggle.
Start your Jupyter lab by running:
jupyter lab
This command opens the popular Jupyter Lab interface in your web browser. Create a new notebook named dev-notebook, where we will carry out interactive data exploration and model building. First, we import the necessary libraries for this project and read the dataset as follows:
# neccessary imports
import pandas as pd
import numpy as np
import pickle
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OrdinalEncoder, OneHotEncoder,
MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from xgboost import XGBClassifier
# Load data
data = pd.read_csv('data/shipping_data.csv')
feature_names = data.columns.tolist()
target = 'Reached.on.Time_Y.N'
The dataset has no missing instances and has 10999 rows & 12 features, including the target. The dataset has four categorical features, classified into nominal and ordinal. Next, we will create a pipeline (aid cleaner code) to take care of our preprocessing procedures that involve feature scaling (normalization) and categorical handling (ordinal and one-hot encoding for ordinal and nominal features, respectively), as follows:
# Re-categorical categories into nominal and ordinal categorical features
nominal_categroical_features = ['Mode_of_Shipment', 'Gender']
ordinal_categorical_features = ['Warehouse_block', 'Product_importance']
# Create preprocessing pipeline
numeric_pipeline = Pipeline(steps=[('scale', MinMaxScaler())])
warehouse_block_order = ['A', 'B', 'C', 'D', 'F']
product_importance_order = ['low', 'medium', 'high']
ordinal_categorical_pipeline = Pipeline(steps=[('ordinal encoding',
OrdinalEncoder(categories=[warehouse_block_order,
product_importance_order],handle_unknown="use_encoded_value",
unknown_value=-1))])
nominal_categorical_pipeline = Pipeline(steps=[('one-hot encoding',
OneHotEncoder(handle_unknown='ignore', sparse=False, drop='first'))])
# Compiling pipeline steps
preprocessing_pipeline = ColumnTransformer(transformers=[
('number', numeric_pipeline, numerical_features),
('ordinal_category', ordinal_categorical_pipeline,
ordinal_categorical_features),
('nominal_category', nominal_categorical_pipeline,
nominal_categroical_features)])
# Compile model pipeline
xgboost_instance = XGBClassifier()
full_pipeline = Pipeline(steps=[
('preprocess', preprocessing_pipeline),
('model', xgboost_instance)])
_ = full_pipeline.fit(X_train, y_train)
Let’s evaluate the performance of the model by its prediction.
# Making prediction
y_pred = full_pipeline.predict_proba(X_test)
# Evaluating results
print('ROC AUC score: ', roc_auc_score(y_test, y_pred[:, 1]))
Our model yielded an ROC AUC score of 0.74, which is satisfactory as ROC scores between 0.7 and 0.8 are considered acceptable. The model can be improved with more comprehensive preprocessing, hyperparameter tuning, and algorithm choices.
Lastly, we need to save the model pipeline as a pickle file to the app directory so our flask application can communicate with it easily as follows:
# create an iterator object with write permission - pipeline.pkl
with open('../app/pipeline.pkl', 'wb') as file:
pickle.dump(full_pipeline, file)
Creating Machine Learning Application with Flask
Flask is a Python web application framework that we will use to create a simple web application that enables interactions with a machine learning model pipeline. To commence building our web application, we will exit the ml-dev directory to the containerized-app directory as follows:
cd ..
And change our directory to the app directory that will contain files and directories to build our application:
cd app
Let’s look into our app directory structure to give a good overview of our project scope and functionalities. The app directory is as follows:
.
├── Dockerfile
├── Procfile
├── app.py
├── pipeline.pkl
├── requirements.txt
├── static
│ ├── containers.jpg
│ └── style.css
├── templates
│ └── index.html
└── wsgi.py
Let’s have a quick summary of the functionality of the various files and folders outlined above:
- templates: This folder contains assets describing our application’s main(home) page. It includes an index.html file, which defines our application’s web page structure and content.
