Your customer service agent correctly retrieved order details, checked your return policy, verified the return window and initiated the return process. Unfortunately, it sent the customer a tracking label for a different order. You spend three hours manually reconstructing 15 tool calls across three specialized agents to find where the handoff broke down.
Research from UC Berkeley analyzed more than 1,600 execution traces across seven multi-agent frameworks to reveal failure rates up to 86.7 percent. The research identifies that failures cluster into three categories:
- system design issues
- inter-agent misalignment
- task verification problems
Traditional logging cannot effectively catch these coordination and specification challenges.
As these systems evolve to include agents that modify their own behavior based on performance feedback, the LLM observability challenge intensifies. Your healthcare prior authorization agent that processes hundreds of claims daily doesn’t just coordinate with other agents; it continuously refines its understanding of payer-specific requirements. When a failure occurs Thursday, debugging requires understanding not just what happened but how the system changed since Wednesday’s successful runs. You need a solution that continuously instruments AI agent tracing across your dev environment as it evolves.
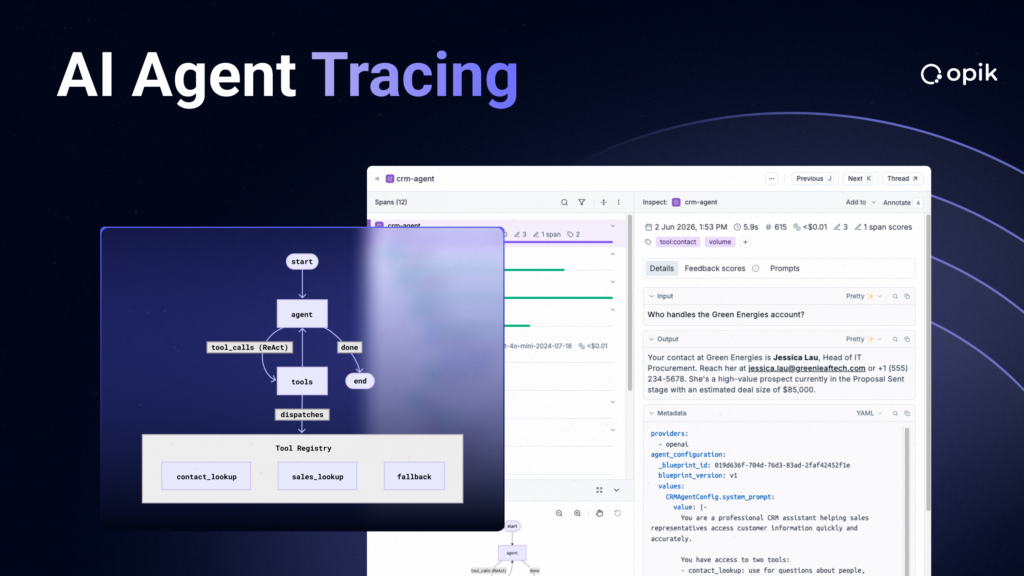
Why Simple Tracing Breaks for Multi-Agent Systems
Simple LLM traces capture discrete events, such as receiving the request, calling the model, querying the database and returning a response. This logging approach works when debugging systems where behavior remains constant between observations and failures happen in isolation.
Multi-agent systems fundamentally break this model. First, these systems distribute decision-making across autonomous components that must coordinate without centralized control. Second, when agents can modify their own behavior based on performance feedback, the system you’re debugging today differs from the system that failed yesterday.
The Multi-Agent Coordination Problem
A healthcare agent automating prior authorizations coordinates decisions across patient eligibility verification, medical necessity determination and billing code validation. A single authorization might require 12 LLM calls, 8 database queries and 5 external API calls distributed across three specialized agents.
When this system produces an incorrect denial, traditional logs show each step completed successfully. The eligibility agent confirmed coverage. The medical necessity agent validated the procedure. The coding agent aligned treatment codes. Yet the final authorization was denied due to missing documentation that should have been flagged earlier in the workflow.
