
Our lives have transitioned to revolve around Artificial Intelligence (AI) and Machine Learning (ML). Everybody is talking about it and it’s been implemented in our day-to-day tasks and actions without us even realizing sometimes.
They are the hottest topics right now, and everybody wants to know more. People throw the term “AI” around, from developers, companies, and even people who have no understanding; but are living in a tech-driven world.
Deep Learning
Deep Learning is a Machine Learning method that teaches computers to do what comes naturally to humans. It trains an algorithm to predict outputs, given a set of inputs. Supervised and Unsupervised Learning can be used with Deep Learning.
The hype about Deep Learning is due to the fact that Deep learning models have been able to achieve higher levels of recognition accuracy than ever before. Recent advances in deep learning have exceeded human-level performance in tasks such as image recognition.
So how does this method work that’s out-performing human-level?
The majority of Deep Learning methods use neural network architectures. You may hear Deep Learning is referred to as Deep Neural Networks sometimes. The term ‘Deep’ relates to the number of hidden layers in the neural network.
Neural Network
A Neural Network is a network of biological neurons. In the use of AI, Artificial Neural Network contains artificial neurons or nodes.
If we refer back to the definition of AI: the ability of a computer or a computer-controlled robot to perform tasks that are usually done by humans as they require human intelligence. We can connect the dots of a Neural Network being a structure of biological neurons, similar to the human brain.
So let’s dive into the brain of an AI.
Artificial Neural Networks (ANNs) are made up of neurons that contain three different layers: an input layer, one or more hidden layers, and an output layer. Each neuron is connected to another neuron and is where computation happens.
- Input Layer — receives the input data
- Hidden Layer(s) — perform mathematical computations on the input data
- Output Layer — returns the output data.
The term “Deep” in Deep Learning refers to more than one hidden layer.
Perceptrons
Perceptrons were introduced by Frank Rosenblatt in 1957. There are two types of Perceptrons:
- Single-layer: This type of perceptron can learn only learn a linear function, and is the oldest neural network. It contains a single neuron and does not contain any hidden layers.
- Multilayer: This type of perceptron consists of two or more layers. They are primarily used to learn more about the data and the relationships between the features on a non-linear level.
Consider each node as an individual linear regression model, which consists of input data, weights, a bias, and an output. The formula:
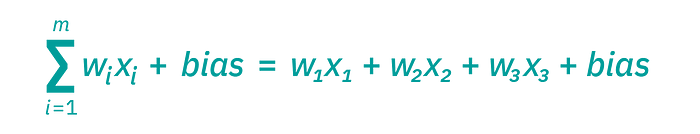
Where the output can be formulated as:
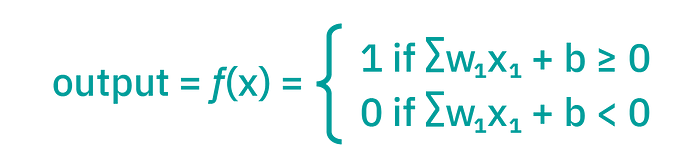
Perceptrons consist of:
- Input layer
- Weights and Bias
- Summation Function
- Activation Function
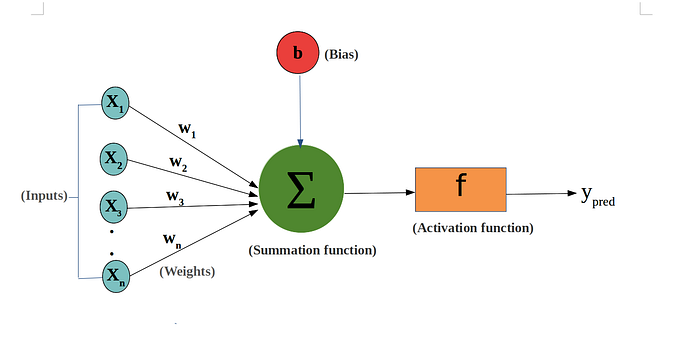
As we already know, the Input Layer is the layer that receives the input data.