- static: This folder contains assets used by templates, in this case, our index.html. These files include CSS stylesheets, javascript files, and images to add design and functionality.
- app.py: This script is our main application app that utilizes the Flask framework and refers to both the templates and static folders to build our application user interface (UI)
- pipeline.pkl: This is the classification model pipeline we developed in the model development section. The pickled pipeline will be applied to new data instances (user inputs) to generate predictions.
- wsgi.py: This script serves our flask application in the development server to a production server using Gunicorn.
- Dockerfile: This file contains all the instructions required to containerize our flask application adequately.
- Procfile: This file is required when deploying our application to Heroku (a public server so our application can be available online).
- requirements.txt: This file records and manages all the Python dependencies required for this project.
First, let’s record all our virtual environment’s current package list into a text file requirements.txt at the project’s base directory by running the following on our terminal:
pip3 freeze > requirements.txt
Next, we set up Git for version control to track all the changes in your application by initializing the Git repository to track changes in the project files as follows:
git init
Next, let’s create the app.py and input the following to get started building our application:
import os # For interacting with the file system
import pandas as pd # For data wrangling operations
import pickle # For loading the pickled model pipeline
from flask import Flask, render_template, request, url_for #
For web application development
app = Flask(__name__)
# Home route
@app.route("/", methods=['GET', 'POST'])
def home():
return render_template('index.html') # render_template helps
generate output of our HTML file
if __name__ == "__main__":
port = int(os.environ.get('PORT', 5000))
app.run(host = '0.0.0.0', port = port)
Our flask app — app.py starts by creating a flask object representing our app and then sets the home route view to our home page at index.html. The Flask app comprises a simple form that gets all the feature inputs defined by the index.html file and styled using CSS and Bootstrap. Bootstrap is a popular CSS framework for developing responsive and mobile-first web apps, and it’s easy to use with basic knowledge of HTML and CSS.
Flask is a great way to build Python applications quickly, but its inbuilt server is not production-ready, as it can only serve one person at a time. The Flask development server is intended for use only during local development as it is not particularly efficient, stable, and secure to run in the production environment. With this in mind, we must specify the host to 0.0.0.0 as the default refers to the local host (127.0.0.1). Changing the host to 0.0.0.0 makes the server publicly available, thus listening on all public IPs. Lastly, the application is bound to port 5000.
Next, let’s define the application UI by describing the structure of our web app, which is depicted with the HTML containers (block of content) with their respective classes below:
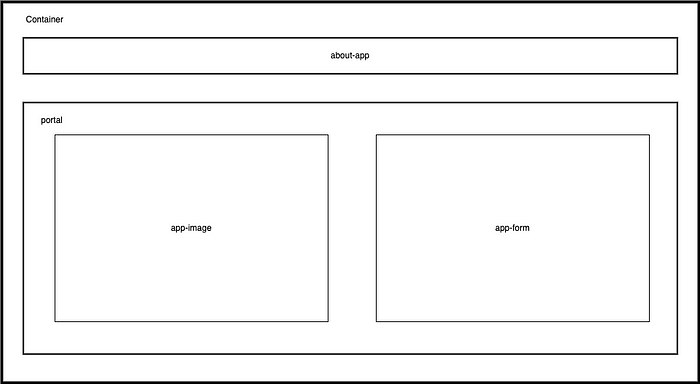
Following the structure above, the index.html file should contain the following:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>E-Commerce Shipping tracking app</title>
<!-- Importing Bootstrap CSS -->
<link
href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.2/dist/css/bootstrap.min.
