Integrate with Kubeflow¶
Comet integrates with Kubeflow.
Kubeflow is an open-source machine learning platform that enables using machine learning pipelines to orchestrate complicated workflows running on Kubernetes.
Visualize Kubeflow pipelines¶
The Comet-Kubeflow integration allows you to track both individual tasks and the state of the pipeline as a whole. The state of the pipeline can be visualized using the Kubeflow Panel available in the featured tab.
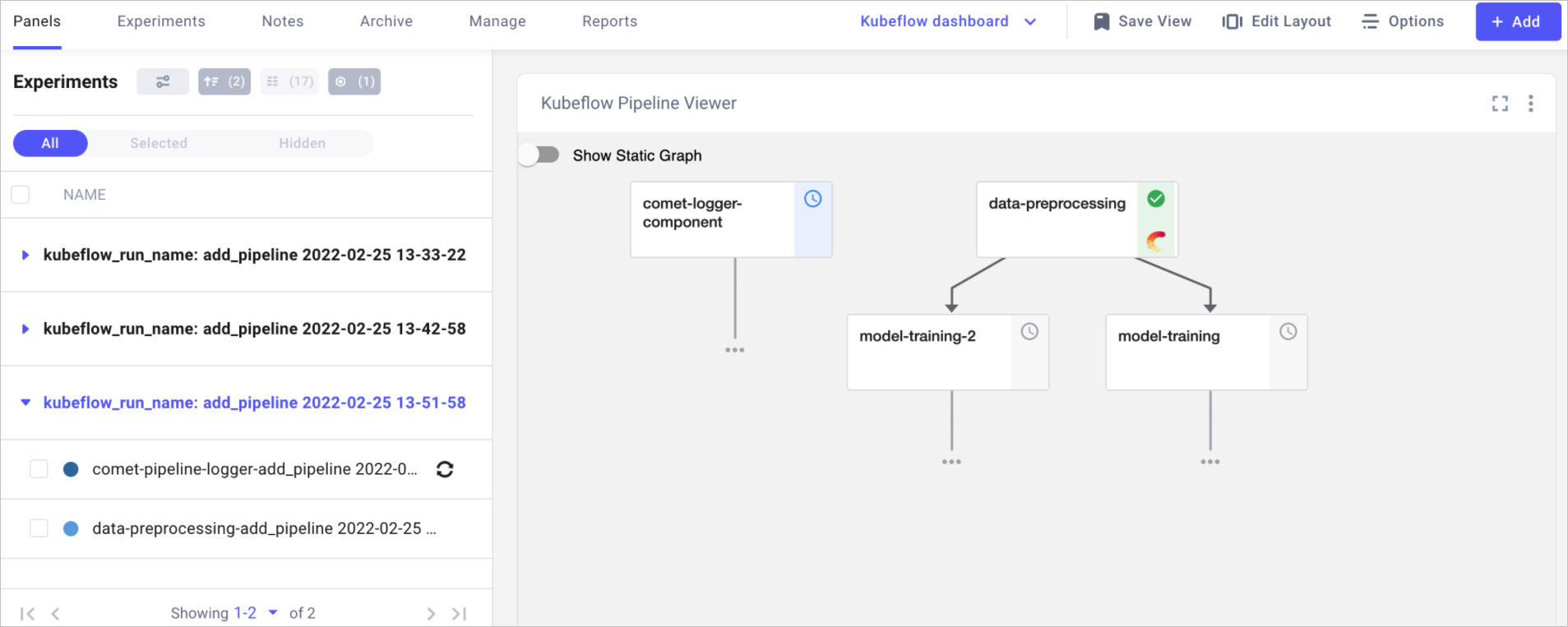
You can recreate the view above by performing these steps:
- Grouping experiments by
kubeflow_run_name. - Adding the Kubeflow panel available in the featured tab.
- Saving the view as
Kubeflow dashboard.
The Kubeflow panel can be used to either visualize the latest state of the DAG or the static graph similar to what is available in the Kubeflow UI. In addition all tasks that have the Comet logo are also tracked in Comet and can be accessed by clicking on the task.
Integration overview¶
The Kubeflow integration is performed in two steps:
- Adding a Comet logger component to track the state of the pipeline.
- Adding Comet to each individual tasks that you would like track as a Comet experiment.
Log the state of a pipeline¶
The Kubeflow integration relies on a component that runs in parallel to the rest of the pipeline. The comet_logger_component logs the state of the pipeline as whole and reports it back to the Comet UI allowing you to track the pipeline progress as a whole. This component can be used like this:
import comet_ml.integration.kubeflow
import kfp.dsl as dsl
@dsl.pipeline(name='ML training pipeline')
def ml_training_pipeline():
# Add the Comet logger component
workflow_uid = "{{workflow.uid}}"
comet_ml.integrations.kubeflow.comet_logger_component(
workflow_uid=workflow_uid,
api_key="<>",
workspace="<>",
project_name="<>")
# Rest of the training pipeline
The string "{{workflow.uid}}"is a placeholder that is replaced at runtime by Kubeflow. You do not need to update it before running the pipeline.
The Comet logger component can also be configured using environment variables, in which case you will not need to specify the api_key, workspace or project_name arguments.
Log the state of each task¶
In addition to the component, you will need to initialize the Kubeflow task logger within each task of the pipeline that you wish to run. This can be done by creating an experiment within each task and using the initialize_comet_logger function:
def my_component() -> None:
import comet_ml.integration.kubeflow
experiment = comet_ml.start(
api_key="<Your API Key>", project_name="<Your Project Name>"
)
workflow_uid = "{{workflow.uid}}"
pod_name = "{{pod_name}}"
comet_ml.integration.kubeflow.initialize_comet_logger(
experiment, workflow_uid, pod_name
)
# Rest of the task code
The strings "{{workflow.uid}}", "{{pod_name}}" are placeholders that are replaced at runtime by Kubeflow. You do not need to update them before running the pipeline.
Note
There are alternatives to setting the API key programatically. See more here.