Observability for AWS Bedrock with Opik
AWS Bedrock is a fully managed service that provides access to high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API.
This guide explains how to integrate Opik with the Bedrock Python SDK, supporting both the Converse API and the Invoke Model API. By using the track_bedrock method provided by Opik, you can easily track and evaluate your Bedrock API calls within your Opik projects as Opik will automatically log the input prompt, model used, token usage, and response generated.
Account Setup
Comet provides a hosted version of the Opik platform, simply create an account and grab your API Key.
You can also run the Opik platform locally, see the installation guide for more information.
Getting Started
Installation
To start tracking your Bedrock LLM calls, you’ll need to have both the opik and boto3 packages. You can install them using pip:
Configuring Opik
Configure the Opik Python SDK for your deployment type. See the Python SDK Configuration guide for detailed instructions on:
- CLI configuration:
opik configure - Code configuration:
opik.configure() - Self-hosted vs Cloud vs Enterprise setup
- Configuration files and environment variables
Configuring Bedrock
In order to configure Bedrock, you will need to have:
- Your AWS Credentials configured for boto, see the following documentation page for how to set them up.
- Access to the model you are planning to use, see the following documentation page how to do so.
You can request access to models in the AWS Bedrock console.
Once you have these, you can create your boto3 client:
Logging LLM calls
Opik supports both AWS Bedrock APIs: the Converse API (unified interface) and the Invoke Model API (model-specific formats). To log LLM calls to Opik, wrap your boto3 client with track_bedrock:
Despite the Invoke Model API using different input/output formats for each model provider, Opik automatically handles format detection and cost tracking for all supported models, providing unified observability across different model formats.
Converse API (Unified Interface)
The Converse API provides a unified interface across all supported models:
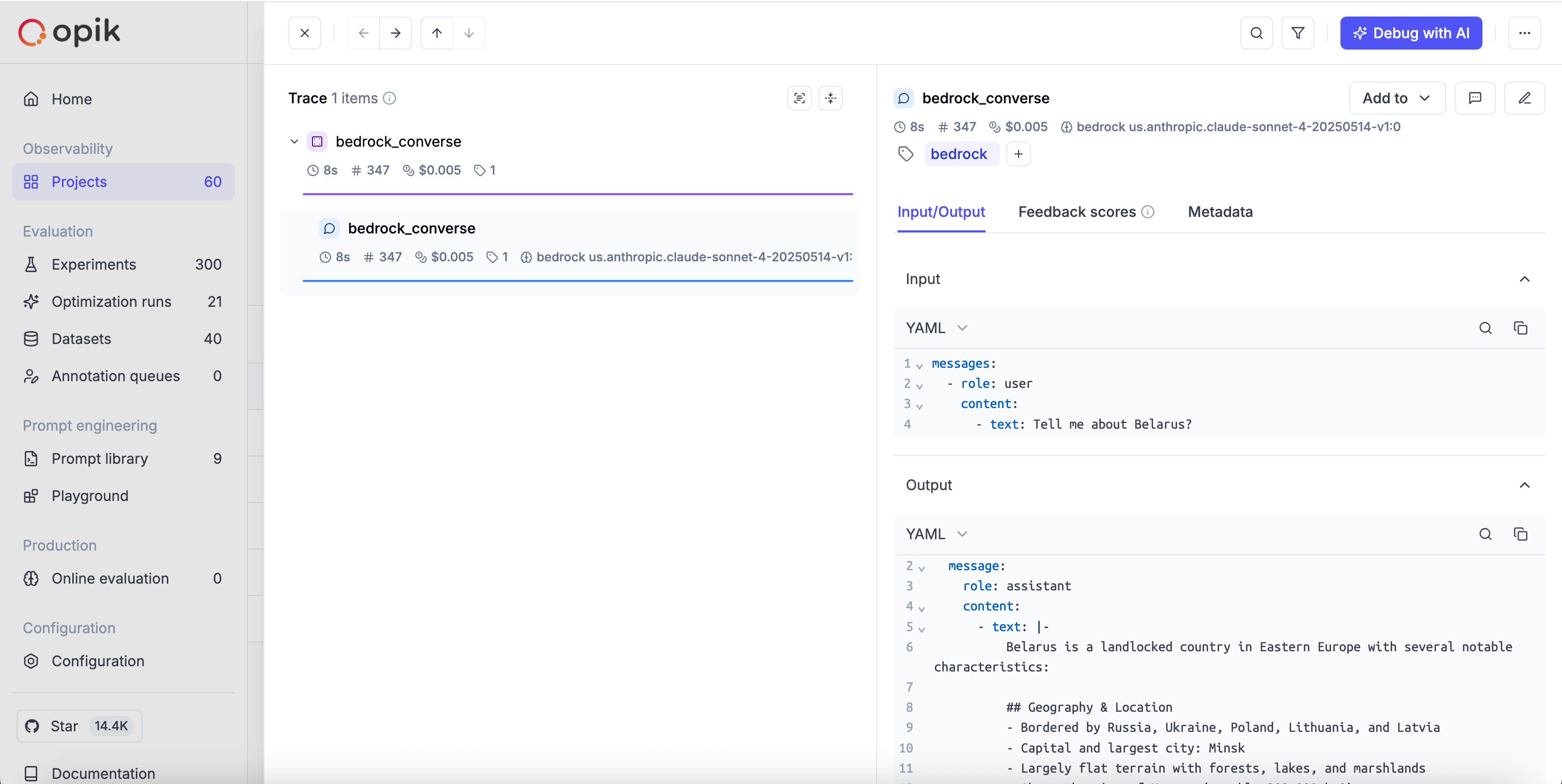
Invoke Model API (Model-Specific Formats)
The Invoke Model API uses model-specific request and response formats. Here are examples for different providers:
Anthropic Claude
Amazon Nova
Meta Llama
Mistral AI
Streaming API
Both Bedrock APIs support streaming responses, which is useful for real-time applications. Opik automatically tracks streaming calls for both APIs.
