
In the previous article, you were introduced to the intricacies of data pipelines, including the two major types of existing data pipelines. You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines. In the second part of this series, you will delve into the core components of Apache Airflow and gain insights into building your very first pipeline using Airflow.
A quick recap about Apache Airflow from the previous article is that Apache Airflow is an open-source workflow management platform for managing data pipelines. Also, the pros of Airflow are the ease of building data pipelines, setting up and orchestrating complex data workflow with zero cost, and integrating data pipelines with modern cloud providers. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex data pipelines.
Diving Deep into the Inner Working of Apache Airflow
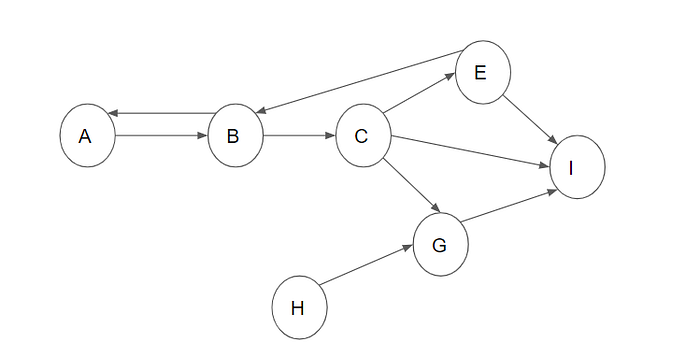
The primary concept behind Airflow is what’s called Directed Acyclic Graph. The Directed Acyclic Graph is a graph structure in which connection is done sequentially without a loop, i.e., the last node in the graph is not connected to the first node. The image below shows an example of DAG; the graph is directed, information flows from A throughout the graph, and it is acyclic since the info from A doesn’t get back to A.

The opposite of a DAG is a Directed Cyclic Graph, where there is a bidirectional movement (connection) between the graph nodes. This type of graph creates a loop in which one or more nodes are connected. The below image shows an example of a directed cyclic graph; if you notice, node A is connected to B, and node B is also connected to A. Regarding the movement of data, point B depends on the data from A, and funnily enough, A depends on the data from B.
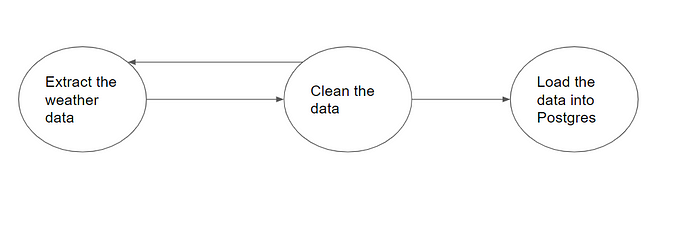
Now that you have learned about DAG and DCG, you might wonder why DAG is important to Airflow. To understand this, imagine you have a pipeline that extracts weather information from an API, cleans the weather information, and loads it into a database. Imagine, if this is a DCG graph, as shown in the image below, that the clean data task depends on the extract weather data task. Ironically, the extract weather data task depends on the clean data task. This creates an endless loop in which the extract weather task can’t start receiving input from the clean data task, but the clean data task also needs the extract weather data to finish running before it can begin.
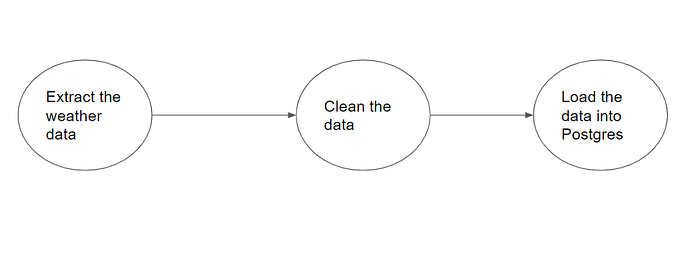
So, how does DAG solve this problem? Well, DAG solves the problem by ensuring that the clean data node doesn’t communicate back to the extracted weather data node. In the image below, you see that the clean data task will only run once the extract weather data task is done running, and the process continues till the end of the pipeline. Using DAG eliminates the weird loop that DCG created.