The Weight controls the strength of the connection between two neurons. The weight is a big factor in deciding how much influence the input has on the output.
The Bias is constant and will always have a value of 1, and is an additional input into the next layer. Bias guarantees that there will always be activation in the neurons shifting the activation function to the left or right, regardless of the inputs being 0. They are not influenced by the previous layer, however, they have outgoing connections with their own weights.
The Summation Function phase is when all the inputs are summed up and bias is added to it. This can be formulated as:
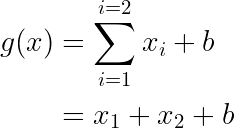
Activation Functions decide whether a neuron should be activated (fired) or not. This means that it will decide if the importance of the input is worth making a prediction on. They are very important in neural networks converging, and without them, the neural network would be made up of linear combinations. There are different types of activation functions which can be put into three main categories:
- Binary Step Function
- Linear Activation Function
- Non-Linear Activation functions
Non-Linear Activation functions include the Sigmoid function, tanh function, and ReLU function.
Binary Step Function
Binary Step Function produces binary output, either 1 (true) when the input passes the threshold limit. It produces 0 (false) when the input does not pass the threshold limit.
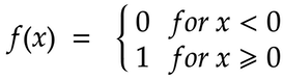
Linear Activation Function
Linear Activation Function is also commonly known as Identity Function. It is a straight-line function where the activation function is proportional to the input, which includes the weighted sum of the neurons, including bias.
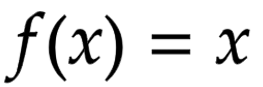
Non-Linear Activation Functions
Non-Linear Activation Functions are the most popular types of activation functions. This is due to many drawbacks with using Binary Step Function and Linear Activation Function. They make it easier for models to generalize data and be able to differentiate between the outputs.
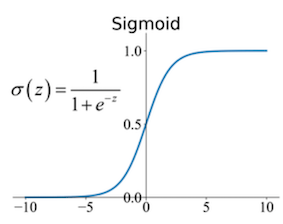
- Sigmoid Function: The input is transformed into values between 0 and 1.
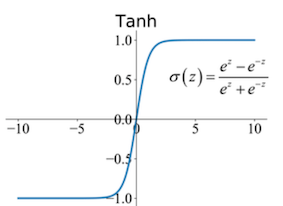
2. Tanh Function: The input is transformed into values between -1 and 1.
3. ReLU function: Short for Rectified Linear Activation Function. If the input is positive it will output it, however, if not it will output zero.
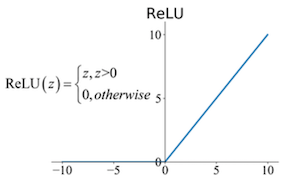
The Process
Once an input layer receives the data, weights are assigned. Weights help determine the importance of any given variable. The inputs are multiplied by their respective weights and then summed up.
At this point, our input has been multiplied by its respective weight and the bias has been added to it. The output is then passed through an activation function, which determines the output. If the output exceeds a given threshold, it activated the neuron, passing the data from one connected layer to another in the network.
The result in the next neuron now becomes the input for the next neuron. This process is called a feedforward network in a Neural Network as the information always moves in one direction (forward).
In Neural Network, there is also a process called Backpropagation, sometimes abbreviated as “backprop.” In Layman’s terms, Backpropagation is the messenger who tells the Neural Network whether it made a mistake when it made a prediction.
The word Propagate in this context means to transmit something, such as light or sound through a medium. To backpropagate is to send information back with the purpose of correcting an error. Backpropagation goes through these steps:
- The Neural Network makes a guess about data
- The Neural Network is measured with a loss function
- The error is backpropagated to be adjusted and corrected
When the network makes a guess about the data and causes an error, backpropagation takes the error and adjusts the neural network’s parameters in the direction of less error.
Want to get the most up-to-date news on all things Deep Learning? Subscribe to Deep Learning Weekly for the latest research, resources, and industry news, delivered to your inbox.