css" rel="stylesheet" integrity="sha384-
EVSTQN3/azprG1Anm3QDgpJLIm9Nao0Yz1ztcQTwFspd3yD65VohhpuuCOmLASjC"
crossorigin="anonymous">
<!-- Importing Personal CSS -->
<link rel="stylesheet" href="../static/style.css">
</head>
<body>
<div class="container">
<div class="about-app">
<h1>E-Commerce Shipping web app that predicts whether a
product reach on time or not</h1>
</div>
<div class="portal">
<div class="app-image">
<img src="{{url_for('static',
filename='containers.jpg')}}" class="image">
</div>
<div class="app-form">
<h1 class="form-header">Product Shipment Tracking details:
</h1>
<form action="/predict" method="POST">
<div class="input-group input-group-sm mb-3">
<span class="input-group-text" id="inputGroup-
sizing-sm">ID</span>
<input name="form-id" type="number" class="form-
control" aria-label="Sizing example input" aria-describedby="inputGroup-
sizing-sm" required>
</div>
<select class="form-select form-select-sm mb-3"
name="form-warehouse-block" required aria-label=".form-select-sm example">
<option value="">Warehouse block</option>
<option value="A">A</option>
<option value="B">B</option>
<option value="C">C</option>
<option value="D">D</option>
<option value="F">F</option>
</select>
<select class="form-select form-select-sm mb-3"
name="form-shipment-mode" aria-label=".form-select-sm example" required>
<option value="">Mode of shipment</option>
<option value="Flight">Flight</option>
<option value="Ship">Ship</option>
<option value="Road">Road</option>
</select>
<div class="input-group input-group-sm mb-3">
<span class="input-group-text" id="inputGroup-
sizing-sm">Customer care calls</span>
<input type="number" class="form-control"
name="form-customer-care-calls" aria-label="Sizing example input" aria-
describedby="inputGroup-sizing-sm" required>
</div>
<select class="form-select form-select-sm mb-3"
name="form-customer-ratings" aria-label=".form-select-sm example"
required>
<option value="">Customer ratings</option>
<option value="1">Worst</option>
<option value="2">Bad</option>
<option value="3">Neutral</option>
<option value="4">Good</option>
<option value="5">Best</option>
</select>
<div class="input-group input-group-sm mb-3">
<span class="input-group-text">Cost of
product</span>
<span class="input-group-text">$</span>
<input type="number" class="form-control"
name="form_product_cost" aria-label="Dollar amount (with dot and two
decimal places)" required>
</div>
<div class="input-group input-group-sm mb-3">
<span class="input-group-text" id="inputGroup-
sizing-sm">Prior purchases</span>
<input type="number" class="form-control"
name="form-prior-purchases" aria-label="Sizing example input" aria-
describedby="inputGroup-sizing-sm" required>
</div>
<select class="form-select form-select-sm mb-3"
name="form_product_importance" aria-label=".form-select-sm example"
required>
<option value="">Product importance</option>
<option value="low">Low</option>
<option value="medium">Medium</option>
<option value="high">High</option>
</select>
<div class="form-check form-check-inline">
<input type="radio" class="form-check-input"
id="validationFormCheck2" name="form-gender" value="M" required>
<label class="form-check-label"
for="validationFormCheck2">Male</label>
</div>
<div class="form-check form-check-inline">
<input type="radio" class="form-check-input"
id="validationFormCheck3" name="form-gender" value="F" required>
<label class="form-check-label"
for="validationFormCheck3">Female</label>
</div>
<div class="input-group input-group-sm mb-3">
<span class="input-group-text">Discount
offered</span>
<span class="input-group-text">%</span>
<input type="number" class="form-control"
name="form-discount-offered" aria-label="Discount(with percentage)"
required>
</div>
<div class="input-group input-group-sm mb-3">
<span class="input-group-text">Weights</span>
<span class="input-group-text">gms</span>
<input type="number" class="form-control"
name="form-weights-gms" aria-label="Weights(in grams)" required>
</div>
<button type="submit" class="btn btn-