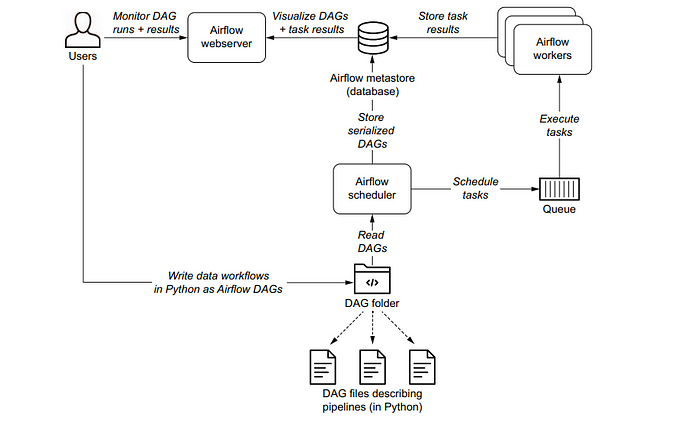
Given that you have understood the significant component that makes Apache Airflow powerful, the next step is to learn how Airflow manages these processes. How does Airflow know that extracting weather data is done executing and triggers clean the data, which is the next step? Well, that will be discussed below.
Airflow has four major components, which are
- The Scheduler
- The Worker
- A Database
- A web server
The four major components work in sync to manage data pipelines in Apache Airflow.
The Scheduler and Worker
To understand the scheduler, you need first to grasp the concept of how Airflow views DAGs. A DAG in Airflow comprises different tasks chained in an acyclic manner. The weather pipeline DAG includes the extract weather task, clean data task, and load data to the Postgres task.
DAGs in Airflow are defined with two major parameters: the scheduled date and the schedule interval. The date that the DAG is expected to be executed is the scheduled date, and the interval in which the DAG will be performed is the schedule interval, which can be hourly, daily, monthly, etc. Once the DAG has been created, Airflow sends it to the scheduling queue. The scheduler keeps track of the scheduled date and interval and triggers the execution of the DAG once the scheduled date has passed.
Technically, the date for scheduling the DAG is one day after the scheduled date, i.e., if the DAG execution date is 01–01–2023 00:00:00, the scheduler will schedule the dag on 02–01–2023 00:00:00. Once the scheduler triggers the DAG execution, it is sent to the worker for executing the dag. The worker will complete the first task in the DAG and communicate the result to the scheduler. If the development of the execution is a success, the scheduler will trigger the next job in the DAG since the second task depends on executing the first task. In case the result of the first task execution is a failure, Airflow won’t complete the following task since the task that it depends on is a failure.
Database
How does the scheduler keep track of the DAG and task execution? Well, that is where the database comes in. It acts as a storage system for storing information such as the scheduled date, schedule interval, the result from the worker, the status of the DAG, etc. The scheduler gets this information from the database and acts based on the information.
Web Server
The web server acts as a graphical user interface for viewing information about the DAG, such as the status of the DAG and the result from each task of a DAG.
Given that you now understand the core concept behind Airflow and the components that make up Apache Airflow, the next step is a practical hands-on.
Getting Started with Apache Airflow (Practical Session)
To get started with Apache Airflow, you need to install Apache Airflow. There are two significant methods of installing Airflow:
- Installing on your local laptop via PyPi
- Installing with Docker and Docker Compose
Installing Airflow with Docker and Docker Compose
The approach for installing Airflow in this tutorial is using docker. This is because the installation process is more straightforward with docker, and you can easily roll back to the default state without issues.
You can learn more with this link if you need to familiarize yourself with docker and docker-compose. If you have an idea about both but don’t have docker or docker-compose installed on your system, you can check out this link for installing both on Ubuntu. Windows and Mac have docker and docker-compose packaged into one application, so if you download docker on Windows or Mac, you have both docker and docker-compose. To install docker on Windows, check out this link, and use this link if you have a MacBook.
Once you have docker and docker-compose installed on your system, the next step is to create a directory(folder) on your system. You can name it airflow_tutorial for keeping the files for this tutorial. Change your directory into the airflow_tutorial folder and open the terminal on your system. The docker-compose.yaml file that will be used is the official file from Apache Airflow. To download it, type this in your terminal curl -LFO 'https://airflow.apache.org/docs/apache-airflow/2.6.1/docker-compose.yamland press enter. If you are on Windows/Mac, you might need to execute this in Gitbash shell to avoid issues with curl .
