
Understanding the concept of language models in natural language processing (NLP) is very important to anyone working in the Deep learning and machine learning space. They are essential to a variety of NLP activities, including speech recognition, machine translation, and text summarization.
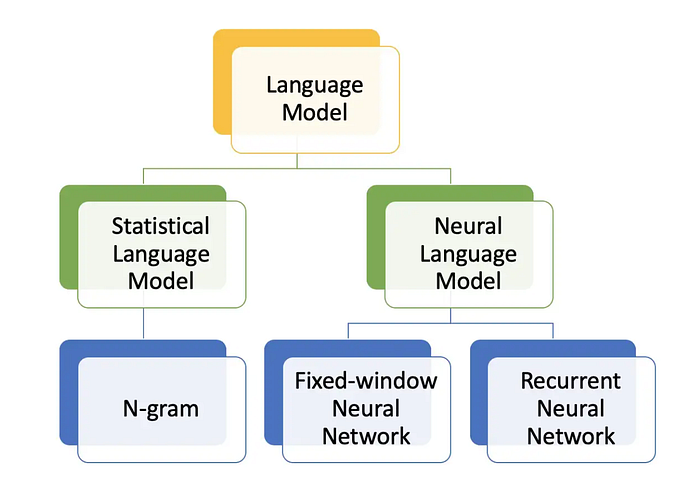
Language models can be divided into two categories:
- Statistical language models
- Neural language models
Statistical Language Models
Based on probability theory, statistical language models calculate the likelihood of a word sequence using statistical methods. To compute the likelihood of each word appearing given the words that came before it, these models often represent each word in the lexicon as a different number.
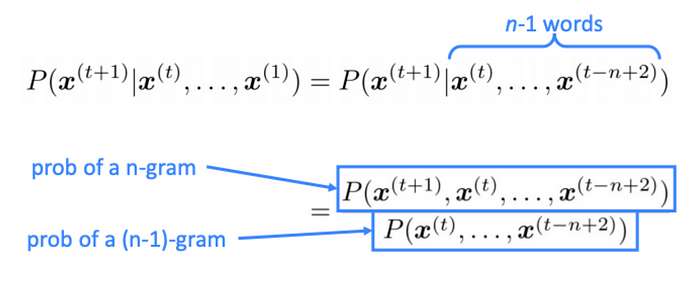
The n-gram model, which divides a string of words into overlapping groups of n consecutive words, or n-grams, is one of the most used statistical language models. A sentence like, “I am going to the grocery store,” would be represented by a series of 3-grams inclusing “I am going,” “am going to,” “to the grocery” and “the grocery store.” In a 3-gram model the model then calculates each 3-gram’s probability depending on how frequently it appears in the training data.
Neural Language Models
Neural language models make use of artificial neural networks to discover the patterns and structures in a language. Each word is often represented by a dense vector or embedding which captures the word’s context and meaning. The neural network receives the embeddings and uses them to process and forecast the likelihood of the next word in the sequence.
The ability of neural language models to handle vast vocabularies and intricate syntactic structures is one of its main features. They are particularly helpful for tasks like machine translation and text summarization because they can capture the context and meaning of words in a manner that statistical models cannot.
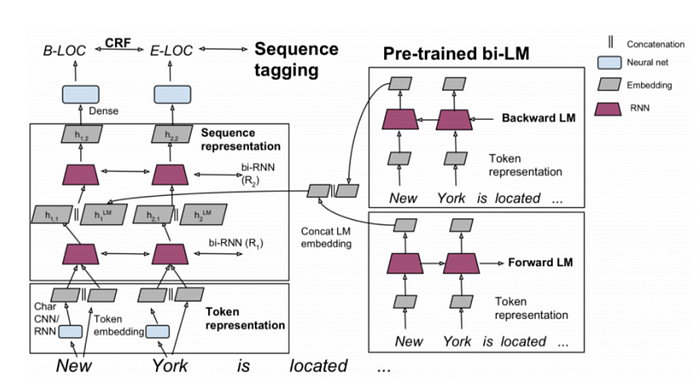
The long short-term memory (LSTM) model and the transformer model are two common neural language models that have been created recently. Recurrent neural networks (RNNs) can manage long-term dependencies in sequential data, and one such RNN is the LSTM model. Memory cells are specialized units that can store and retrieve data from earlier time steps, LSTM models have been applied to a variety of NLP applications, such as text production and language translation.