Converse Stream API
The converse_stream method provides streaming with the unified interface:
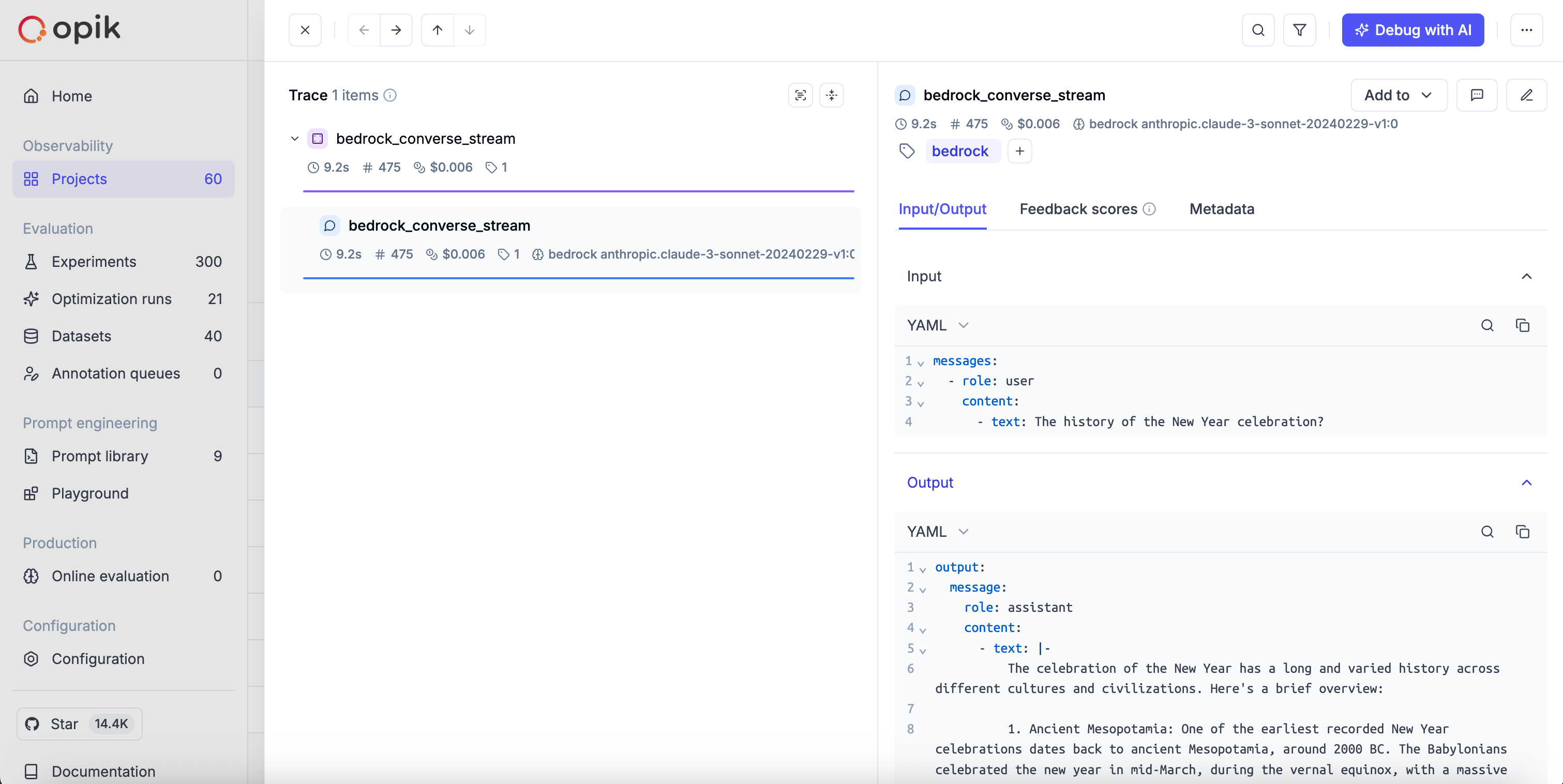
Invoke Model Stream API
The invoke_model_with_response_stream method supports streaming with model-specific formats:
Anthropic Claude
Amazon Nova
Meta Llama
Mistral AI
Advanced Usage
Using with the @track decorator
If you have multiple steps in your LLM pipeline, you can use the @track decorator to log the traces for each step. If Bedrock is called within one of these steps, the LLM call will be associated with that corresponding step:
The trace can now be viewed in the UI with hierarchical spans showing the relationship between different steps:
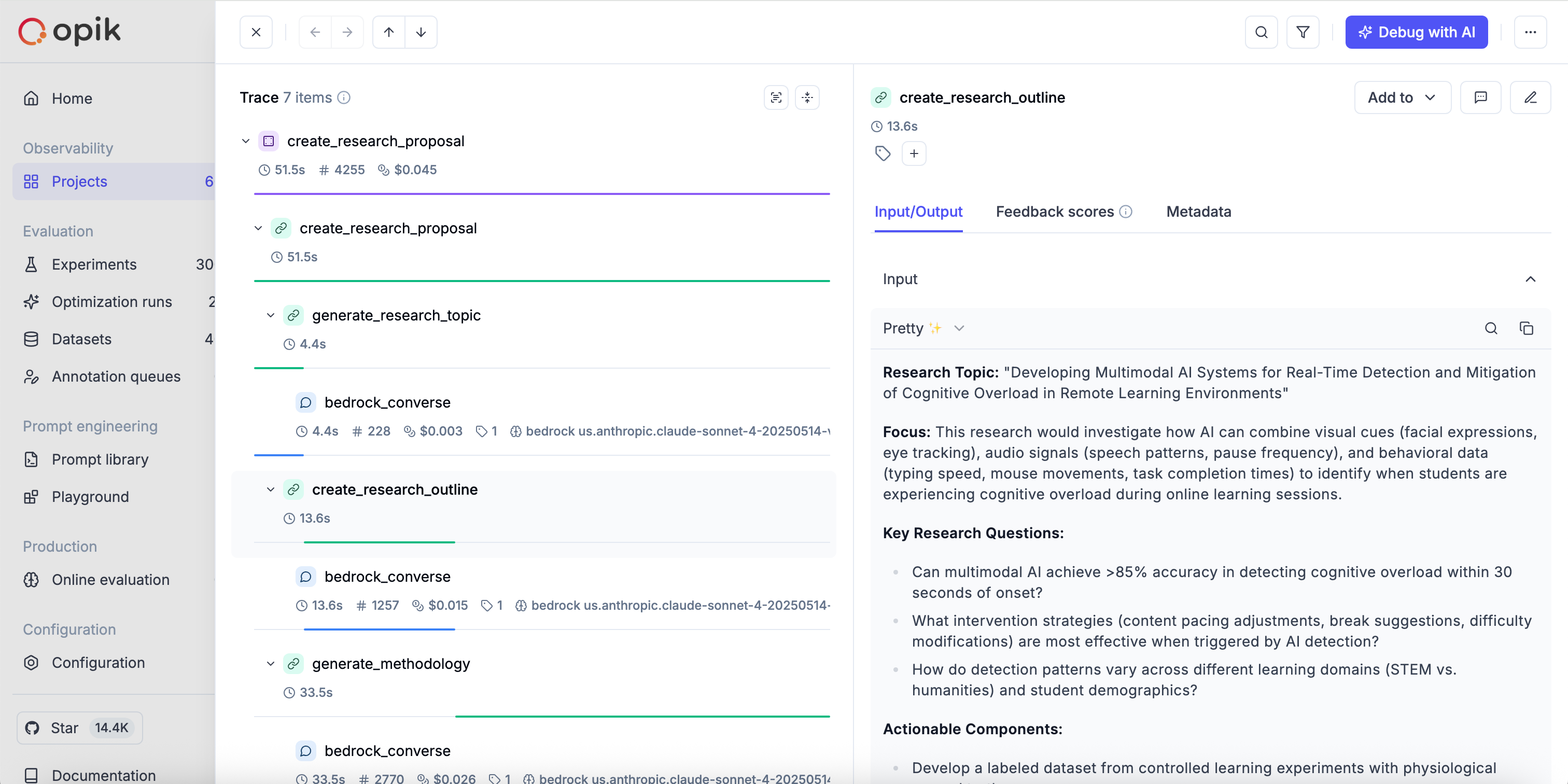
Cost Tracking
The track_bedrock wrapper automatically tracks token usage and cost for all supported AWS Bedrock models, regardless of whether you use the Converse API or the Invoke Model API.
Despite the different input/output formats between the models accessed via the InvokeModel API (Anthropic, Amazon, Meta, Mistral), Opik automatically detects the response format and extracts unified cost and usage information for all models. So even if you can’t use the unified Converse API, you can still have the main tracing benefits by using our integration.
Cost information is automatically captured and displayed in the Opik UI, including:
- Token usage details
- Cost per request based on Bedrock pricing
- Total trace cost
View the complete list of supported models and providers on the Supported Models page.