Modifying the Content of the docker-compose file
The docker-compose file from Apache Airflow is ideal for production. Hence, for this tutorial, that is not needed, and some configurations will be deleted and modified. The first thing to be changed is the type of Executor that Airflow will use. You might be wondering what an executor is. The discussion about executors was skipped above to avoid information overload while discussing the core components of Airflow.
Executors in Airflow determine how tasks are run once the scheduler schedules the task. Depending on your local system, you should run tasks in sequence or parallel if you have a high-end computer and your pipeline configuration. There are different types of Executors in Apache Airflow:
- SequentialExecutor — The sequential executor runs a single task at a time. The sequential executor runs inside the Scheduler, and it is the default for Apache Airflow. It executes the task on the same machine that the scheduler runs on, and in case of failure, the task will fail and stop running. Although it is easier to run, it is not ideal for production and is better for routine testing or learning.
- LocalExecutor — The local executor is similar to the SequentialExecutor, given that both the schedule, executor, and worker run on the same machine. However, the significant difference is that the local executor allows multiple tasks to be run simultaneously.
- There are other types of executors, such as the Celery Executor, Kubernetes Executor, Dask Executor, etc. These executors decouple the worker machine from the executor machine, so the worker will still process the DAG in case of failure on the executor machine.
Another question on your mind — when should you use the SequentialExecutor or other executors?
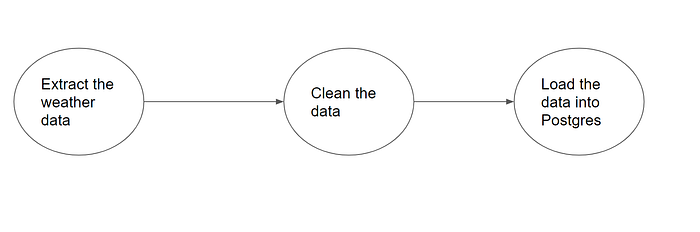
Use the sequential executor when running a single task per time and run it in sequence, as shown in the image below. In the picture below, you can see that the clean the datatask needs to run after the Extract the Weather Data Task. Hence, for this type of execution, you should use a SequentialExecutor.
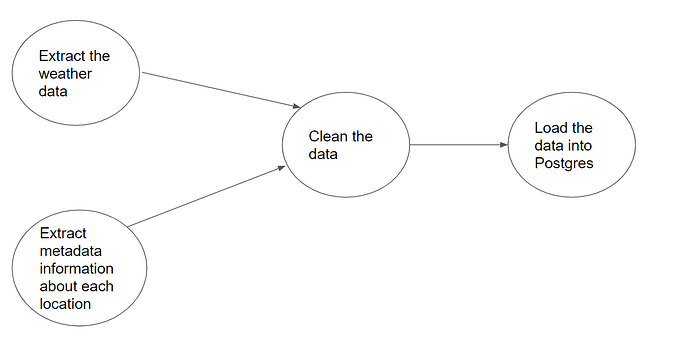
Use the other types of executors if you need to run tasks in parallel. You might need to extract the weather and metadata information about the location, after which you will combine both for transformation. This type of execution is shown below. In the image, you can see that the extract the weather data and extract metadata information about the location need to run in parallel.
The next thing that will be modified is the Apache Airflow image. This is necessary because additional Python modules need to be installed. The Airflow image doesn’t have the Open Weather SDK, pandas, psycopg2, and sqlalchemy required in the pipeline. So, the image has to be extended by including the necessary library and building a new image. The dockerfile below and the requirement.txt file will be used to develop the image.
# using the official docker image
FROM apache/airflow
# setting the airflow home directory
ENV AIRFLOW_HOME=/opt/airflow
#changing user to root for installation of linux packages on the container
USER root
# installing git(for pulling the weather API python SDK)
# build-essential and libpq-dev is for pyscopg2 binary
RUN apt-get update && apt-get install -y \
git \
build-essential \
libpq-dev
# create a working directory
WORKDIR /app
# copy the requirements.txt file that contains the python package into the working directory
COPY requirements.txt /app/requirements.txt
# change the user back to airflow, before installation with pip
USER airflow
RUN pip install --no-cache-dir --user -r /app/requirements.txt
EXPOSE 8080
pandas git+https://github.com/weatherapicom/python psycopg2-binary sqlalchemy
The dockerfile and the requirements.txt can be accessed with this link, or you can copy and paste the above text into a Dockerfile and requirements.txt file in your directory.
