GitHub’s new “AI Pair Programmer”, Distill Pub announces a hiatus, examining parameter counts in ML research, and why robots aren’t a solution to the search and rescue mission in Miami’s tragic condo collapse.
Welcome to issue #8 of The Comet Newsletter!
This week, we share details and our perspective on GitHub’s new “AI Pair programmer and Distill Pub’s announced hiatus.
Additionally, we highlight an interesting analysis of parameter counts in machine learning research, as well as a reflection on why robots aren’t cut out for helping with the unfolding crisis at the site of the recent Miami condo collapse.
Like what you’re reading? Subscribe here.
And be sure to follow us on Twitter and LinkedIn — drop us a note if you have something we should cover in an upcoming issue!
Happy Reading,
Austin
Head of Community, Comet
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
GitHub introduces “Copilot: your AI pair programmer”
GitHub announced a new project, Copilot, that’s been built on top of OpenAI’s Codex. The new AI system uses context prompts provided by the developer, in the form of comments, docstrings, function names, or even code to synthesize or complete the code for a given functionality.
Copilot can generate code from comments, autofill repetitive code, and even write tests. Copilot also comes with a dedicated VSCode package and works inside GitHub’s codespaces.
We see Copilot as the convergence of Microsoft’s investments in OpenAI and GitHub, leveraging the advanced language modeling capabilities of GPT-3 and the vast amount of code available on GitHub as training data.
GitHub has also included a detailed report on whether Copilot simply recites code from the training set or truly generates something novel—a dynamic which has generated a bit of controversy in the community (read more about that here and here).
The service is still a work in progress, and Github is currently offering access via technical preview to developers in order to test and improve the system.
Read the full announcement here.
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
Distill, an interactive online journal for ML publications, announces indefinite hiatus
Distill, the seminal interactive online journal for Machine Learning publications, will be taking a year-long hiatus that could extend indefinitely.
For the past 5 years, Distill has been a venue for authors to explore methods for scientific communication—from Gabriel Goh’s interactive exposition of momentum, to feature visualizations that attempt to interpret the information represented in the neurons of a network.
The editorial team at Distill cite changes in the way they think about the function of Distill—as well as burnout from the volunteer team—as the reason for this hiatus. Specifically, they talk about the inherent conflict between being a highly-editorialized journal while also trying to achieve their other goals of mentorship and providing a neutral venue for publication.
They believe that Distill isn’t living up to their expected standards for author experience. Burnout has made the review process much slower and similar to a typical journal. The team said it was becoming unclear to them if their review process added enough value to justify the additional time cost to authors.
The team also feels like self-publication (for example on ArXiv) might be a large fraction of the future of scientific communication. There are tremendous benefits to journal-led review, but the team asks whether “traditional journal-led peer review is the most effective way to achieve these benefits? And is it worth the enormous costs it imposes on editors, reviewers, authors, and readers?”
Extending on the notion of self-publishing being a big part of the future, the team noted that “Self-publication can move very fast. It doesn’t require a paper to fit into the scope of an existing journal. It allows for more innovation in the format of the paper, such as using interactive diagrams as Distill does. And it aligns incentives better.”
Distill’s approach to scientific communication has inspired a wave of open source and commercial projects aimed at better communication for Machine Learning. Tools like Google’s Model Cards, Streamlit’s UI’s for Data Science, and even Comet’s own Reports all leverage interactive visualizations to communicate ideas in machine learning.
Despite the hiatus, the Distill template is still open source and freely available, and the Editorial Team is hopeful that others will run with it and attempt to build on their work.
Read the complete comments from the Distill team here.
