Deep Learning’s Emissions Problem
In the summer of 2019, a group of researchers led by Emma Strubell at the University of Massachusetts Amherst published a study which estimated that training a single deep learning model can produce up to 626,155 pounds of CO2 emissions. As a sobering point of comparison, this amount is similar to the CO2 emissions produced by one average American over 17 years.
The model referenced in the paper happened to be GPT-2, the largest model available for study at the time. And while the average AI researcher is not training models on a scale similar to GPT-2 (or more relevantly today, GPT-3), the 2019 study underscored in harsh terms something the AI community had suspected for some time: that the carbon footprint of the computations involved in training machine learning models is a serious problem.
The problem is only getting worse. In our deep learning-centric research environment, advances in artificial intelligence are achieved largely through building bigger models, aggregating bigger datasets, and harnessing more compute power. Consider the leap from GPT-2 — considered state-of-the-art when it was released last year and built upon an eye-opening 1.5 billion parameters — to this year’s GPT-3, whose 175 billion parameters makes it more than 100 times the size of its predecessor. As larger models continue to drive progress in our field, the amount of energy consumed training them will grow as well. (To read more about why machine learning models consume so much energy, check out Rob Toews’ article in Forbes from earlier this year.)
A change in paradigm
In light of this information, what can researchers do to mitigate the carbon footprint of their research? The first step is to make the emissions associated with machine learning more accessible and transparent. And while there has been some promising work in creating tools in this space, as of present nothing has become the industry standard.
To that end, Comet has teamed up with some of the leading AI researchers and practitioners in the world — MILA, the AI research lab led by Yoshua Bengio in Montreal, BCG GAMMA, the Boston Consulting Group’s Analytics and Data Science division, and Haverford College — to create CodeCarbon, an open-source Python package to help researchers track the carbon footprint of their research. (You can read more about CodeCarbon in the official press release here.)


CodeCarbon records the amount of power being used by the underlying infrastructure from major cloud providers and privately hosted on-premises data centers. Based on publicly available data sources, it estimates the amount of CO₂ emissions produced by referring to the carbon intensity from the energy mix of the electric grid to which the hardware is connected. The tracker logs the estimated CO₂ equivalents produced by each experiment and stores the emissions across projects and at an organizational level. This gives developers greater visibility into the amount of emissions generated from training their models and makes the amount of emissions tangible in a user-friendly dashboard by showing equivalents in easily understood numbers like automobile miles driven, hours of TV watched, and daily energy consumed by an average US household. CodeCarbon also allows researchers to automatically download a LaTeX snippet with their emissions details to be added to research papers.
Getting Started with CodeCarbon and Comet
While CodeCarbon is an open-source package that can be used by anyone, users of CodeCarbon and Comet can take advantage of a built-in integration and visualization making it easy to track your carbon footprint in the same place as the rest of your research.
To get started, make sure you’ve pip installed both codecarbon and comet_ml (and make sure you’ve created a Comet account).
pip install comet_ml
pip install codecarbonFrom Comet, go to your account settings and get your API key.
Next, go to the CodeCarbon github page and grab the mnist-comet.py demo from the examples folder. As long as the codecarbon package is available in your environment, all you need to do is create a Comet experiment and the rest will happen automatically! (Note: you can disable codecarbon tracking by setting auto_log_co2 to False.) In mnist-comet.py, simply add in your API KEY (and project and workspace if you’d like) and execute the code.
experiment = Experiment(api_key = "YOUR API KEY")Back in the Comet UI for your experiment, navigate to the Panels tab and click Add New. From the Panel Gallery, click on the Public tab and search for “codecarbon”. The CodeCarbon Footprint panel will appear. Simply add this panel to your experiment, and you’ll see your emissions details automatically loaded into the panel. If you want to use this for subsequent experiments, simply save your ‘View’ and set it to default. Now when you run new experiments, the CodeCarbon Footprint panel will automatically populate your Panels tab.
You can also use the CodeCarbon panel at the Project level. Simply follow the same steps as above, but by accessing the Panel Gallery from the Project page. This exposes the Aggregate button, which will allow you to aggregate the emissions across many experiments (runs) you and your collaborators have contributed to a modeling task. To view the emissions of individual runs, simply toggle the ‘Select Experiment’ bar to the experiment you’d like to look at.