Building the Extended Apache Airflow Image
Once you have the dockerfile and the requirements.txt file, change your directory into the folder and type this in your terminal docker build -t extending_airflow_with_pip:latest . to build the image. You can choose to tag the photo with any name of your choice.
Once you finish the image build, you are ready to modify the docker-compose file.
image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.6.1} should be changed to image: ${AIRFLOW_IMAGE_NAME:-extending_airflow_with_pip:latest assuming you used extending_airflow_with_pip:latest it as the tag for the docker build.
AIRFLOW__CORE__EXECUTOR: CeleryExecutor should be changed to AIRFLOW__CORE__EXECUTOR: LocalExecutor . You can also change it to SequentialExecutor if you wish to use it.
Since you aren’t using a CeleryExecutor, you must delete the Celery worker and the Celery Flower lines. The celery flower is used for managing the celery cluster, which is not needed for a local executor. Go to the docker-compose file, delete the below configurations from the file, and save it. If you have an issue with which lines to delete, you can access the modified docker-compose file at this link.
# line 104 to 114
redis:
image: redis:latest
expose:
- 6379
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 10s
timeout: 30s
retries: 50
start_period: 30s
restart: always
# delete the airflow worker
airflow-worker:
<<: *airflow-common
command: celery worker
healthcheck:
test:
- "CMD-SHELL"
- 'celery --app airflow.executors.celery_executor.app inspect ping -d "celery@${HOSTNAME}"'
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
environment:
<<: *airflow-common-env
# Required to handle warm shutdown of the celery workers properly
# See https://airflow.apache.org/docs/docker-stack/entrypoint.html#signal-propagation
DUMB_INIT_SETSID: "0"
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
Starting Apache Airflow
Inside your working directory, create three sub-folders with the name dags for storing your dags, logs for storing the logs from the execution of tasks and scheduler, config for storing configurations, and plugins for storing custom plugins.
If you are on Linux, you need to ensure that the dags, logs, and plugins folder are not owned by root , but by Airflow. To confirm that Airflow owns the folder, type this in the terminal echo -e "AIRFLOW_UID=$(id -u)" > .env . This is optional on Windows and Mac, but you can choose to do that to suppress the warning from Airflow.
If you are on Windows/Mac, you must allocate memory to docker-desktop to avoid docker taking all the memory on your system. A rule of thumb is to give about 75% of your RAM size; if you use 8GB RAM, you can allocate 6 GB. You can check out this link to learn how to allocate memory to docker on Windows or Mac.
Type docker compose up airflow-init in your terminal to initialize the database and create the Airflow account. Once you are done, type the docker compose up command to start the Airflow services. To view the web server, type localhost:8080 on your browser and click enter. Once you click on enter, you will see an interface similar to the one below. Type in your username, which is airflow, your password, which is airflow, and click on the Sign In button.
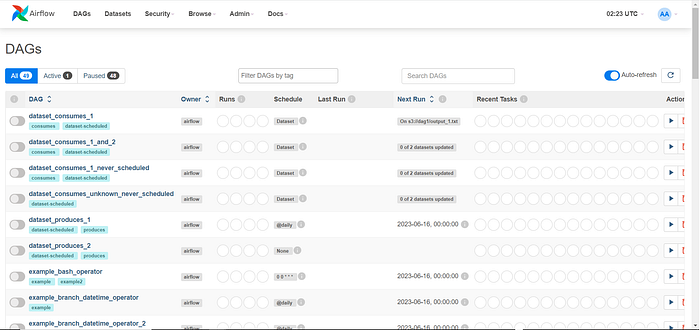
Once you have successfully logged in, you will be presented with a familiar interface that showcases a collection of example Airflow preloaded DAGs. As depicted in the image, these DAGs serve as practical illustrations and can serve as a starting point for your workflow creations.
