In this post, we’ll introduce Comet Artifacts, a new tool that provides Machine Learning teams with a convenient way to log, version, browse, and access data from all parts of their experimentation pipelines.
This post is divided into four sections:
- Challenge – We present the issues that PetCam, a fictional company, is having while trying to build a Pet Detection model.
- An Introduction to Artifacts as a Solution to PetCam’s problems
- Step-By-Step Guide: How PetCam can use Artifacts to debug their model
- Summary Discussion
You can try out the code for this example in this Colab Notebook.
1. The Challenge
PetCam is looking to build an app that identifies pets in photos. They build a classification model and tune a bunch of different hyperparameters, but are unable to meet their accuracy requirements.
To determine the root cause of this performance issue, PetCam creates a derivative dataset of the images that were difficult for all existing model versions.
How can PetCam iterate on both models and the derived datasets created by the models, in a way that’s reproducible and managed without losing track of their work?
In this scenario, we may want to track and reproduce the lineage of experiments, models, and datasets that are created iteratively over time.
2. Artifacts as a Solution
We’ve built Comet Artifacts to help Machine Learning teams solve the challenges like the one outlined above—iterating on datasets and tracking pipelines in which data generated from one experiment is fed into another experiment.
This need to track the datasets used or created by an experiment or model arises frequently. In many cases, ML teams must:
- Reuse data produced by intermediate or exploratory steps in their experimentation pipeline, and allow it to be tracked, versioned, consumed, and analyzed in a managed way
- Track and reproduce complex multi-experiment scenarios, where the output of one model would be used in the input of another experiment
- Iterate on your datasets over time, track which model used which version of the dataset, and schedule model re-training
Comet Artifacts enable us to more effectively and efficiently execute all of these tasks—we’ll explore how in the detailed guide in the section below.
But before we jump into the example, let’s start with a definition of an Artifact and an Artifact Version
An Artifact Version is a snapshot of files & assets, arranged in a folder-like logical structure. This snapshot can be tracked using metadata, a version number, tags and aliases. A Version tracks which experiments consumed it, and which experiment produced it.
An Artifact is a collection of Artifact Versions. Each artifact has a name, description, tags, and metadata.
With this important context covered, let’s jump right in and put Comet Artifacts to the test!
3. A Guide to Getting Started With Artifacts
Let’s return to the PetCam’s use case. Despite trying many configurations, the team hasn’t been able to build a model that achieves a suitable accuracy. In order to debug this, we’d like to isolate the set of examples that all model configurations are struggling with. This “difficult” dataset can then be used to inform future design decisions about the model.
Normally, we’d have to save the predictions made from each model, and then run an analysis script to isolate the examples. This works well if we only want to do this once. But what happens if we want to try a new method for selecting the difficult examples? Or rerun this workflow with an updated model design and compare the difficult samples across runs?
The iterative nature of ML makes it necessary to compare workflows and data over time. Manually attempting to track this quickly becomes a significant pain point.
For this example, we’ll build a pipeline to train and evaluate our pet classification model on the Oxford IIIT Pets Dataset, leveraging Comet Artifacts to better track, analyze, and reuse our data. To do this, we will:
- Fetch the raw data and apply some simple preprocessing
- Create an Artifact to track the data with Comet
- Train a model and log it as an Artifact
- Log test data prediction results as an Artifact in Comet
- Isolate “difficult” samples in the test dataset
- Look at these examples and identify next steps
Let’s get started!
Data Preparation and Preprocessing
The first thing we’re going to do is download the raw data, create an Artifact to track it, and the log the Artifact to Comet.