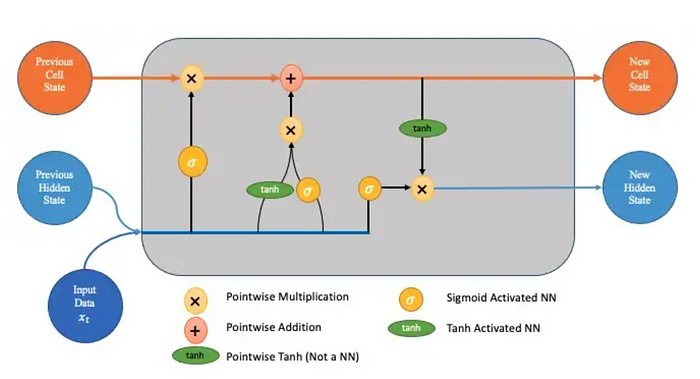
On the other hand, the transformer model is a type of self-attention model that may learn the relationships between words in a sequence without the use of recursion. It accomplishes this by utilizing a multi-headed attention mechanism that enables the model to focus on various input sequences segments at various times. For applications including language modeling, text classification, and translation, transformer models have been utilized. These two primary categories of language models are supplemented by hybrid models, which combine the benefits of statistical and neural models.
How does the team at Uber manage to keep their data organized and their team united? Comet’s experiment tracking. Learn more from Uber’s Olcay Cirit.
Development of language models
NLP has seen a lot of growth and advancement over the past few years due to research breakthroughs in machine learning and deep learning. One of the areas that has seen significant growth is language modeling.
Classical statistics were initially used in language modeling. Examples of this include the n-gram models and hidden Markov models. These models were very revolutionary at the time but they had a lot of limitations, lik struggling to capture long-range dependencies between words. In the early 2000s, the Neural Probabilistic Langauge Model (NPLM) was the first type of neural network-based language model and it began to gain recognition.
One of the most popular language models is the Recurrent Neural Network Language Model (RNNLM). These models are able to capture long-range dependencies using a newly designed architecture. Currently, there’s a lot of development in this field from BERT to GPT-2 and these models are pre-trained on very large corpora. In the coming years, we will experience very advanced growth in this field.
Choosing the right language model for NLP
Choosing the perfect language model for an NLP task is based on various factors, from the size of the dataset, to the computational resources available and how complex the task is. For a task like sentiment analysis, pre-trained models will work well and you’ll just need to tune the model on a small dataset to work for sentiment analysis.
For complex tasks like text summarization, training a custom model is stressful but using models like BERT, and GPT-2 with the right-sized dataset and computational resources will allow you to evaluate various models to pick one that solves your problem very well.
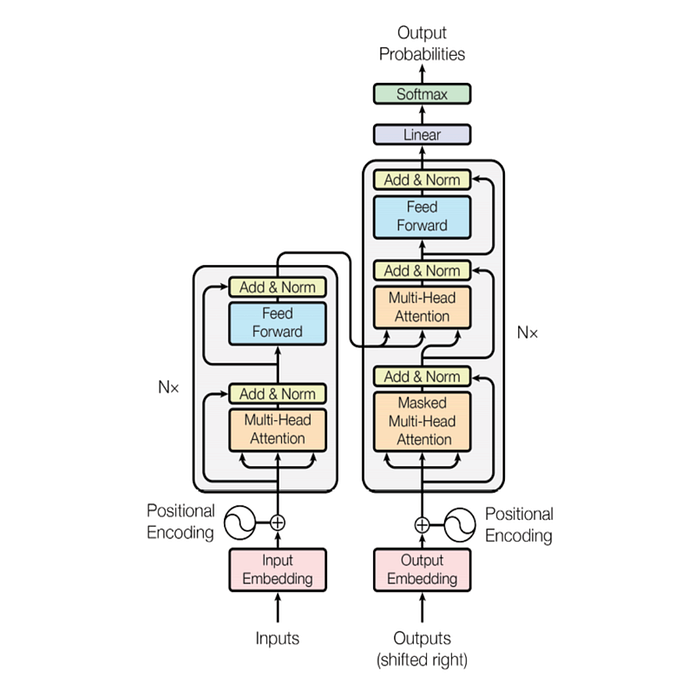
For instance, the GPT (Generative Pre-training Transformer) model is a neural language model that was pre-trained using a self-supervised learning methodology on a sizable text dataset.
Conclusion
The pre-trained model can then be enhanced for certain tasks, such as language translation or text summarization, by inserting task-specific layers on top of it. One of the key challenges in building language models is the need for large amounts of high-quality training data. These models require tens of thousands, or even millions of sources of data. Hopefully, this tutorial gives you an idea of the concept of language models to help you build better NLP models.