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
Examining parameter counts in machine learning
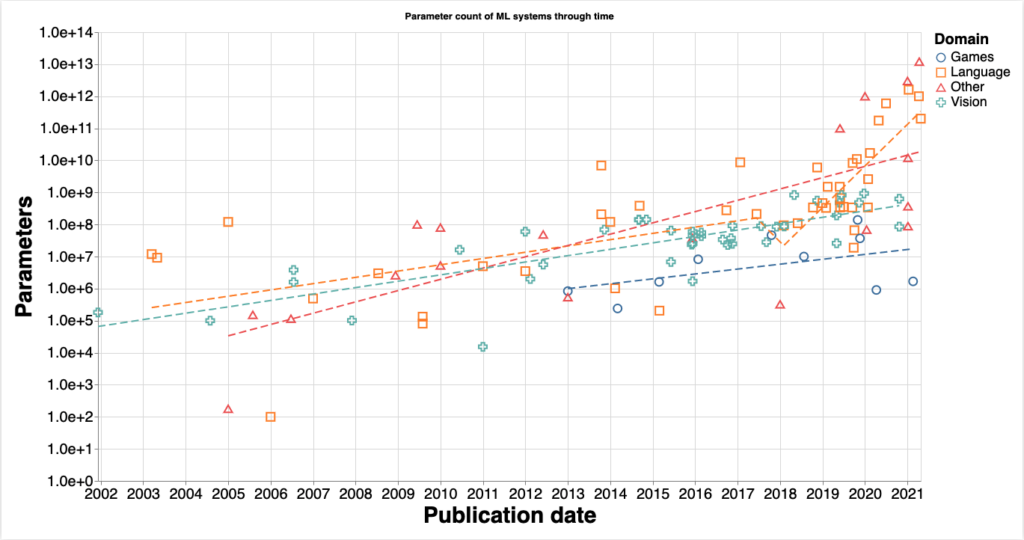
How do you measure the collective progress of AI technology? Currently, no one has great answers for this question, but researchers at the Alignment Forum have suggested using the parameter count of models as a “proxy metric that allows us to understand one way in which models have become more complex over time, and ground predictions of how the field will progress in the future.”
In particular, they hope to tease apart how much of the advancement is coming from algorithmic improvements, and how much is coming from increases in model complexity.
The trend they found was that parameter counts for models have been increasing over time. The two main insights from this work are
- “There was no discontinuity in any domain in the trend of model size growth in 2011-2012. This suggests that the Deep Learning revolution was not due to an algorithmic improvement, but rather the point where the trend of improvement of Machine Learning methods caught up to the performance of other [non-]ML methods.”
- From 2016 onwards, there has been discontinuity in the scale of language models. “An eyeball estimate of the slope of progress suggests that the doubling rate was between 18 and 24 months from 2000 to 2016-2018 in all domains, and between 3 and 5 months from 2016-2018 onward in the language domain.”
The researchers conclude their post with a critique of their dataset and data collection methods, a list of open questions based on the uncovered trends, and links to the dataset and code used to produce the article.
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
Why robots can’t be counted on to find survivors in the Florida building collapse
On June 24th, a portion of the 12-story Champlain Towers South condominium building in Surfside, Florida, suffered a catastrophic partial collapse. In this article, Evan Ackerman explains the reason why robots have seen limited use in a rescue situation such as this.
The article covers the complexities of collapsed structures and the safety considerations of trying to send a robot into such environments.
Dr. Robin Murphy, the director of the Humanitarian Robotics and AI Laboratory at Texas A&M, says that “using robots to explore rubble of collapsed buildings is, for the moment, not possible in any kind of way that could be realistically used on a disaster site.”
“Rubble is a wildly unstructured and unpredictable environment,” Dr Murphy continued. “Most robots are simply too big to fit through rubble, and the environment isn’t friendly to very small robots either, since there’s frequently water from ruptured plumbing making everything muddy and slippery, among many other physical hazards.”
Disaster scenarios in robotics research also assume that objectives are achievable if the right path is followed. Real disasters are not like that. The act of moving rubble out of the way can cause the robot to dislodge structures that dramatically change the navigation path—or worse, cause injury. Robotic sensing systems are also not well designed for extremely close quarters, and visual sensors such as cameras can become rapidly damaged by dirt and debris.
Rescue robots would need to be able to understand the internal structure of the rubble—and the consequences of altering the structure—in order to be effective. On top of these technical challenges, Dr. Murphy also notes that the ethical expectation is for robotics technology used in these situations to be fully mature.
“It’s obviously unethical to take a research-grade robot into a situation like the Florida building collapse and spend time and resources trying to prove that it works.”