How does it know which direction to go into which has less error? Gradient Descent.
Gradient Descent
We need to understand Cost Function before we dive into Gradient Descent.
The Cost Function is a measure of how well and efficiently a neural network did with respect to its given training sample and the expected output. Cost Function shows us how wrong the AI’s outputs were from the correct outputs. Ideally, we want a Cost Function of 0, which tells us that our AI’s outputs are the same as the data set outputs.
The formula:
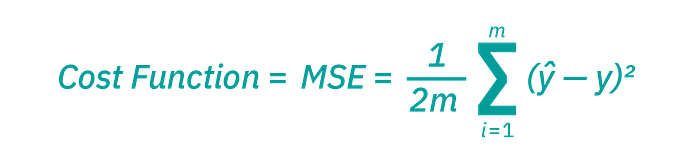
Gradient Descent is an optimization algorithm that is commonly used to train models and neural networks to help learn over time and reduce the Cost Function. Gradient Descent acts as a barometer, measuring its accuracy with each iteration of parameter updates.
A gradient is a slope, in which we can measure the angles. All slopes can be expressed as a relationship between two variables: “y over x”. In the case of Neural Networks, ‘y’ is the error produced and ‘x’ is the parameter of the Neural Network.
There is a relationship between the parameters and the error, therefore by changing the parameters we can either increase or decrease the error. We can use this to help us understand which gradient.
It is implemented by changing the weights in small increments after each data set iteration. Updating the weights is done automatically in Deep Learning, that’s the beauty of it and then we can see in which direction is the lowest error.
When should you use deep learning?
In order to understand if you should use deep learning, you should ask yourself these questions:
What is the complexity of your problem?
One of the biggest uses of deep learning is being able to discover hidden patterns within the data and get a better understanding of the relationship between the different interdependent variables. Deep learning is widely used for complex tasks such as image classification, speech recognition, and natural language processing.
However, some tasks are not as complex and don’t require the need to process unstructured data. Therefore classic machine learning is a more effective approach.
Is interpretability more important than accuracy?
Deep Learning eliminates the need for human feature engineering, however, model interpretability is one of the biggest challenges in deep learning. Deep Learning makes it difficult for humans to be able to understand and interpret the model.
Deep Learning has achieves a high level of accuracy. But this is where you ask yourself, is accuracy or interpretability more important to you?
Is your data good enough?
Although deep learning does not require human feature engineering, it still requires labeled data. A deep learning model is doing two jobs; feature extraction and classification. It eliminates the manual stage of Feature Extraction in a typical Machine Learning model done by a human. In order for Deep Learning models to handle complex tasks, they require a lot of labeled data in order for them to learn complex patterns.
Do you have the resources, time, and funds?
Deep Learning is expensive. This is due to their level of complexity using large amounts of data and layers to produce accurate effective outputs. Deep Learning models are also very slow to train, requiring heavy amounts of computational power. This makes them ineffective if your task is time and resource-sensitive.
What Deep Learning models already exist?
Below are the top 10 deep learning algorithms you should know about:
- Convolutional Neural Networks (CNNs)
- Long Short Term Memory Networks (LSTMs)
- Recurrent Neural Networks (RNNs)
- Generative Adversarial Networks (GANs)
- Autoencoders
- Multilayer Perceptrons (MLPs)
- Restricted Boltzmann Machines (RBMs)
- Radial Basis Function Networks (RBFNs)
- Self Organizing Maps (SOMs)
- Deep Belief Networks (DBNs)
Conclusion
Having a good understanding and grasp of the math behind Deep Learning will give you a better idea of when and when not to use Deep Learning. Appreciating the different Activation Functions and Cost Functions will help you produce the outputs you are looking for to solve your problem.
Deep Learning is getting more popular by the day. DL models are achieving higher levels of accuracy than ever before, some tasks better than humans. Therefore, I believe that it is important that everyone, not only Data Scientists, Machine Learning Engineers, and other programmers, have an in-depth understanding of how Deep Learning works.