According to Berkeley’s research, inter-agent misalignment failures cause 32% of failures in multi-agent systems. As agents pass messages back and forth, context windows fill with intermediate outputs and critical information from earlier decision points gets truncated. The eligibility agent’s confidence score about coverage doesn’t make it to the medical necessity agent because the context window is filled with detailed policy text from the retrieval step. Without visibility into how context degrades across agent boundaries, you’re blindly debugging the errors.
If your production team wants to reduce agent debugging time, you need more than basic logs. A purpose built AI agent tracing platform provides visibility into coordination patterns, like which agent talks to which agent, what information gets passed, where data gets lost and how failures cascade, your team can reduce the time required to improve agents.
Failures After Agents Modify Themselves
The coordination challenge compounds when agents autonomously modify their own behavior. Research on self-evolving agents identifies that “agents accumulate knowledge and develop expertise, making each instance unique and increasingly difficult to update or replace.” You have less control over how the agents reach the requested outcome.
Let’s look at the healthcare authorization system that runs for three weeks. The medical necessity agent refines its retrieval strategies based on observed patterns because the agent learned that a specific payer approves requests faster when documentation includes certain clinical codes. One day, denials suddenly spike for that payer.
Traditional logs show the failures but not the agent’s learning event that changed the behavior. The retrieval query used a prompt the agent auto-generated based on performance feedback. To debug the modified agent, you must be able to identify the original strategy, determine which pattern triggered the modification, decide if the learned strategy worked for one specialty while failing for others and learn if the change broke assumptions other agents depend on.
When one agent modifies itself, coordination complexity multiplies. The medical necessity agent updated its documentation requirements, but the coding agent still uses last month’s validation logic. What was working as a coordinated system becomes misaligned by an agent’s autonomous learning.
The Three Pillars of AI Agent Tracing
Effective agent observability for multi-agent systems requires three pillars: structured trace trees, semantic context capture and cross-agent correlation. Each pillar addresses coordination challenges first, and then extends to handle systems where agents modify their own behavior.
Structured Agent Trace Trees
Rather than organizing your agents as a flat event stream, set up your agent execution as hierarchical trees. With this design, each node represents a typed operation, such as LLM generation, retrieval lookup or tool call; each operation has parent-child relationships capturing the causal flow. The tree structure makes the causal chain explicit. Each decision point is visible with inputs, outputs and reasoning.
OpenTelemetry provides the industry standard for implementing trace trees. In OpenTelemetry, traces are defined as directed acyclic graphs (DAGs) of spans, where parent-child relationships create the hierarchical structure. Each span contains a unique span ID and a parent span ID. When passed to a child span, the parent’s span ID becomes the child’s parent identifier, establishing the tree relationship. All spans in a trace share the same trace ID, enabling complete request reconstruction across distributed agent systems. By default, major agent frameworks, including Pydantic AI, smolagents and Strands Agents, emit traces via OpenTelemetry, preventing vendor lock-in.
For self-evolving systems, trace trees extend to capture component versioning. Each span includes important metadata about which version of the prompt or tool configuration was active. When the risk assessment agent autonomously updates its volatility calculation logic, subsequent traces reference the new version while older traces remain linked to the previous implementation.
Semantic Context Capture
Traces show the sequence of operations. By capturing the semantic context, you can explain the reasoning behind the way agents are getting things done. This context includes the thought process agents used, the logic for selecting specific tools and numeric confidence scores.
Structured semantic context includes reasoning chains showing how agents reached specific decisions, tool selection logic explaining why particular APIs or databases were chosen over alternatives, confidence scores indicating certainty levels about outputs and memory access patterns revealing which historical context influenced current decisions in multi-turn interactions.
With version history, you can extend these capabilities to self-evolving systems. While debugging a failure, semantic context shows the current retrieval strategy, when it was last modified, what performance feedback triggered the change and whether the modification altered coordination with other agents. Without temporal versioning, debugging becomes archaeology where you attempt to reconstruct the system state from fragments.
Cross-Agent Correlation
Correlation connects individual agent behaviors into system-level patterns. Correlation IDs track requests across agent boundaries, enabling complete journey reconstruction even when agents run on different infrastructure. Correlation shows the cascade pattern, including coordination failures instead of the isolated timeouts from individual logs.
