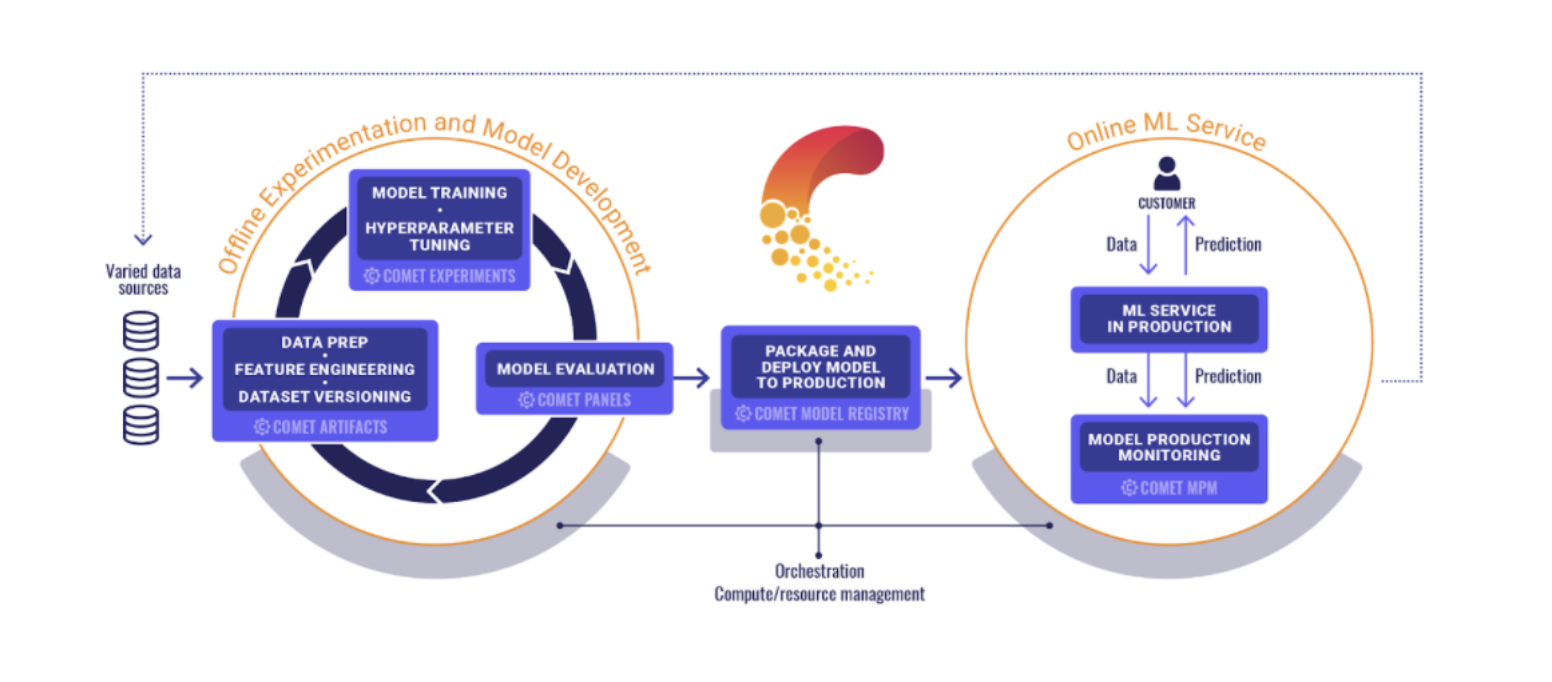
Why is Model Evaluation Important in Machine Learning?
Have you ever built a fully tuned model only for it to fall short of its expectations after deployment? In machine learning, models are only as useful as their predictive power’s quality or how helpful they are in solving a real-world problem. For example, you’ve built a high-performing model during training time, but it made random predictions after deploying it to production. Deploying such a model can jeopardize the reliability of the system or application it is used on, rendering it useless. It’s essential to use model evaluation so your ML models provide trustworthy and reliable predictions for their respective use cases.
While training a model is a crucial step in the machine learning lifecycle, it is not enough. That’s when model evaluation comes in. It is one of the core tasks in a machine learning workflow that helps models improve their predictive power and eventually succeed in the production environment.
What is Model Evaluation in Machine Learning?
Model evaluation is the process of quantifying an ML model’s performance to find the best-performing one that fits the given problem. Evaluating models is crucial to ensure that a model works optimally and correctly when deployed in production. There are two methods to evaluate a model’s performance — holdout and cross-validation. After determining the method, we need to define metrics to evaluate the model’s performance.
There are different evaluation metrics, but the most common ones are accuracy, precision, error rate, recall, confusion matrix, and F1-score. A best practice for model evaluation is to test a model using different metrics to better understand the model’s suitability for the problem it’s trying to solve.
The Importance of Model Evaluation in Machine Learning
1. Determines the Best-Performing Models
ML practitioners can use different algorithms when building a model. However, not all of them apply to the given problem. This is where model evaluation in machine learning comes in. Model evaluation finds the best model that represents the data and determines how well the chosen model will work in the future. To do this, we start by defining evaluation metrics. Evaluation metrics help us assess a model’s performance and understand its strengths and weaknesses. From there, we can compare the performance of each model and choose one that best fits the problem.
2. Increased Accuracy
After training your model, how do you ensure it will create accurate predictions? The most popular metric in model evaluation is classification accuracy. It measures the model’s accuracy by dividing the number of correct predictions by the total number of predictions made. Using this metric also makes it easy for ML practitioners to compare different models because you only need to look at one number.
If the accuracy is high, we can say that the model is accurate. If the accuracy is low, it shows us that the model has poor predictive power or is not the best model to use for the problem. In that way, ML practitioners know they need to improve the model to increase its accuracy. However, it’s not always best to rely on the accuracy metric alone. Evaluate your model using other metrics as well.
3. Prevents Overfitting
Overfitting is one of the most significant causes of a model’s poor performance. It occurs when a model starts to memorize the training data instead of generalizing it to new or unseen data. Let’s say we trained a model that predicted a student could land a job interview based on their resume. Using the given training dataset, the model predicted a 98% of accuracy. Now, we ran the model on new and “unseen” data but only got 40% accuracy. This means that the model failed to generalize well to new data.
If we had deployed this model in the real world without evaluating it, it would have ended up being a useless model. We can’t really know how our model will perform on new data until we test it. By evaluating our model in the development stage, we could have detected an overfitting problem early on and applied techniques to prevent it.
4. Helps Achieve Organizational Goals
Organizations implement machine learning to solve customer problems, provide better offerings, streamline internal processes, avoid risks, and more. Model evaluation determines if a model best fits the problem, helping organizations achieve business goals. It helps us ensure that the model is useful, accurate, and reliable when deployed in the real world.
5. Prevents Risks
Any mistake or incorrect predictions in sensitive industries like healthcare can lead to fatalities. Evaluating a model in the development stage helps ML teams understand if it needs to be improved to be helpful in the real world. When done right, model evaluation in machine learning can mean the difference between saving a life and putting one in danger. That’s why it is so crucial.
Build Better Models With Comet
Simply training a model with an algorithm doesn’t ensure that the model fully captures the underlying concepts in the training data. Failing to test a model’s performance can result in the deployment of an underperforming model, leading to inaccurate predictions. Model evaluation is an essential task that machine learning teams shouldn’t skip in the model development process.
Use Comet for free to evaluate your models and compare performance. Comet’s machine learning platform integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring. Try Comet today for free.
Related Articles