success">Predict</button>
<div>
<label for="disabledTextInput" class="form-label
prediction-label">Reached on time prediction:</label>
<input type="text" id="disabledTextInput"
class="form-control" placeholder="No prediction" disabled>
{% if prediction == 1%}
<script>
document.getElementById('disabledTextInput').placeholder = 'Not on time'
</script>
{% elif prediction == 0%}
<script>
document.getElementById('disabledTextInput').placeholder = 'On time'
</script>
{% endif %}
</div>
</form>
</div>
</div>
</div>
<!-- Importing Bootstrap JS Bundle with Popper -->
<script
src="https://cdn.jsdelivr.net/npm/bootstrap@5.0.2/dist/js/bootstrap.bundle
.min.js" integrity="sha384-
MrcW6ZMFYlzcLA8Nl+NtUVF0sA7MsXsP1UyJoMp4YLEuNSfAP+JcXn/tWtIaxVXM"
crossorigin="anonymous"></script>
</body>
</html>
The CSS stylesheet style.css, in addition to the already functioning bootstrap CSS, helps set alignments of components using flexbox and grid, as well as font attributes and image sizing, which contain the following:
:root {
--pd: 20px /* padding variable */
}
* {
box-sizing: border-box;
margin: 0;
padding: 0;
}
body {
color: #131415;
font-family: spezia, sans-serif;
display: flex;
flex-direction: column;
justify-content: space-around;
height: 100vh;
}
.about-app h1 {
font-size: 20px;
font-weight: bold;
padding-bottom: var(--pd);
}
.portal {
display: grid;
grid-template-columns: 1fr 1fr;
gap: 4em 0.75em;
}
.image {
width: 95%;
border-radius: 1%;
height: auto;
}
.form-header {
font-size: 15px;
font-weight: bold;
padding-bottom: var(--pd);
}
.prediction-label {
padding-top: var(--pd);
font-weight: bold;
}
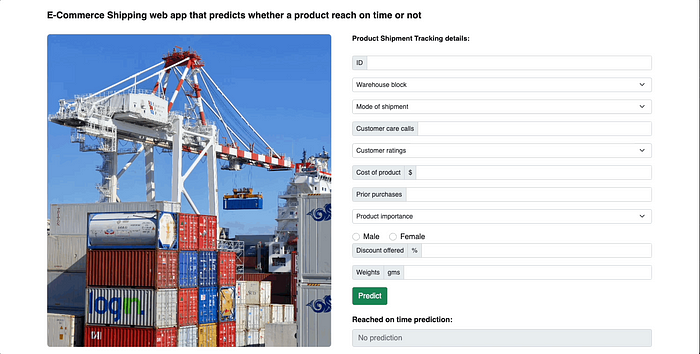
With that, our web application page should look like the image below:

Note: The image on the web app is the container.jpg photo found in the static folder. The image is sourced for free images on Pexels here.
Our web application looks good but isn’t functional; we need to capture the responses from the form, create a data frame instance, and make predictions using our model pipeline. Note that the respective form components have associated name attributes; we will request values from the form components using these attributes. To do this, we return to our flask app script app.py and create a second route named predict (directly below the end of the first route statement). We will utilize flask requests to get form responses from the index.html file. Our form applies bootstrap validation, so all inputs are required types, and all inputs are filled before predicting to avoid missing values in our data frame instance. Also, the
url_for aids in referencing the relative path of the static files. Let’s add the predict route in our app.py as follows:
# Prediction route
@app.route("/predict", methods=['POST'])
def predict():
# Extract the form values: id = request.form['form-id']
warehouse_block = request.form["form-warehouse-block"]
mode_of_shipment = request.form["form-shipment-mode"]
customer_care_calls = request.form["form-customer-care-calls"]
customer_ratings = request.form["form-customer-ratings"]
cost_of_product = request.form["form_product_cost"]
prior_purchases = request.form["form-prior-purchases"]
product_importance = request.form["form_product_importance"]
gender = request.form["form-gender"]
discount_offered = request.form["form-discount-offered"]
weights_gms = request.form["form-weights-gms"]
form_data = {
"ID": [id],
"Warehouse_block": [warehouse_block],
"Mode_of_Shipment": [mode_of_shipment],
"Customer_care_calls": [customer_care_calls],
"Customer_rating": [customer_ratings],
"Cost_of_the_Product": [cost_of_product],
"Prior_purchases": [prior_purchases],
"Product_importance": [product_importance],
"Gender": [gender],
"Discount_offered": [discount_offered],
"Weight_in_gms": [weights_gms]
}
# create form dataframe to apply model pipeline
form_df = pd.DataFrame(form_data)
form_df.drop(columns=['ID'], inplace=True)
# loading model pipeline
model_pipeline = pickle.load(open("pipeline.pkl", "rb"))
