Machine Learning Operations
Your Ultimate Guide to Hyperparameter Tuning
Hyperparameter tuning is essential when optimizing your machine learning model’s performance. Here you’ll learn what it is, why it’s so important, and how to incorporate it with Experiment Tracking tools like Comet to gain deeper insights into your projects.
Table of Contents
- What is a Hyperparameter?
- Why Hyperparameter Tuning Matters
- Parameters vs. Hyperparameters: What’s the Difference?
- What is Hyperparameter Tuning?
- Hyperparameter Optimization Techniques
- What Are Some Challenges of Hyperparameter Tuning?
- What Makes Comet a Good Tool For Hyperparameter Tuning?
- FAQ
- Our Bonus Resources
Introduction: Will this guide be helpful to me?
This guide will be helpful to you if you wish to:
- Learn more about hyperparameter tuning
- Learn how to log and track your hyperparameters
- Optimize your hyperparameters
What is a Hyperparameter?
A model hyperparameter is an external configuration set by the practitioner, whose value cannot be estimated by the data. Hyperparameters are often used to calculate model parameters, which are derived by the model during training. Hyperparameters control model structure, function, and performance.
Hyperparameters vary from algorithm to algorithm, and some are more important than others. The best way to learn more about the hyperparameters for your particular model is to consult your model’s documentation.
Why Hyperparameter Tuning Matters
Hyperparameter tuning allows data scientists to tweak model performance for optimal results. In one analogy, hyperparameters are like a bunch of really powerful knobs on a sound system; the slightest turn can make or break an algorithm. If, for example, your model struggles with exploding gradients, lowering the learning rate can keep your model from completely crashing.
And although many machine learning algorithms will run just fine on their default hyperparameter settings, but that doesn’t mean it isn’t important to optimize their values. Hyperparameter tuning can sometimes significantly improve model performance, but even small improvements in performance can make a big difference. Computer vision algorithms are used to detect buildings and pedestrians in self-driving cars, and even a 1% improvement in fraud detection accuracy can save a lot of money and customer headaches.
Parameters vs Hyperparameters: what’s the difference?
It’s important to make a distinction between a model’s parameters and hyperparameters before exploring the tuning process. Hyperparameter values are something that we set before training begins, whereas parameters are derived by the model or algorithm during the training process. The crucial differentiation lies in whether we set the value, or the model learns it.
Some examples of parameters include:
- Regression coefficients
- Cluster centroids
- Weights and biases of a neural network
Hyperparameter values affect a model’s parameters and, often, its overall performance. A few common examples of hyperparameters include:
- Learning rate
- Number of epochs
- Regularization terms
- Minimum number of leaves per decision tree node
- Neural network architecture
- Batch size
But not all hyperparameters directly affect model performance; some are also related to computational choices or what information to retain for analysis. Examples of these types of hyperparameters might include random seeds, the number of jobs executed in parallel, or whether to connect to a GPU or TPU. Tuning of this type of hyperparameter will depend mainly on the constraints of your particular experiment or resources, personal preferences, and desired output.
Put simply, hyperparameters are configurations the practitioner sets on a model before training. These values in turn affect the final parameter values learned by our model, all of which affects how our model performs.
What is Hyperparameter Tuning?
Hyperparameter optimization (or tuning) describes the process of choosing the optimal set of hyperparameters for a given algorithm, which often contributes to improved model performance. Hyperparameter tuning is considered a meta learning task.
Hyperparameter tuning is an iterative process of trial-and-error, but there are some general rules-of-thumb and best practices to help us get started. There are both manual and automated methods of hyperparameter tuning, but both involve running multiple trials on a specified range of hyperparameter values within a single training process. Once the optimal hyperparameter values have been determined from these trials, they are then applied to out-of-sample data.
Hyperparameter Optimization Techniques
Manual vs. Automated
Hyperparameters can be tuned manually or by automation. Manual hyperparameter tuning can be tedious, inefficient, and sometimes ineffective, but it does offer much more control over your model’s structure, function, and performance. Adhering to the scientific method means only changing one hyperparameter at a time, and so keeping track of what you have, or haven’t, changed quickly becomes overwhelming. Because manual optimization can be so time-consuming (and won’t always produce better results), automated hyperparameter tuning methods are much more popular.
Automated hyperparameter tuning uses algorithms to search for optimal values within a user-defined space. Automated methods are much faster than manual methods, but can still be incredibly time-consuming, depending on the size of your search space and dataset. Remember that the search space increases exponentially with each additional hyperparameter value.