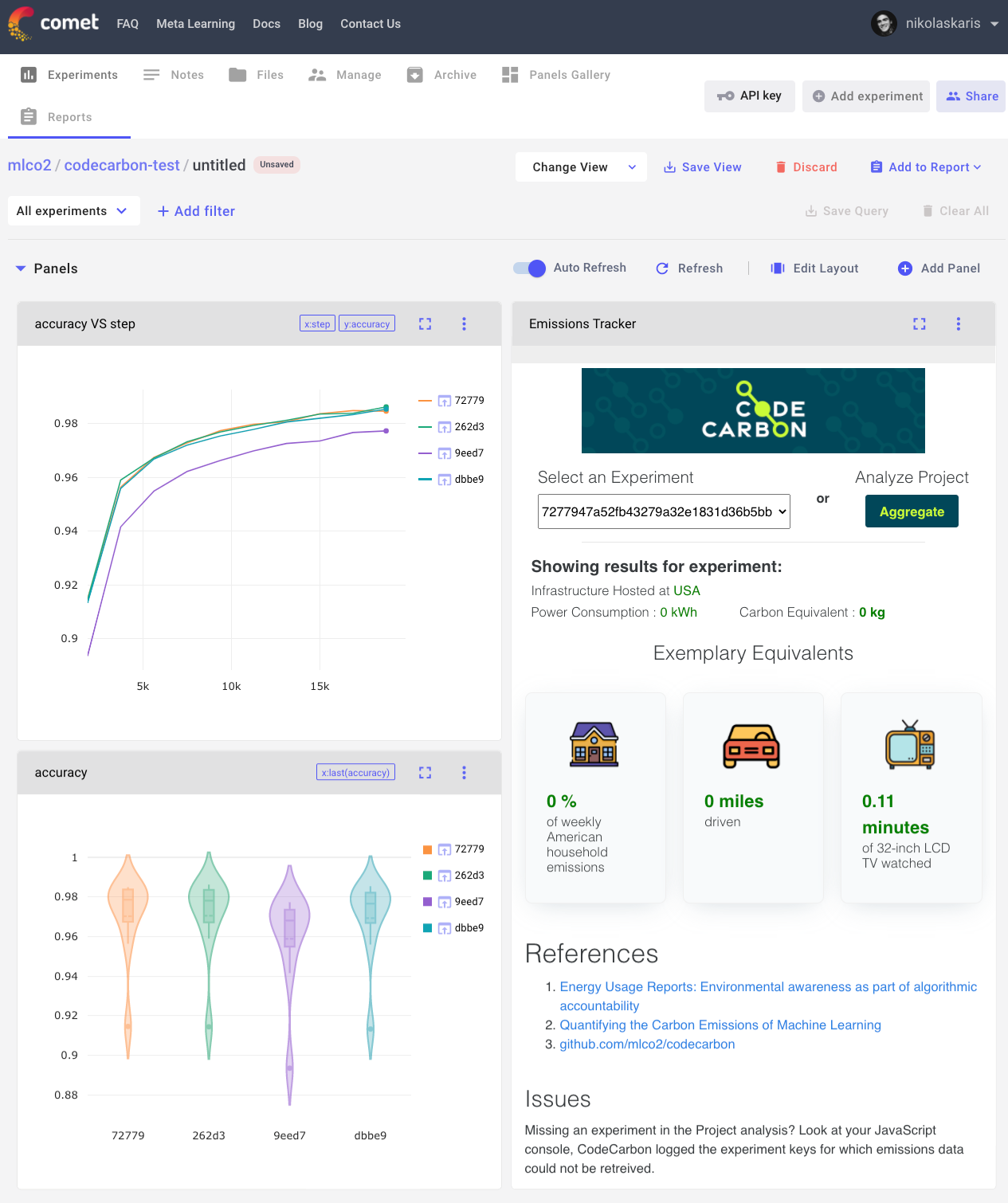

To see the Comet CodeCarbon panel live, check out this public project.
Looking Forward
While we believe CodeCarbon is a big step in the right direction for our community, it’s just the first step. CodeCarbon is open-source and the Comet integration is available and customizable to all Comet users; as such we’re excited for our community of developers and researchers to enhance both tools with new capabilities. We will be relying on all of you to help us create real change in the community by building a culture of reporting the carbon footprint of our research. CodeCarbon should make it easy to start doing this, and we hope you’ll consider publishing these findings with your next research paper, article, or technical blog post.
The climate damage caused by greenhouse gas emissions is evident. We hope that CodeCarbon helps our community understand artificial intelligence’s contribution to climate change, and perhaps that it helps inspire us to adopt new research paradigms in which mitigating emissions is treated as a crucial performance metric, not an afterthought.