# applying model pipeline from form dataframe to make predictions
my_prediction = model_pipeline.predict(form_df)
return render_template('index.html', prediction=my_prediction)
The prediction is sent to index.html using the Jinja template (i.e., the {} conditional statement in the prediction section of the index.html). Our Flask app is ready, and we can test it application by typing the following on your terminal:
python3 app.py
or
flask run
Both run the application locally. You will see output like the following, including a helpful warning reminding you not to use this server setup in production:
The app is currently running on my IP address. On your system, visit your server’s IP address followed by the port:5000 in your web browser, like http://your_server_ip:5000, to load and view our flask application. A quick demo of our app working is shown below:
The Flask development server (Werkzeug’s Web Server Gateway Interface (WSGI) server) is unsuitable for production as it can only handle one request at a time. Also, its performance and security aren’t efficient and stable. Notice that if we terminate the Flask app on our terminal, our application will no longer be reachable. We must switch from this Flask’s development server to a production WSGI server. Many WSGI servers have different configurations, such as gunicorn, waitress, bjoern, mod_wsgi, and gevent. Based on its simplicity, popularity, and speed, I will switch from the Flask development server to the Gunicorn. For this switch, we will create a new wsgi.py file, where we will import our flask application and run it as follows:
# importing flask app
from app import app
if __name__ == "__main__":
app.run()
To start serving our application with Gunicorn, we execute the following on our terminal as we access our Flask app from the wsgi.py script and bind it to port 5000 as follows:
gunicorn --bind 0.0.0.0:5000 wsgi:app
The output should look like this:

The above command runs the server in the foreground; when we terminate the application via our terminal, our application will no longer be reachable. We can run the server in the background, where closing the application runtime on the terminal wonʼt affect the application’s reachability. It can be stopped by killing it on the process/task manager as follows:
gunicorn --bind 0.0.0.0:5000 wsgi:app &
We can access our app via both channels (foreground and background) at http://0.0.0.0:5000, which means listening to port 5000 on all IPs as 0.0.0.0 is a placeholder.
Lastly, let’s record all our virtual environment current package list into a text file requirements.txt at the app directory by running the following on our terminal:
pip3 freeze > requirements.txt
Containerization of the Application Using Docker
With our application built and functional, we will move next to containerize our application using Docker. First, we start our Docker desktop (for Mac and Windows users), so the docker daemon can run by simply opening the installed Docker desktop app on your local machine. Next, create a Dockerfile in the app directory of our project by creating a file, naming it Dockerfile with no extension, and adding the following snippet in that file:
# start by pulling the python image
FROM python:3.8-slim-buster
# Set and create the working directory to /app
WORKDIR /app
# Copy the current directory contents into /app
COPY . /app
# informs Docker that this container should listen to network port 5000 at
runtime
EXPOSE 5000
# install the dependencies and packages in the requirements file
RUN apt-get -y update
RUN apt-get update && apt-get install -y python3 python3-pip
RUN pip3 install -r requirements.txt
# executing the container
CMD ["gunicorn", "--bind", "0.0.0.0:5000", "wsgi:app"]
Before we build a docker image using the Dockerfile for our application, let’s first understand the instructions in the Dockerfile:
- FROM python:3.8-slim-buster: While it is possible to create base images, Docker allows us to inherit existing images. Here, we install a basic Debian Python image in our Docker image.