Grid Search
With grid search, you specify a list of hyperparameters and an evaluation metric and the algorithm evaluates every possible combination of those hyperparameters before determining the best ones. Sometimes practitioners will run a small grid, see where the optimum lies, and then expand the grid in that direction. Grid search works well, but can be slow and extremely computationally expensive if not parallelized. It can be so computationally expensive, in fact, that unless you have a very small dataset and a small hyperparameter space to search, it quickly becomes impractical. Generally, grid search works best for spot-checking hyperparameter combinations that are known to work well together.
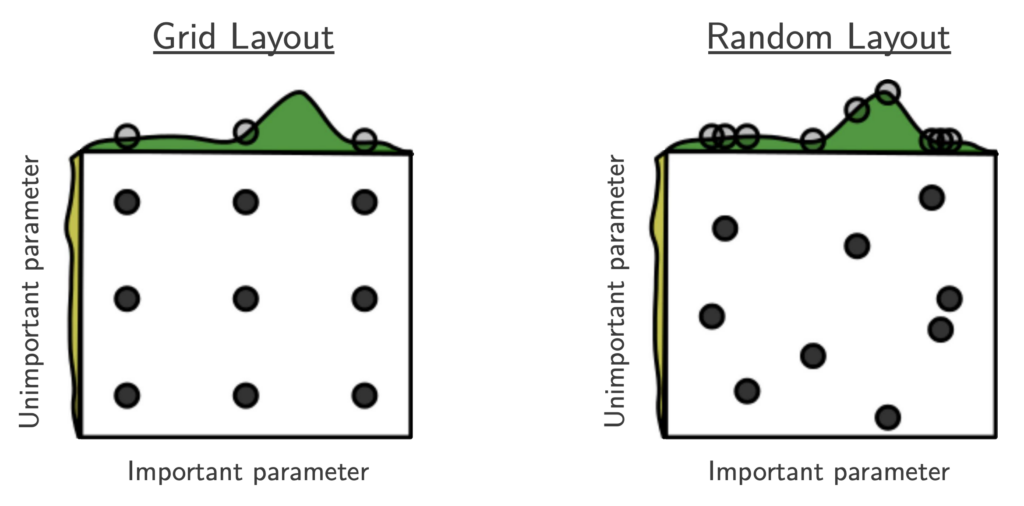
Random Search
Random search is a slight variation on grid search, where instead of performing an exhaustive search across all possible combinations of values, only a random sample of hyperparameter combinations is tested. This makes random search a lot less computationally expensive than grid search, but it, too, can become costly if the search space or dataset is large enough. Perhaps surprisingly, in many instances random search performs just about as well as grid search, as demonstrated in this paper from Bergstra and Bengio.
Bayesian Optimization
Bayesian optimization is a hyperparameter tuning method based on Bayes’ Theorem, which describes the probability of an event given some other event. Bayesian Optimization builds a probabilistic model from a set of hyperparameters and uses regression analysis to iteratively choose the best set of hyperparameters. Bayesian optimization has been shown to be particularly successful in distinguishing global maxima from local maxima and works well with computationally expensive objective functions.
What are Some Challenges of Hyperparameter Tuning?
Using the Wrong Metric
Remember that while hyperparameter tuning will optimize your evaluation metrics, if you’ve chosen the wrong evaluation metric, you may end up distancing yourself from your goal. One approach is to use multiple evaluation metrics to paint a broader picture of your model’s performance. Read more about how even Microsoft chose the wrong metrics in the early days of Bing, leading to a misinformed approach to optimizing search results.
Time and Computational Resources
The search space grows exponentially with the number of hyperparameters values, which can quickly consume computational resources and time. To reduce the complexity of your hyperparameter search space, try using Random Search, Informed (Coarse-to-Fine) Search, or Bayesian Optimization. It can also be helpful to reference the hyperparameter values used in similar projects as a starting point.
Overfitting
Conceptually, hyperparameter tuning is an optimization task, just like model training. So choosing to focus on maximizing training performance over validation performance, can lead to model overfitting. If your model’s performance on your out-of-sample data is much worse than on your testing data, you may want to consider whether you’ve overfit your model. To prevent overfitting your hyperparameters, you can employ many of the same techniques you might use to prevent overfitting your model, including cross-validation, backtesting, augmenting your data, and regularization.
What Makes Comet a Good Tool for ML Hyperparameter Tuning?