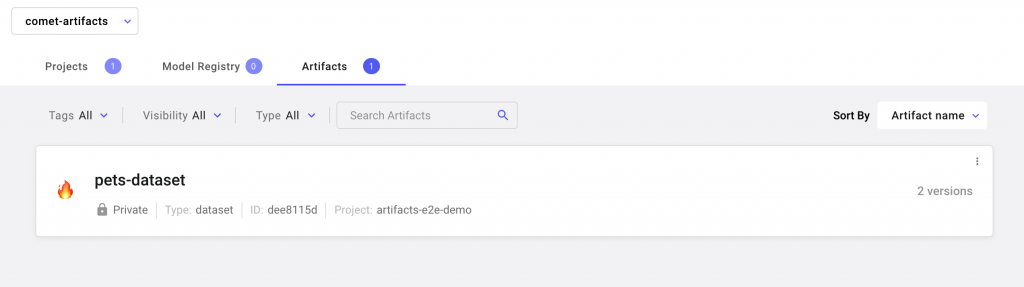
Artifacts are available across your Workspace
Artifacts are available across your workspace. This means that you can reuse the data across your projects and experiments.
Let’s take a look at the raw data that we uploaded:
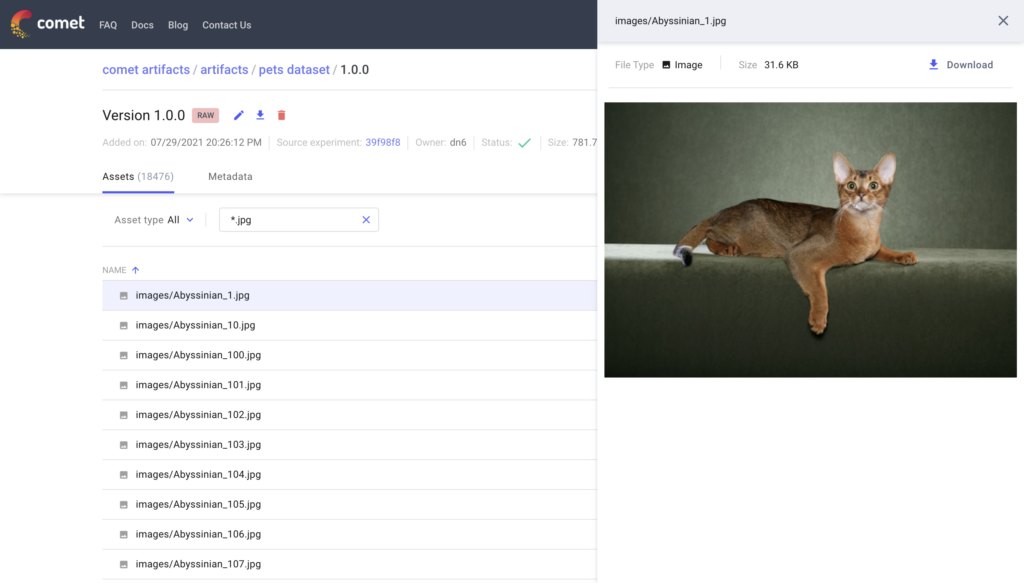
You can search and preview assets within an Artifact right in the UI! An Artifact will provide information about the Experiment that created it, and can also preserve the directory structure of your data so that it is organized exactly as you expect it to be on your local machine. Artifacts also support previews for images, audio, text, JSON and CSV files. You also have the option to store metadata about the Artifact as a set of key value pairs.
Let’s apply some simple preprocessing to our data and update the Artifact version for training.
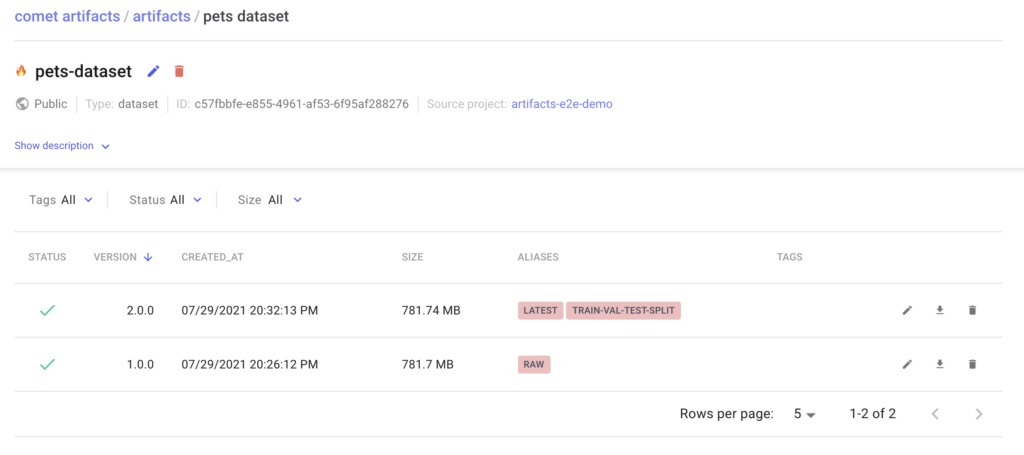
When updating an Artifact, the version is automatically incremented. You can reference Artifacts either through the version number or through a user provided alias. In our example we will use the alias “train-val-test-split” to reference this updated Artifact.