- WORKDIR /app: The WORKDIR instruction defines the default working directory of our application in the container image where subsequent Dockerfile instructions such as RUN, CMD, ENTRYPOINT, COPY, and ADD will be operated. The syntax in our Dockerfile is WORKDIR </path/to/workdir>, the default path /, but it is considered good practice to specify your WORKDIR. If the WORKDIR is specified in the Docker file, like in our case/app, it creates the directory in our container image, so we can say it implicitly performs mkdirandcd. Here, we set the working directory as /app, which will be the root directory of our application in the container image. It is possible to have multiple WORKDIR instructions in your Dockerfile`.
- COPY . /app: As the name implies, it copies files or directories from the local computer to the filesystem of the image following the syntax COPY <src> <dest> where the src and dest are file paths of the directory on the local machine and destination to the directory in our docker image filesystem. Here, we are copying everything from the directory where the Dockerfile is located in our local machine to our working directory (app) that includes files and directories such as the app.py, wsgi.py, pipeline.pkl, requirements.txt, static, and templates.
- EXPOSE 5000: The EXPOSE instruction informs the image created using this Dockerfile to listen to port 5000 when running a container. This helps build and deploy network-aware container applications and aids inter-container communication. The EXPOSE instruction syntax is EXPOSE<port>/<protocol>, where the protocol is either TCP or UDP, with TCP being the default protocol. Note that this instruction does not map ports on the local machine.
- RUN commands: The RUN instructions are executed as a shell command within the container at build time. Here, it installs pip3 and all the dependencies defined in the requirements.txt file into our application within the container.
CMD [“gunicorn”, “ — bind”, “0.0.0.0:5000”,wsgi:app”]: This CMD command instructs Docker to run our flask app in the Gunicorn server as a module and also makes the container available externally with the host 0.0.0.0 and binding it to port 5000.
Next, let’s proceed to build our Docker image using the tag (mutable reference name) shipping_app from this Dockerfile as follows:
docker build -t shipping_app .
With the image successfully built, the output should look similar to the following:
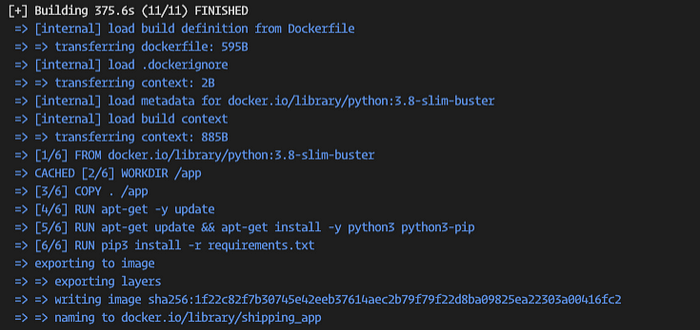
We can view the built images from the Docker desktop application or on our terminal (command line) as follows:
docker images
Next, we run an instance of the image (container) as follows:
docker run -p5000:5000 shipping_app
This command runs the containerized application, binding the port allocated to the container on our machine to the port where the application will run on the container. This yields the following:

Where the application can be accessed at http://yourip:5000
However, it is best to run the container in detached mode by the option — detach or -d, where the container runs at terminal background, where terminating the application runtime on the terminal wonʼt affect the application reachability. We make the following modification to our docker run command as follows:
docker run -d -p 5000:5000 shipping_app
We can see the containers currently running using the following commands:
docker ps
The output is as follows:

The previous command shows us the active container (which is the one we ran on detached mode). To view all containers, including the ones that arenʼt running, we use the following commands:
docker ps -a

Deploying Our Flask Application to Docker Hub
DockerHub is a service provided by Docker that serves as a community of repositories where Docker users create, test, manage, store, and share container images. It is free for public repositories and has a subscription plan for private repositories. In this section, we will push (upload) our container image to DockerHub so you can access it anywhere.
Follow the following steps:
- Sign up on Docker Hub if you don’t already have an account.