Context pollution emerges when one agent contaminates shared memory with incorrect data that propagates as subsequent agents make decisions based on it. Circular dependencies create deadlocks where the summarization agent waits for classification while the classification agent waits for summarization. Correlation reveals both processes are waiting on each other rather than showing two independent timeout issues.
Self-evolving systems introduce additional failure modes. Evolutionary divergence occurs when one agent’s autonomous updates break the assumptions other agents depend on. Correlation tracks how recommendation patterns shifted over time, revealing behavioral drift that individual successful tasks masked. This helps catch when agents misinterpret performance signals, leading to feedback loop pathologies that optimize toward the wrong objective.
Production Tracing for AI Agents: Three Critical Use Cases
How does this observability architecture translate into real world debugging? Explore these three use cases that show how trace trees, semantic context, and cross-agent correlation solve real coordination failures. These demonstrate why those capabilities become essential in various industries when agents start modifying themselves.
Health Insurance Claim Authorization
Healthcare organizations face elevated claim denial rates on first submission. When agents automate authorization workflows, failures stem from coordination breakdowns across eligibility verification, medical necessity determination and coding validation.
The claim is denied despite each agent reporting success. Agent trace trees reveal the causal chain: the eligibility agent retrieved patient data including a facility-specific procedure code, but the context window filled with policy text before reaching the medical necessity agent, truncating the facility code. The medical necessity agent searched using only standard CPT codes, found no matching documentation and triggered denial. The verbose output exceeded the context budget, so the agent lacked fallback search logic.
When your agent is learning autonomously, the medical necessity agent observes that successful authorizations for a specific payer included certain clinical codes. It modifies its retrieval strategy to prioritize these codes. In turn, denials spike. Trace analysis with temporal versioning reveals the learned pattern worked for orthopedic cases but fails for cardiology. When the agent overgeneralized what worked from one domain to all domains, it created more failures overall. Complete audit trails show how decision logic evolved, which patterns triggered modifications and whether changes stayed within clinical guidelines.
Fraud Detection and Advisory
Fraud detection systems deploy separate agents for transaction monitoring, behavioral analysis, risk scoring and alert generation. A legitimate international wire transfer triggers a false positive. Trace correlation shows the behavioral analyzer lost context about the customer’s travel notification, the risk scorer never received the transaction monitor’s confidence score and the alert generator had no visibility into recent identity verification. Three coordination failures compounded.
With autonomous learning, the behavioral analyzer tightens deviation thresholds after observing increased fraud. The risk scorer continues to use the previous calibration. False positive rate spikes. The agent trace analysis reveals evolutionary divergence because the behavioral analyzer modified its logic, but the risk scorer uses unchanged logic. The two agents no longer coordinate because one evolved while the other remained static.
Customer Service: Resolution and Escalation
Customer service agents coordinate across classification, retrieval, resolution and verification. A billing dispute gets misrouted to shipping. Trace trees show the classification agent’s decision was borderline correct, but subsequent agents had no visibility into this uncertainty. To fix this coordination issue, propagate confidence scores and retrieve both order and billing details when classification confidence falls below a defined confidence score.
When agents are learning autonomously, these issues compound. The classification agent observes that escalated queries receive higher satisfaction scores. It interprets this as escalation produces better outcomes. The agent lowers its escalation threshold confidence. Autonomous resolutions decrease; escalations increase. The agent optimized toward the wrong objective because it learned escalation correlates with satisfaction but missed the causal relationship.
Standardizing AI Agent Observability
Observability was fragmented across vendor-specific formats. Some use a proprietary agent while others use their own instrumentation library. Open-source tools added to the complexity by using Thrift versus gRPC, JSON over HTTP, or a proprietary remote write protocol. Switching between these options meant rewriting instrumentation across every service. Teams maintained separate instrumentation codebases for different backends or committed to a single vendor despite changing needs.
OpenTelemetry provides standardization. You can now write instrumentation once using the vendor-neutral SDK. The telemetry flows to any backend, allowing you to switch between tools with minimal configuration. You can send traces to multiple backends without touching application code.