Working with Example DAGS
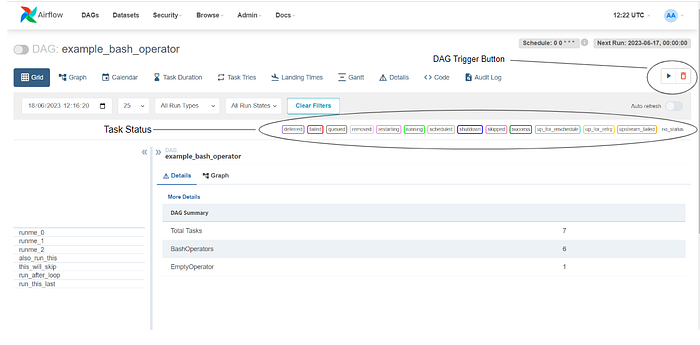
If you click the example_bash_operator DAG, you will see an image similar to the one below. The below image shows information about the DAG. You can check out this link to learn more about what is shown in the image below.
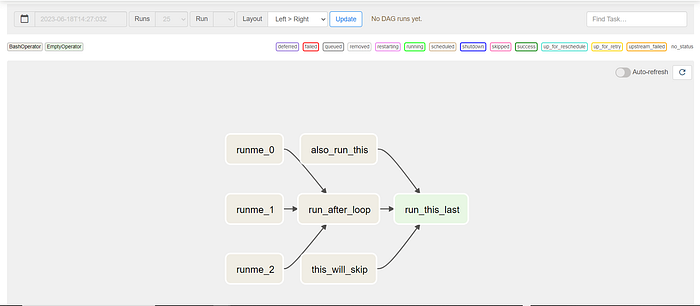
To view the structure of the DAG, you can click on the Graph button, which will show an image similar to what is shown below. The image below shows the design of the DAG, the logic, and the dependencies between the DAG.
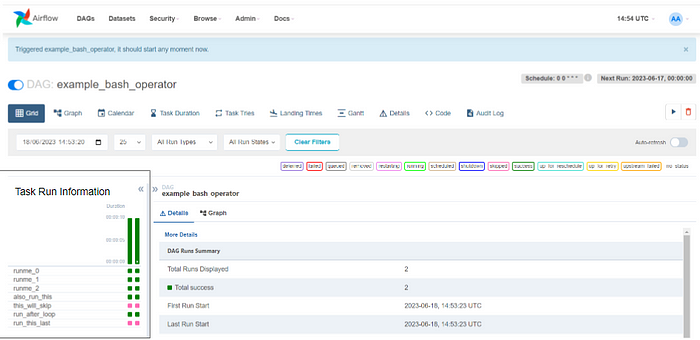
To trigger the DAG, click on the DAG Trigger Button , and click the Trigger DAGoption. Once you click on the Trigger DAG alternative, you will see an image similar to what is shown below, which displays the information about the DAG run. The dark green under the Task Run Information shows success, while the red is for failed tasks.
Writing your First Apache Airflow DAG
Before you write your first DAG, you need to understand what is required for writing a DAG in Airflow:
- Operators — Operators are the tasks needed to run an operation. If you want to cook anything, you need a Pot operator. If one of your tasks needs to perform a bash operation, use the BashOperator in Apache Airflow. Similarly, if you need to complete a Python process, you will need the Python operator.
- DAG object — This is needed to instantiate class.
The logic for your first DAG is this: you will write a DAG that will ingest a CSV file using pandas, save the file to your local Airflow directory, and clean up the directory afterward. If you think you will need the Python and Bash operators to write this DAG and define the task, then you are correct.
The first step in writing the DAG is to import the operators needed and the libraries used.
# importing the DAG class from airflow import DAG from airflow.operators.python import PythonOperator from airflow.operators.bash import BashOperator import os import pandas as pd from datetime import datetime, timedelta
The second step is to customize the DAG with information you know, such as the scheduled date, schedule interval, etc. For defining a DAG, you need the default_args. This dictionary contains information such as the owner of the DAG, the number of retries in case of failure of any of the tasks, and the time to wait before triggering the tasks again in case of failure, which is given by the retry_delaly argument.