- After creating an account and successfully logging in, click on the Repositories navigation bar and create a new repository as follows:
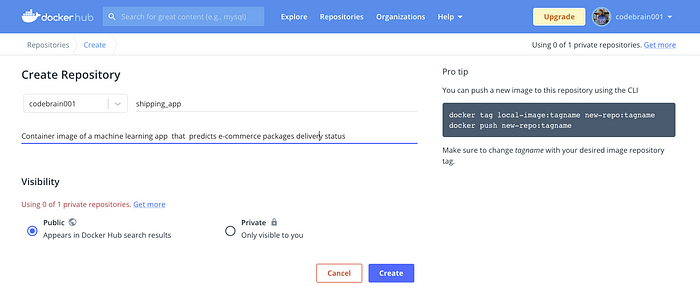
- Click Create, which will successfully create your first Docker Hub repository. You should see:
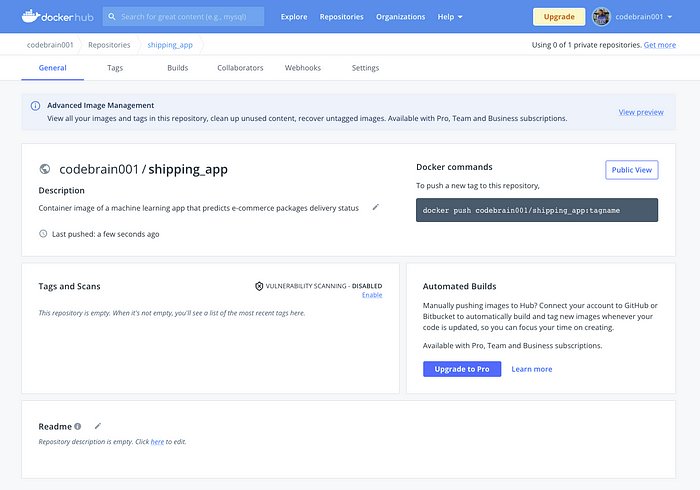
- Next, with our Docker Hub repository set up, we need to connect Docker Hub and our local machine. On our terminal in our local machine, log into Docker, which will prompt you to enter your Docker Hub username and password as follows:
docker login
- Upon successful login, before we push our image to the created repository, we have to rename our image to the standard format following <your-docker-hub-username>/<repository-name>. We renamed our Docker image as follows:
docker tag shipping_app <your-docker-hub-username>/shipping_app
- Lastly, we push the image to Docker Hub as follows:
docker push <your-docker-hub-username>/shipping_app
Once completed, your Docker Hub repository should look like this:
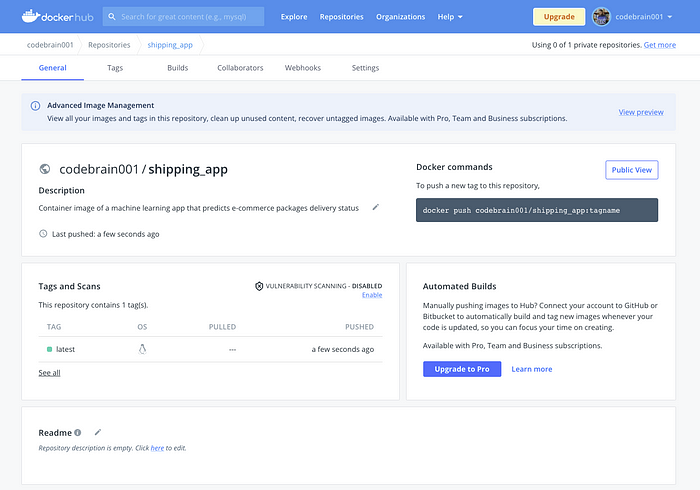
To pull this image from Docker Hub, we need to use the docker pull command using the syntax docker pull <your-docker-hub-username>/<repository-name>:tagname as follows:
docker pull codebrain001/shipping_app
With the image successfully pulled, you can test the application using the docker run command following the syntax docker run <your-docker-hub-username>/<repository-name>:tagname as follows:
docker run codebrain001/shipping_app
If you don’t have Docker installed on your machine and want to test the application, you can use Play with Docker, creating a virtual machine browser where we can build and run Docker containers.