OpenTelemetry’s Semantic Conventions establish standardized schemas for LLM applications. When you set gen_ai.request.model, every compatible platform recognizes this as the language model. The attribute gen_ai.usage.input_tokens consistently captures input token count across OpenAI, Anthropic and open-source models. Tool calls use standardized naming: gen_ai.operation.name = “chat”, gen_ai.tool.name = “web_search”. This consistency prevents vendor lock-in. Instrumentation written against OpenTelemetry conventions works across Langfuse, Arize Phoenix, Datadog LLM Observability and other platforms without modification.
OpenTelemetry defines three signal types:
- traces (distributed request flows)
- metrics (aggregated statistics about behavior)
- logs (discrete events with context)
The Collector sits between applications and backends, providing format conversion, batching, sampling and routing. This offloads export work from applications and enables Personally Identifiable Information (PII) redaction before telemetry leaves your network, which is critical for regulated industries.
Observability for Evolving Multi-Agent Systems
Framework-level auto-instrumentation provides the fastest path to observability. LangChain, LangGraph, CrewAI and AutoGen support OpenTelemetry through plugins. For agents with learning capabilities, SDK-based manual instrumentation offers control over version tracking and modification logging.
Instrumentation should capture agent boundaries, reasoning chains, tool selection and component versioning. When an agent modifies its own prompt, that becomes a versioned event in the trace. To balance depth with operational costs, measure results from 100 percent of failures and autonomous modifications and sample 10 percent of successful routine interactions. To ensure you are measuring the essential metrics, capture agent success rates, latency percentiles, token consumption, modification frequency and validation drift.
Common pitfalls can render your observability ineffective. This might look like instrumenting only successful paths even though failures and modifications reveal the most valuable patterns. Ensure you treat observability as a priority, not an afterthought. Other pitfalls include logging prompts without PII redaction, missing correlation IDs and failing to version agent components, which makes debugging self-modifications impossible.
While OpenTelemetry defines how to capture telemetry, it doesn’t determine which insights to extract. Raw traces show failure rates but don’t automatically surface that failures cluster around specific conditions, stem from particular coordination patterns or result from recent autonomous modifications. Converting telemetry into actionable insights requires an AI agent tracing platform that understands complex agentic behavior and tracks system evolution over time. This is where Opik shines.
Continuous Improvement Loops with Agent Tracing
While OpenTelemetry provides the portable instrumentation, observability for self-evolving multi-agent systems requires tracking not just what happened but how the system changed, what drove those changes and whether autonomous modifications remain safe. Purpose-built platforms must understand coordination patterns, reasoning chains, decision provenance and temporal evolution. Observability transforms operations from reactive to proactive.
Opik integrates agent observability, LLM evaluation and optimization for systems where agents modify themselves based on production feedback. When an agent autonomously updates its prompts, Opik captures the modification event, evaluates whether the change improved performance and flags behavioral drift outside defined safety boundaries.
Production traces capture what modifications occurred when and what feedback drove changes. Opik provides automatic agent trace capture with framework integrations for LangChain, OpenAI SDK, Anthropic, LLM-as-a-judge evaluation on production traces and optimization algorithms that systematically improve prompts while monitoring for validation drift.
With comprehensive agent debugging using Opik’s Ollie assistant, your team can reduce your resolution time. Multi-agent systems fail through patterns invisible to traditional logging, such as context collapse, coordination deadlocks, cascading errors and retry storms. When those systems also modify their own behavior, failures compound with validation drift, evolutionary divergence and feedback loop pathologies.
As Gartner predicts, by 2029 agentic AI will autonomously resolve 80 percent of common customer service issues. This transformation will require infrastructure that makes agent behavior visible, measurable and continuously improvable, especially as agents modify themselves based on production feedback. Comprehensive observability isn’t optional for self-evolving multi-agent systems. It’s the foundation that enables debugging coordination failures, validating autonomous modifications, maintaining compliance and ensuring reliability at scale.
Get started with Opik free to access integrated observability, evaluation and optimization built specifically for multi-agent systems with learning capabilities. The open-source platform provides full trace capture, temporal versioning, LLM-as-a-judge evaluation and automated drift detection from day one.