Model Training
Now that we have the data prepared and logged, let’s move on to training our model. We’ll run a sweep of a few hyperparameters and log the resulting models to a single Artifact.
Our training job will download the Artifact and train a model based on the provided set of hyperparameters. You can track what Artifacts were produced and consumed by an experiment in the “Assets and Artifacts” tab in the Experiment View.
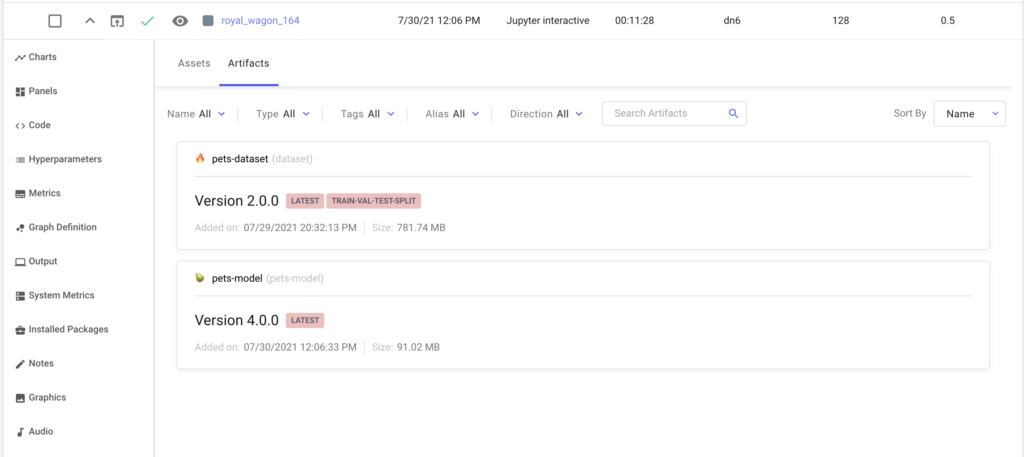
Tracking Artifacts produced and consumed by an Experiment
After training each configuration, lets log the model binary as an Artifact version. Since each version tracks the experiment that produced it, we can easily trace back our models to their hyperparameters.
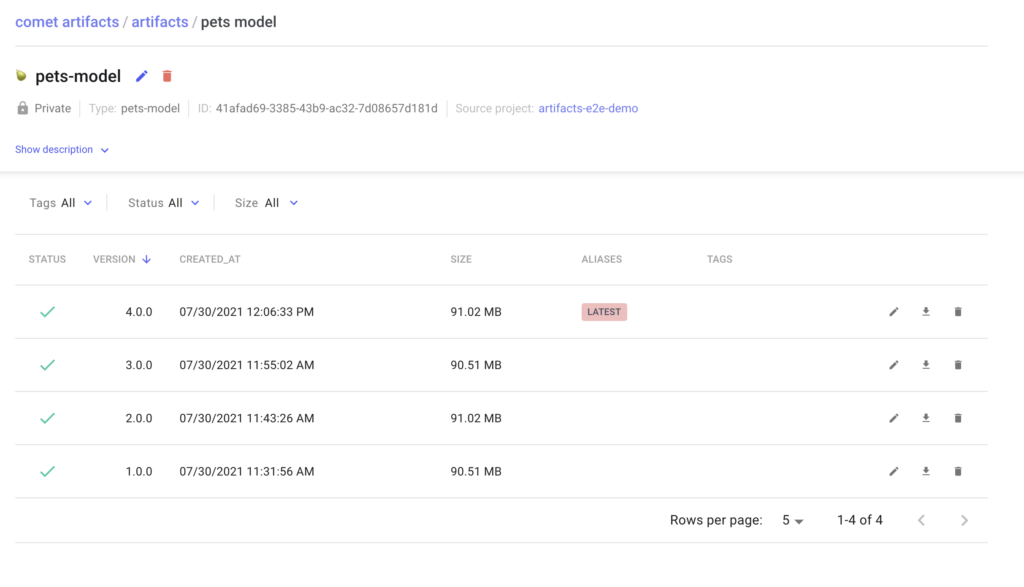
Logging Multiple Versions of a Model as an Artifact
Model Testing
So far, so good. For this example, let’s evaluate these models against our test dataset. In addition to tracking the evaluation metrics for these models, let’s also log the actual predictions as an Artifact. The Artifact version numbers for these predictions will follow that of the models used to make them.