Deploying the Containerization Application to the Cloud
Next, we will host our containerized application on the cloud to leverage cloud infrastructure rather than on-premise. This cloud infrastructure will also enable our hosted applications to be accessed and interacted with over the internet. Platform as a service (PaaS) provides a complete cloud environment, flexible and scalable, to develop, deploy, run, manage, and host applications. Numerous platforms can host our Python containerized application, such as Heroku, PythonAnywhere, Platform.sh, Google App Engine, Digitalocean app platform, and AWS Elastic Beanstalk. With Docker enabling containerization of our app, we can move our application to any cloud provider. For this tutorial, we will use Heroku due to its simplicity of deployment and popularity.
Heroku makes developing and deploying Python applications (built with Flask or Django) easy. Heroku handles infrastructure details such as providing HTTPS certificates, managing DNS records, and running and maintaining servers. Let’s start deploying our containerized application to Heroku using its Container Registry.
- First, sign up on Heroku if you don’t already have an account.
- Next, install the Heroku CLI, which helps us create and manage our Heroku apps from the terminal. It is the convenient and quickest way to deploy our application.
- With the Heroku CLI installed, let’s connect our Heroku account to our local machine by login on our terminal as follows:
heroku login
- We can use the Heroku CLI to build and manage our application upon successful login. Next, we create a Procfile with no extension in the name, still located in our application directory. This Procfile detail commands that the Heroku app on startup will execute and tells Heroku how to run the app. The content of the Procfile is as follows:
web: gunicorn --bind 0.0.0.0:$PORT wsgi:app
The Procfile filename must start with a capital P, and there must not be any comments inside the file
- Next, add all the files and changes to the Git repository as follows:
git add .
- Next, add a commit message used to save the changes on Git as follows:
git commit -m "Added application files ready for deployment to Heroku"
- Next, we create a Heroku application as follows:
heroku create ecommerce-shipping-app
This command initialized our Heroku application and created a Git remote (remote repository hosted on the internet) named heroku. Heroku application names must be unique; hence, choose a different application name for your deployment. The output should be similar to this:

- Next, we need to push the Git repository to this Heroku remote to trigger the build and deployment process as follows:
git push heroku master
The output will show the building and deployment process and installation of dependencies information as the commands execute (pushing the main branch to the Heroku remote).
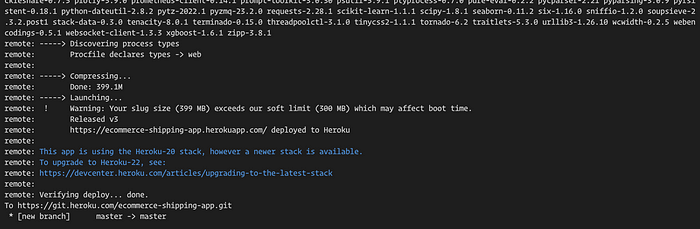
Congratulations, our application is now online. You can find the URL at the output of the last execution following the syntax https://<your-app-name>.herokuapp.com/. My application is at https://ecommerce-shipping-app.herokuapp.com/ (This explains why the app name has to be unique, as different applications can share the same URL).
Alternatively, you can open your application via the Heroku CLI as follows:
heroku open
Conclusion
In this guide, we build a machine learning model (classifier) and create a flask application with a WSGI production server. Afterward, we containerized the machine learning application with Docker and shared the created Docker image with Docker Hub. Lastly, we pushed a containerized machine learning application to Heroku to access it over the internet.
For more information on incorporating Docker with your application, the Docker documentation is a valuable resource you can reference.
The entire project can be found on GitHub here.
Thanks for reading, cheers!
