-
Multimodal LLM Evaluation: A Developer’s Guide to Multimodal Language Models
Production teams processing billions of product listings, such as Shopify, report that multimodal LLMs analyzing product images alongside metadata can…

-
AI Agent Evaluation: Building Reliable Systems Beyond Simple Testing
Your customer service agent routes 2,000 queries daily. During testing, it resolved 85 percent of requests correctly. Three weeks after…

-
LLM Parameter Optimization: Stop Leaving Agent Performance on the Table
If you search for “LLM parameter optimization,” you’ll find guides on tuning learning rates, batch sizes, and layer configurations. But…

-
Prompt Learning: Using Natural Language to Optimize LLM Systems
Your customers expect better and more consistent results than your AI agent can deliver. You manually tweak a prompt, test…

-
Chain-of-Thought Prompting: A Guide for LLM Applications and Agents
When Google researchers asked GPT-3 to solve grade-school math problems, the model answered 17.9 percent of the problems correctly. When…

-
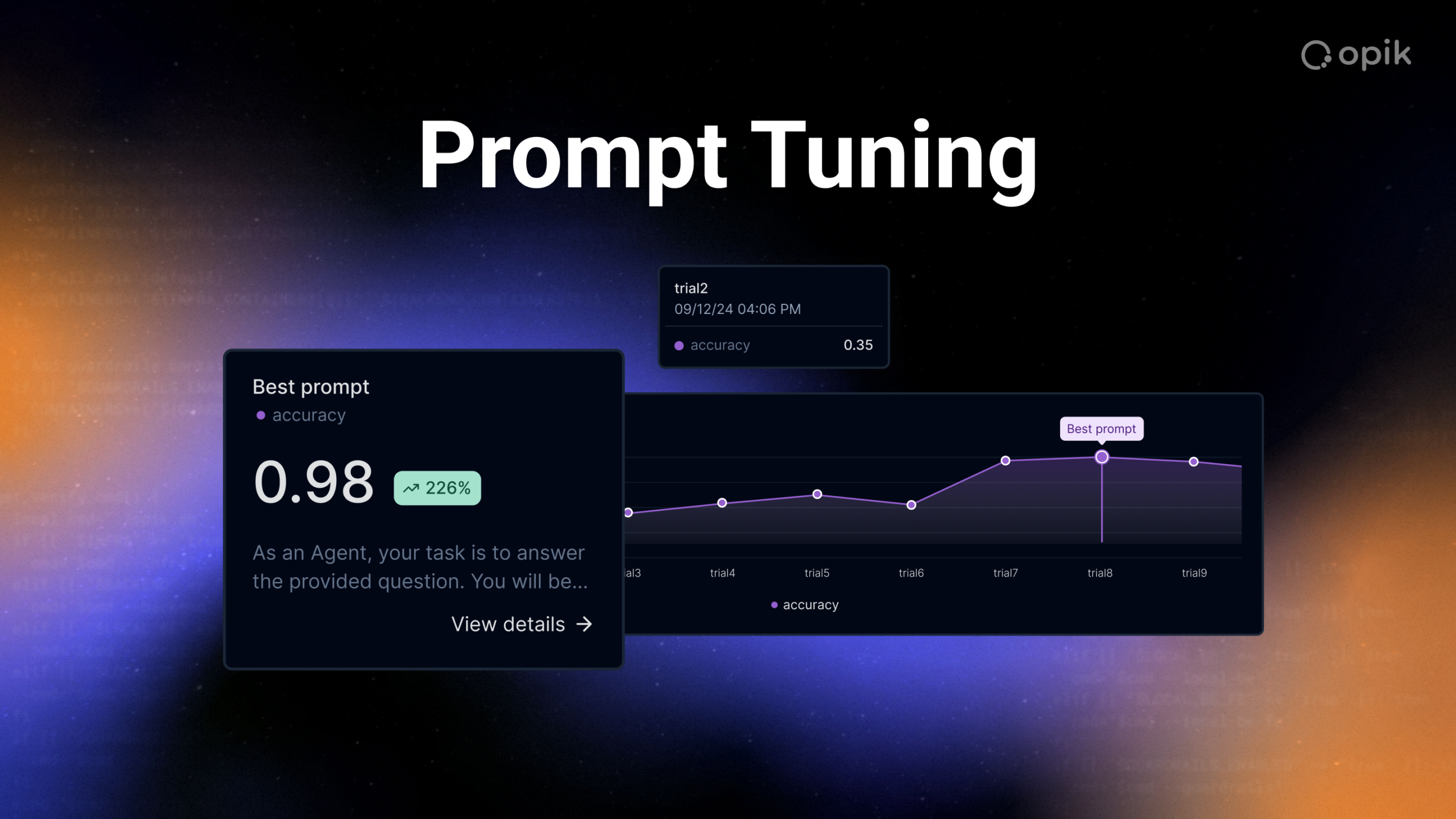
Prompt Tuning: Parameter-Efficient Optimization for Agentic AI Systems
You’ve built an agentic system that coordinates retrieval, reasoning, and response generation across multiple specialized tasks. Now you need to…
-
MIPRO: The Optimizer That Brought Science to Prompt Engineering
You know the routine: Write your first prompt, and then spend hours manually tweaking prompts, testing variations, and documenting what…

-
GEPA: Why Reflection-Based Optimization Is Replacing Reinforcement Learning for AI Agents
Your multi-hop reasoning agent fails 55 percent of the time. You spend three days tweaking prompts by adjusting the phrasing,…

Author: Jamie Gillenwater

Get started today for free.
You don’t need a credit card to sign up, and your Comet account comes with a generous free tier you can actually use—for as long as you like.