Since we’ve logged the predictions, we can now analyze them and gather insights about our modeling approach.
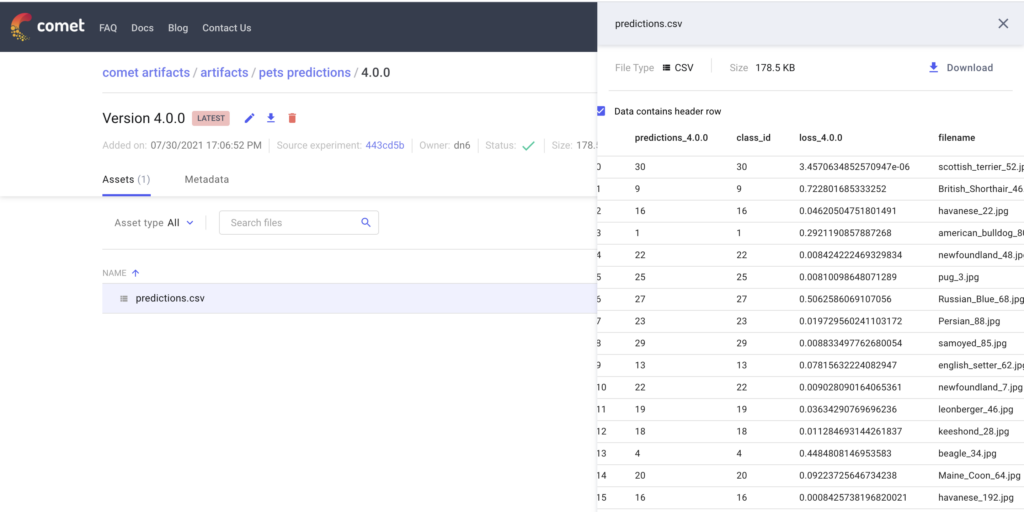
Isolating “Difficult” Data
Let’s isolate the examples in the test dataset that all of our models are having difficulty with. To do this we will
- Sort the top 100 worst predictions from each model based on the per example loss
- Find the common examples across models within these top 100 images
We can now conduct further analysis on these examples. Let’s start by just looking at the samples.

Common themes in this data are the orientation of the animals in the images, the variation in color amongst the same breed, and blurriness in the images. There are several things we could do to address these issues including increasing the number of layers needed to learn varied representations within the same breed, apply a random rotations and blurring to images so that the network can learn to deal with these types of images better.
Conclusion
In this post we presented a guide on how to use Comet Artifacts to debug performance issues in an image classification model for Pet Cam. Using Artifacts we were able to break up our debugging process into discrete steps and log versions of our datasets, models and their respective predictions.
Artifacts allow us to reuse this data across all parts of the experimentation pipeline while tracking the experiments that consume and produce them.
We can now easily write operations that leverage this data and gather insights from any stage of the experimentation pipeline. In our Pet Cam use case, the examples we isolated allow us to make further decisions about what to do to improve our model while tracking our entire experimentation process.