You might be wondering why you have a default_args. They are arguments that can be reusable between different DAGs and help to save time. Other specific arguments are defined inside the DAG object, as shown below. The DAG object needs an ID to identify the DAG, a description, the start_date to schedule the DAG, the schedule interval, the default args, and the end_date. The end_date argument is optional, but if you don’t specify it, Airflow will keep scheduling your DAG.
By default, Airflow will start running a DAG from the start_date. The parameter that instructs Airflow to do this is the catchup parameter. If your start_date is 2021, then Airflow will start running from this time. To turn this off, you must set the catchup argument to False.
default_args = {
'owner': 'idowu',
'retries': 1,
'retry_delay': timedelta(minutes=2)
}
first_dag = DAG(dag_id='first_medium_dag',
description = 'A simple DAG to ingest data with Pandas, save it locally and clean up the directory',
start_date = datetime(2023, 6,19),
schedule_interval = '@once',
default_args = default_args,
end_date = datetime(2023,6,20),
catchup = False)
)
The next step is to define the variables used and write a Python function for downloading the CSV file, reading it with pandas, and saving it to the Airflow home directory. The dataset that will be used is from Sample Videos, a website that provides free CSV files for testing.
airflow_home = os.getenv('AIRFLOW_HOME')
dataset_link = 'https://sample-videos.com/csv/Sample-Spreadsheet-100-rows.csv'
output_file_name = 'sample_file.csv'
def download_file_save_local(dataset_link : str,output_file_name):
data_df = pd.read_csv(dataset_link)
data_df.to_csv(airflow_home + '/' + f'{output_file_name}', index=False)
The next step is to define the task objects for downloading the file, saving it locally, and cleaning it up. The two operators that you need for the task are Python and Bash operators. Both operators require a task ID and the DAG to be tied to each task.
The Python operator requires specific parameters, such as the Python function, to be called and the arguments to the function defined by the op_kwargs argument. The bash operator requires the bash_command argument, instructing it on what bash command to run.
download_file_save_local_task = PythonOperator(task_id = 'download_file_save_local_task',
python_callable=download_file_save_local,
op_kwargs = {'dataset_link':dataset_link,'output_location_file_name':output_location_file_name},
dag=first_dag)
clean_directory_task = BashOperator(task_id='clean_directory_task',
bash_command =f'rm {output_location_file_name}', dag=first_dag)
The final step is to define the dependency between each of the tasks. The initial logic is to call the task that will download the file, after which the clean_directory_task is called. There are two ways to set dependency in Airflow:
- Using the
set_upstreamfor defining the upstream dependency. In this scenario, the download_file_save_local_task is upstream to the clean_directory_task. An example of defining this isclean_directory_task.set_upstream(download_file_save_local_task. - Another option is to use the
set_downstreamfor defining the downstream dependency. The clean_directory_task is a downstream task for the download_file_save_local_task since it will be called after the downlaod_file_save_local_task. - For setting dependency upstream, you can use
<<the bitwise operator. For setting downstream, you need to use the>>bitwise operator.
To set the dependency between the two tasks, you can use the code below. This tells Airflow that the clean_directory_task should be run after the download_file_save_local_task runs.
download_file_save_local_task >> clean_directory_task
The complete code is shown below. You can copy and paste it into a file of your choice. The file should be located inside the DAG directory that you created earlier.
# importing the DAG class
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
import os
import pandas as pd
from datetime import datetime, timedelta
default_args = {
'owner': 'idowu',
'retries': 1,
'retry_delay': timedelta(minutes=2)
}
first_dag = DAG(dag_id='first_medium_dag',
description = 'A simple DAG to ingest data with Pandas, save it locally and clean up the directory',
# change the start_date to your preferred date
start_date = datetime(2023, 6,19),
schedule_interval = '@once',
default_args = default_args,
# change the end_date to your preferred date
end_date = datetime(2023,6,20)
)
airflow_home = os.getenv('AIRFLOW_HOME')
dataset_link = 'https://sample-videos.com/csv/Sample-Spreadsheet-100-rows.csv'
output_file_name = 'sample_file.csv'
output_location_file_name = airflow_home + '/' + f'{output_file_name}'
def download_file_save_local(dataset_link : str,output_location_file_name):
data_df = pd.read_csv(dataset_link, encoding= 'latin-1')
data_df.to_csv(output_location_file_name, index=False)
print(data_df.head())
download_file_save_local_task = PythonOperator(task_id = 'download_file_save_local_task',
python_callable=download_file_save_local,
op_kwargs = {'dataset_link':dataset_link,'output_location_file_name':output_location_file_name},
dag=first_dag)
clean_directory_task = BashOperator(task_id='clean_directory_task',
bash_command =f'rm {output_location_file_name}', dag=first_dag)
download_file_save_local_task >> clean_directory_task
Viewing your first DAG
To view your DAG, go to the web server and search for the dag with the name first_medium_dag . This is the variable that was passed to the dag_id. Once you find the DAG, click on it to see something similar to what is shown below.