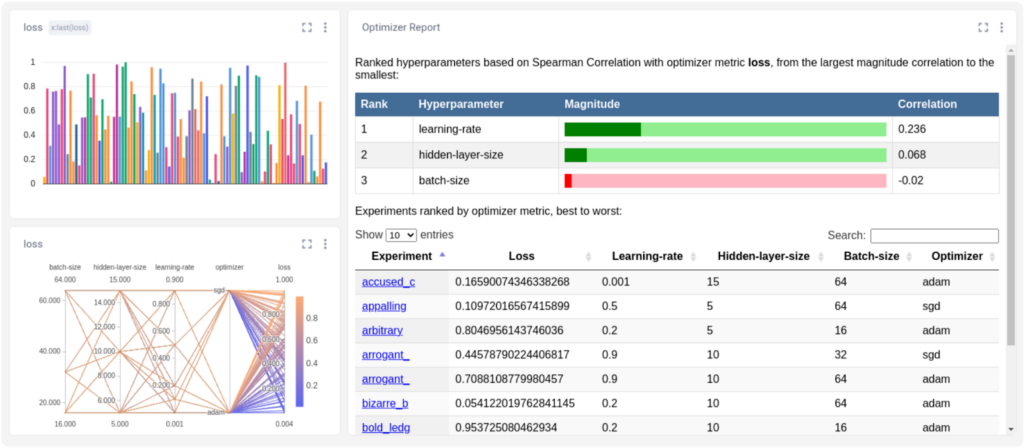
Tracking your metrics and hyperparameters and metrics can get tedious and overwhelming, quickly.Comet is a powerful tool that allows you to manage and version your datasets, track and compare training runs, and monitor your models in production — all in one platform. Because the Comet Optimizer integrates seamlessly with Comet Experiments, you can log, track, and manage all of your model’s hyperparameter values in one easy-to-use platform, where you’ll also have access to your other model metrics and outputs. The Comet Optimizer can run in serial, in parallel, or in a combination of the two.What’s more, the Comet Optimizer supports random search, grid search, Bayesian Optimization, or you can define your own optimizer. So no matter what your existing pipeline looks like, Comet’s got you covered!
Frequently Asked Questions (FAQs)
When does hyperparameter tuning happen in the ML workflow?
Hyperparameter tuning is an iterative process that occurs before training your model, but after splitting your data into train, test, and validation splits. Once you’ve found your optimal hyperparameter values and assigned them, your training can begin.
What are some common pitfalls of hyperparameter tuning?
The biggest mistake in hyperparameter optimization is not performing hyperparameter optimization at all. By relying on a model’s default hyperparameter settings, you are, at best, using suboptimal values. And at worst, you may be using values that are completely inappropriate for your problem at hand.
That said, some common mistakes when performing hyperparameter tuning are:
- Overfitting your optimizer
- Searching over too small, or too large, a hyperparameter space
- Using the wrong evaluations metrics
- Not considering the time and computational resources that some hyperparameter tuning methods require
- Data leakage
Why is hyperparameter tuning essential in ML?
Hyperparameter tuning is essential in ML because it allows you to squeeze out the very best performance from your model. If we don’t correctly tune our hyperparameters, our estimated model parameters produce suboptimal results, and our model will make more errors.
Is hyperparameter only for traditional machine learning or will my deep learning models benefit from it as well?
Hyperparameter tuning is possible (and encouraged!) for both traditional machine learning models, as well as deep learning models. Some examples of hyperparameters for deep learning models might include:
- Number of layers
- Number of nodes per layer
- Learning rate
- Number of epochs
- Regularization
- Step size
- Weight decay
- Momentum
- Batch size
How do I know which hyperparameters to set?
The best way to learn more about which hyperparameters your model accepts is to consult the model’s documentation. Some domain knowledge may be necessary to determine which hyperparameters are most relevant to your particular task, but oftentimes it can be helpful to consult solutions to similar problems as a starting point.
What is open source hyperparameter tuning?
Open-source hyperparameter tuners are free, customizable, and come with support from the community. However, they’re hard to scale and can make it challenging to work collaboratively within a team. What’s more, there’s often a lack of expert support, as well as less security.
How can I integrate Comet into my current tuning system?
It takes as few as two lines of code to integrate Comet into your current tracking system, just sign up for your FREE Comet account today.
For more information on setting up the Comet Optimizer in your workflow check out our Optimizer documentation here.
What types of hyperparameter tuning does the Comet Optimizer support?
The Comet Optimizer currently supports the three most popular methods of automated hyperparameter tuning: grid search, random search, and Bayesian optimization. But you can also use any third-party optimizers, or define your own!
Is there a Google Colab example of the Comet Optimizer?
Yes! Try out the Comet Optimizer in this Google Colab.
Does Comet have a demo?
Yes, Comet offers demonstrations. Simply fill out the online form to talk to our sales team and schedule your demo.