Agent Optimization
Opik Agent Optimizer is a comprehensive toolkit designed to enhance the performance and efficiency of your Large Language Model (LLM) applications. Rather than manually editing prompts and running evaluation, you can use Opik Agent Optimizer to automatically optimize your prompts.
Getting Started
Here’s a simple step-by-step guide to get you up and running with Opik Agent Optimizer:
1. Set up your account and API key
First, you’ll need an Opik account and API key:
If you don’t have an account yet, sign up here.
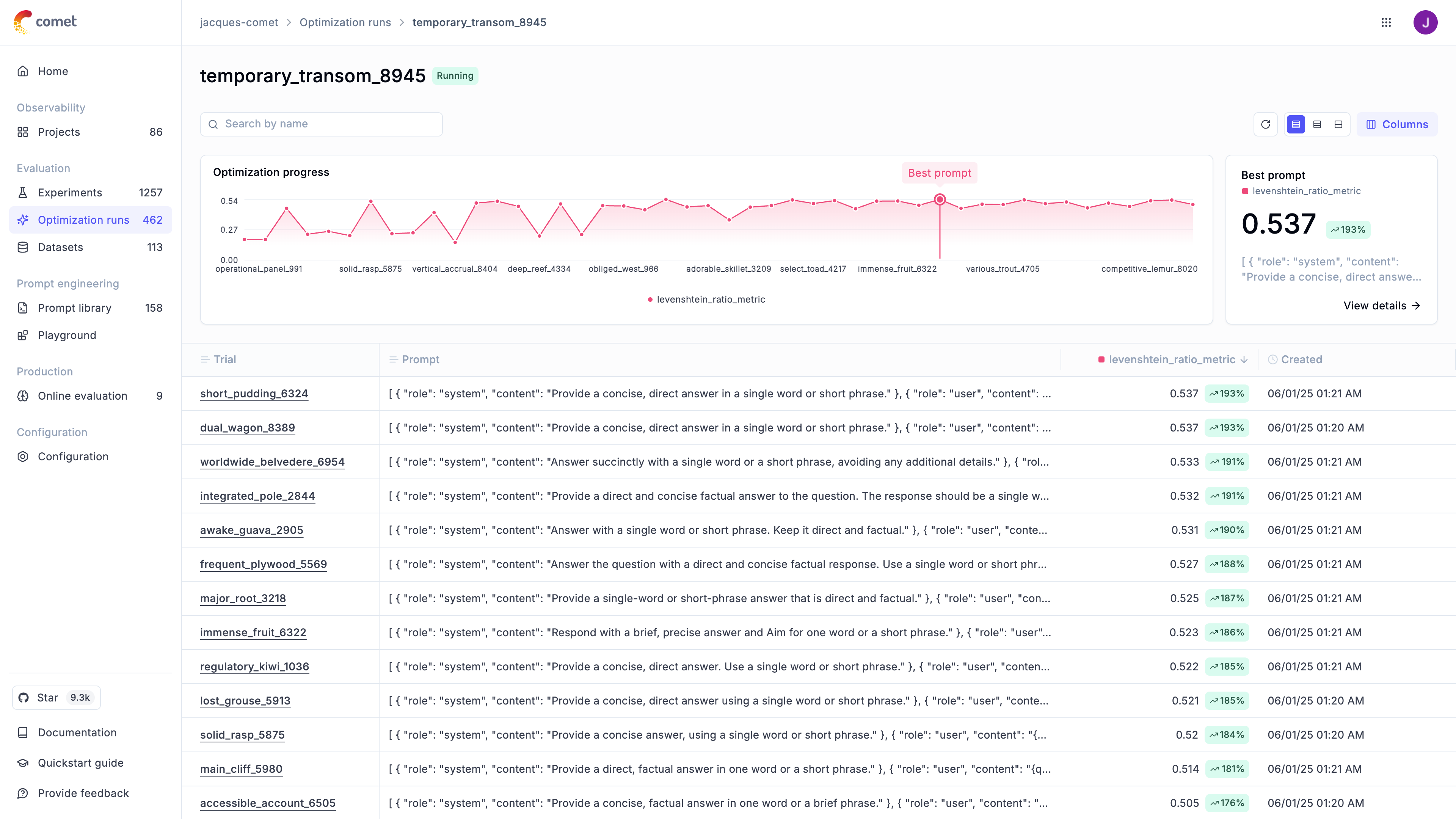
Optimization Algorithms
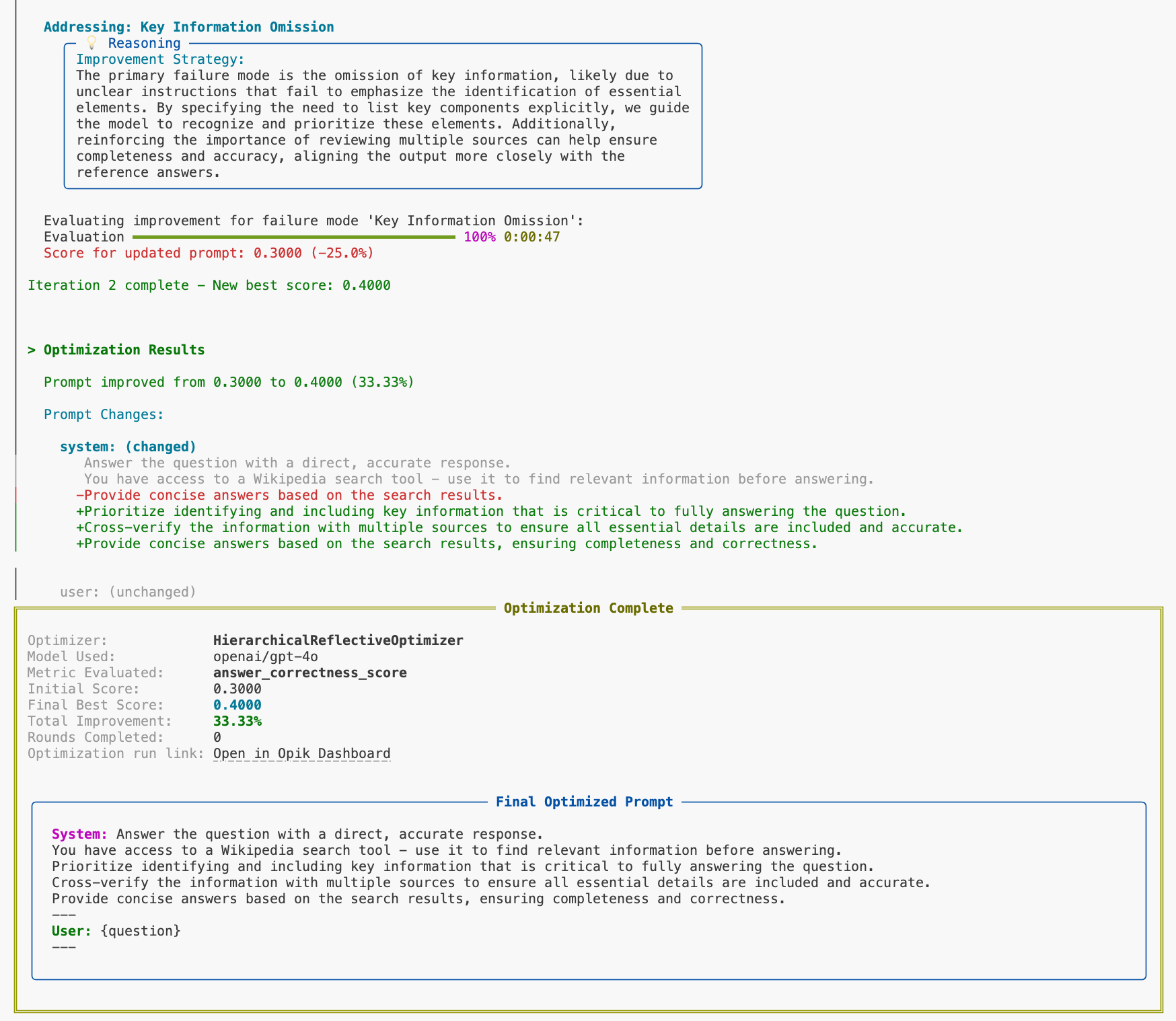
The optimizer implements both proprietary and open-source optimization algorithms. Each one has it’s strengths and weaknesses, we recommend first trying out either GEPA or the Hierarchical Reflective Optimizer as a first step:
If you would like us to implement another optimization algorithm, reach out to us on Github or feel free to contribute by extending optimizers.
Benchmark results
We are currently working on the benchmarking results, these are early preliminary results and are subject to change. You can learn more about our benchmarks here.
Each optimization algorithm is evaluated against different use-cases and datasets:
- Arc: The ai2_arc dataset contains a set of multiple choice science questions
- GSM8K: The gsm8k dataset contains a set of math problems
- medhallu: The medhallu dataset contains a set of medical questions
- RagBench: The ragbench dataset contains a set of retrieval (RAG) examples.
Our latest benchmarks shows the following results:
The results above are benchmarks tested against gpt-4o-mini, we are using various metrics
depending on the dataset including Levenshtein Ratio, Answer Relevance and Hallucination. The
results might change if you use a different model, configuration, dataset and starting prompt(s).
Next Steps
- Explore different optimization algorithms to choose the best one for your use case
- Understand prompt engineering best practices
- Set up your own evaluation datasets
- Review the API reference for detailed configuration options
🚀 Want to see Opik Agent Optimizer in action? Check out our Example Projects & Cookbooks for runnable Colab notebooks covering real-world optimization workflows, including HotPotQA and synthetic data generation.