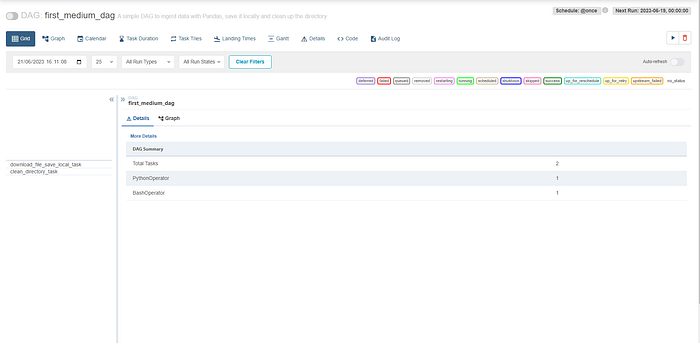
Click on the trigger dag button and you will see an image similar to what is shown below. The image below shows that the two tasks were successfully run based on the color.
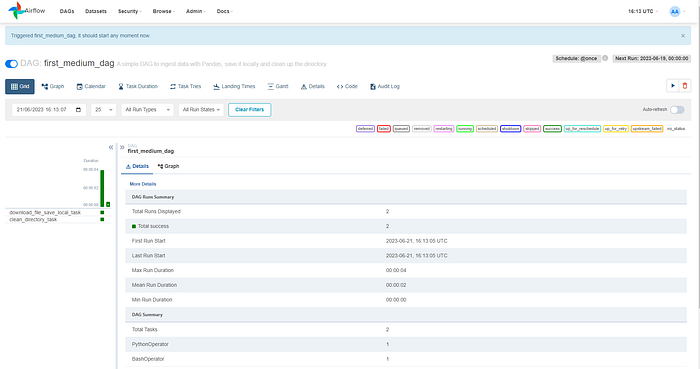
You can check the task logs by clicking on the task and clicking on records. Also, you can go through the interface and see the result of your first written DAG run.
Now you have understood the nitty-gritty of Apache Airflow, its internals, how to trigger a DAG, write a DAG from scratch, and run it. You have come to the end of the second article in this series.
Conclusion
The second article in this series has provided you with a comprehensive understanding of the inner workings of Airflow and the key components that drive its functionality. You have learned how to trigger a DAG in Airflow, create a DAG from scratch, and initiate its execution. In the upcoming part of this series, we will delve into advanced concepts of Airflow, including backfilling techniques and building an ETL pipeline in Airflow for data ingestion into Postgres and Google Cloud BigQuery.
You can connect with me on LinkedIn or Twitter to continue the conversation or drop any query in the comment box.
References / Further Resources
- Astronomer Documentation on Apache Airflow — https://docs.astronomer.io/learn/category/airflow-concepts
- A comparison between Apache Airflow Executors — https://maxcotec.com/learning/apache-airflow-architecture/
- Types of Executors in Apache Airflow — https://medium.com/international-school-of-ai-data-science/executors-in-apache-airflow-148fadee4992#:~:text=Airflow%20executors%20are%20the%20mechanism,execute%20tasks%20serially%20or%20parallelly.
- A deep dive into creating a DAG in Airflow — https://marclamberti.com/blog/airflow-dag-creating-your-first-dag-in-5-minutes/?utm_content=cmp-true
- Apache Airflow Official Documentation on Airflow — https://airflow.apache.org/docs/apache-airflow/1.10.6/tutorial.html?highlight=email
- Data Pipelines with Apache Airflow E-book (Highly Recommended ) — https://www.manning.com/books/data-pipelines-with-apache-airflow
